机器推理 知识推理概览:七大自然语言处理的任务最新方法与进展
原创: 段楠 唐都钰 周明
编者按:自然语言处理的发展进化带来了新的热潮与研究问题,研究者们在许多不同的任务中推动机器推理(Machine Reasoning)能力的提升。基于一系列领先的科研成果,微软亚洲研究院自然语言计算组将陆续推出一组文章,介绍机器推理在常识问答、事实检测、自然语言推理、视觉常识推理、视觉问答、文档级问答、多轮语义分析和问答等任务上的最新方法和进展。
从规则方法、统计方法到目前的深度学习方法,自然语言处理(NLP)研究一直处于不断发展和进化的状态之中,并在过去五年取得了令人瞩目的成果。对于一个拥有充分标注语料的 NLP 任务(例如机器翻译和自动问答),现有的深度学习方法能够很好地对输入和输出之间的关系进行建模,并在分布相同或类似的测试数据上取得令人满意的效果。然而,一旦测试数据所涉及的知识和领域超出训练数据的范畴之外,大多数模型的效果都会一落千丈。这一现象其实不难理解:人类在从小到大的成长过程中,已经通过各式各样的学习过程掌握了大量的通用知识(例如数学知识、物理知识、世界知识、常识知识等)。这些知识能够帮助人类在学习新技能或遇到新问题时进行推理并举一反三。然而,绝大多数 NLP 模型都不具备这样的知识模型,因此就不能很好地理解和解决新的问题。
大规模知识图谱(例如 Satori 和 WikiData )的出现使得构建基于知识的 NLP 模型成为可能,语义分析(Semantic Parsing)和知识图谱问答(Knowledge-based QA)研究也藉此成为最热门的两个 NLP 课题。然而,由于现有知识图谱对人类知识的覆盖度依然非常有限,基于知识图谱的 NLP 模型只能精准理解和处理很少一部分自然语言问题和任务,而对剩余部分无能为力。
最近两年,预训练模型(例如GPT、BERT和XLNet)的出现极大地提高了几乎所有自然语言处理任务的最优水平。通过在海量文本上进行基于语言模型的预训练以及在下游任务上对模型参数进行微调,预训练模型能够很好地将从训练数据中学习到的“通用知识”迁移和传递到下游任务中。关于这种“通用领域预训练+特定任务微调”的新范式,整个 NLP 社区也展开了热烈的讨论:预训练模型是否真的学到了 “知识”?它是否能够替代已有的符号化知识图谱?它是否具备推理能力?
带着对上述若干问题的好奇,微软亚洲研究院自然语言计算组的研究员开展了一系列关于机器推理的研究。作为引言,本文将对什么是机器推理给出解释,并简要说明已有 NLP 方法与机器推理的关系。接下来,我们会陆续推出一系列文章,介绍机器推理在常识问答、事实检测、自然语言推理、视觉常识推理、视觉问答、文档级问答、多轮语义分析和问答等任务上的最新方法和进展。
机器推理(Machine Reasoning),是指基于已有知识对未见问题进行理解和推断,并得出问题对应答案的过程[1]。根据该定义,机器推理涉及4个主要问题:(1)如何对输入进行理解和表示?(2)如何定义知识?(3)如何抽取和表示与输入相关的知识?(4)基于对输入及其相关知识的理解,如何推断出输入对应的输出?下图给出机器推理的整体框架。
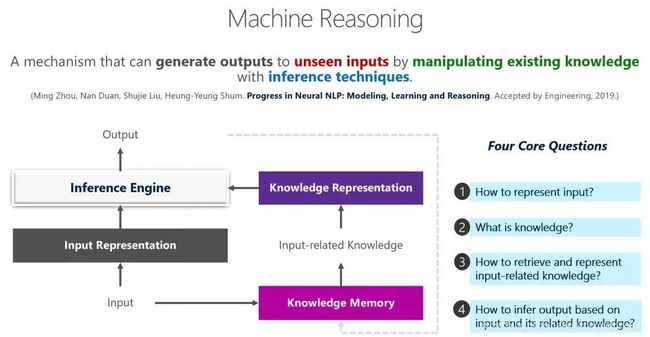
图1:机器推理整体框架
对于输入的理解和表示,NLP 领域已经积累了大量的研究,包括词袋(Bag-of-Word)模型、句法分析(Syntactic Parsing)模型、词嵌入(Word Embedding)模型和句子嵌入(Sentence Embedding)模型等。对于知识的定义,不仅开放/特定领域的知识图谱和常识图谱属于“知识”的范畴,目前被广泛研究和使用的预训练模型同样可以看做是知识。这是因为预训练模型的本质就是将每个单词在海量文本中的上下文存储在模型当中。Facebook 的工作[2]也从实验角度证明了现有预训练模型对知识图谱和常识知识的覆盖。对于知识的提取和表示,基于知识图谱的模型通常基于实体链接的结果从知识图谱中找到与输入相关的知识,并采用知识嵌入(Knowledge Embedding)的方式对其进行编码和建模。相比之下,基于预训练模型的知识提取则对应了使用预训练模型对输入文本进行编码的过程。对于基于输入及其相关知识进行推断,不同的任务通常采用不同的推断算法。例如,在语义分析任务中,推断过程对应了生成语义表示的算法。在基于预训练模型的微调方法中,推断过程对应了已有预训练模型之上的任务相关层。
上述描述只是对机器推理的一个粗浅解释。在接下来的一系列文章中,我们将分别介绍上述机器推理框架在若干最新推理任务上的具体实现方法和实验效果,包括:
机器推理系列之一:基于推理的常识问答
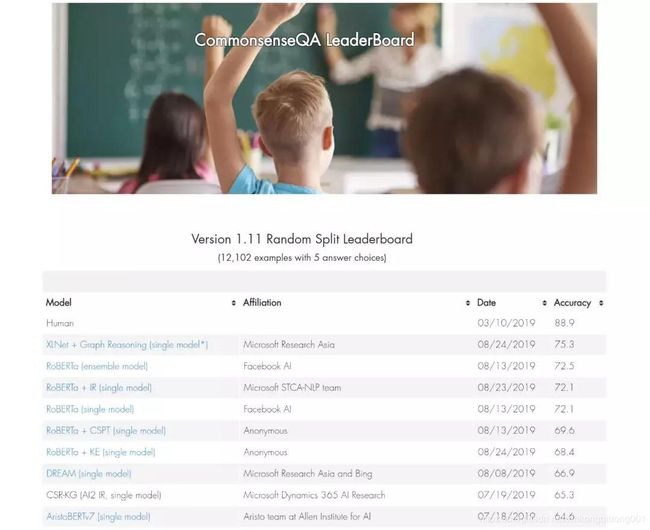
图2:我们提出的推理方法(XLNet+Graph Reasoning)在以色列特拉维夫大学常识问答任务 CommonsenseQA上取得了目前 state-of-the-art 的结果[3]。
(https://www.tau-nlp.org/csqa-leaderboard)
机器推理系列之二:基于推理的事实检测
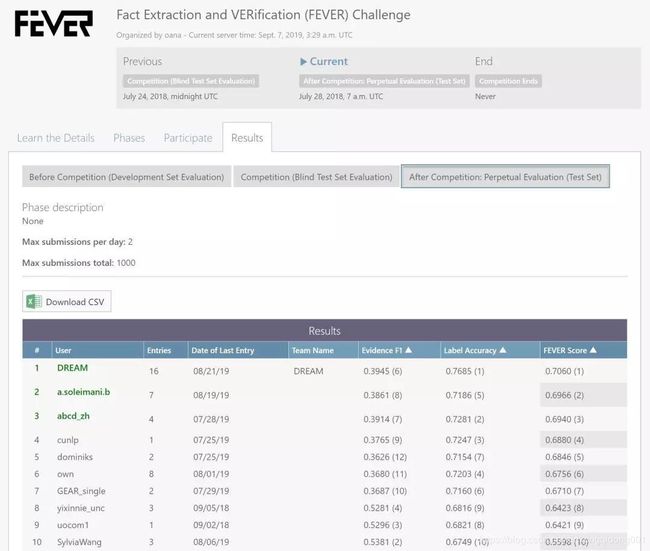
图3:我们提出的推理方法(DREAM)在 Amazon 剑桥研究院事实检测任务FEVER上取得了目前 state-of-the-art 的结果[4]。
(https://competitions.codalab.org/competitions/18814#results)
机器推理系列之三:基于推理的跨语言自然语言推理

图4:我们提出的跨语言预训练模型(Unicoder)在纽约大学跨语言自然语言推理任务XNLI上取得了目前 state-of-the-art 的结果[5]。
(https://arxiv.org/pdf/1909.00964.pdf)
机器推理系列之四:基于推理的视觉常识推理

图5:我们提出的跨模态预训练模型(Unicoder-VL)在华盛顿大学视觉常识推理任务 VCR 上取得了目前 state-of-the-art 的结果[6]。
(https://visualcommonsense.com/leaderboard/)
机器推理系列之五:基于推理的视觉问答
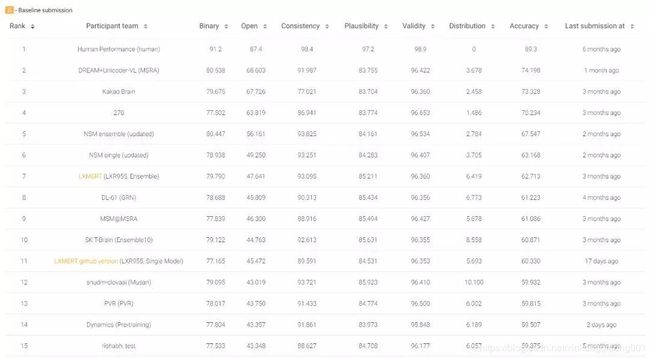
图6:我们提出的推理方法(DREAM+Unicoder-VL)在斯坦福大学视觉推理和问答任务 GQA 上取得了目前 state-of-the-art 的结果[7]。
(https://evalai.cloudcv.org/web/challenges/challenge-page/225/leaderboard/733)
机器推理系列之六:基于推理的文档级问答
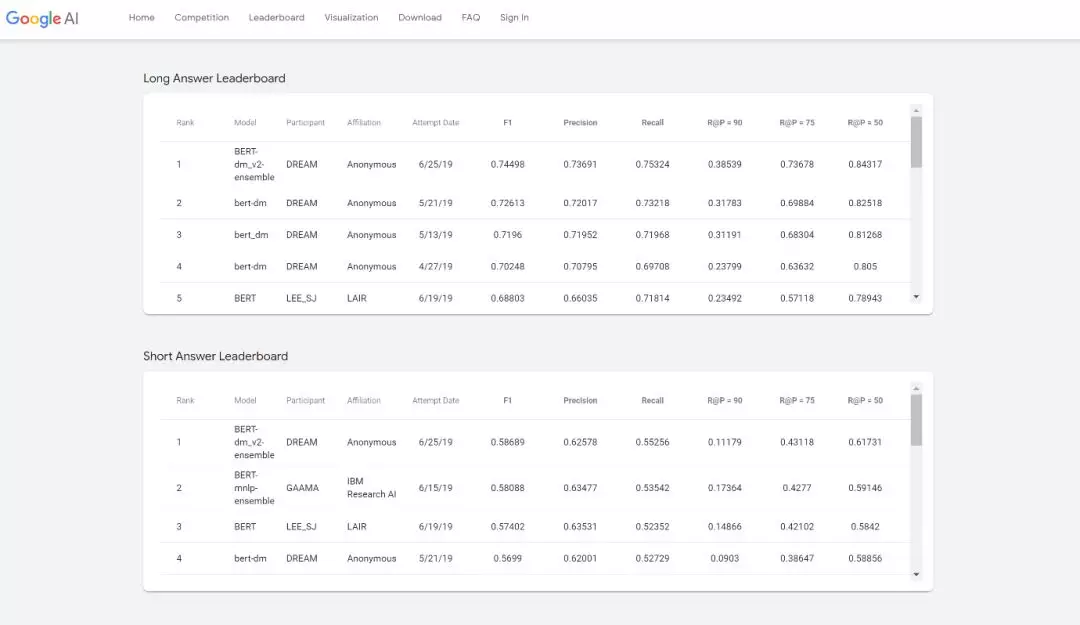
图7:我们提出的基于BERT的文档建模方法(BERT-DM)在谷歌文档级问答任务 NQ 上取得了目前 state-of-the-art 的结果[8]。
(https://ai.google.com/research/NaturalQuestions)
机器推理系列之七:基于推理的多轮语义分析和问答。
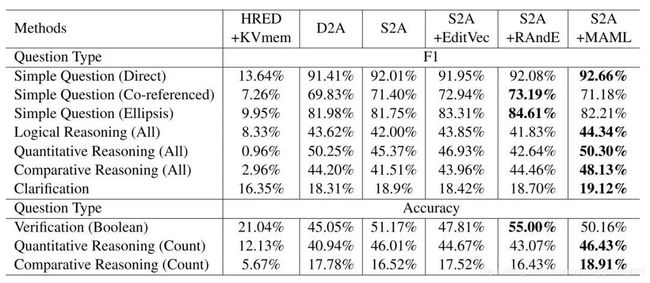
图8:我们提出的多轮语义分析和问答方法(Seq2Action)在IBM研究院多轮复杂问答任务 CSQA 上取得了目前 state-of-the-art 的结果[9][10]。