【Android自助餐】Handler消息机制完全解析(二)MessageQueue的队列管理
Android自助餐Handler消息机制完全解析(二)MessageQueue的队列管理
- Android自助餐Handler消息机制完全解析二MessageQueue的队列管理
- 添加到消息队列enqueueMessage
- 从队列取出消息next
- 第一段
- 第三段
- 第二段
- 从队列移除消息removeMessages
- 第一个while
- 第二个while
关于这个队列先说明一点,该队列的实现既非Collection的子类,亦非Map的子类,而是Message本身。因为Message本身就是链表节点(见Message中obtain()与recycle()的来龙去脉)。
队列中的Message mMessages;成员即为队列,同时该字段直接指向队列中下一个需要处理的消息。
添加到消息队列enqueueMessage()
要将message添加到队列除了提供message之外,还需提供消息触发时间when。
如果当前队列为空则直接mMessage=message即可。否则就需要逐个对比队列中每个message的when和新消息的when来确定新消息在队列中的位置。
先给出核心源码(有删减)
Message p = mMessages;
if (p == null || when == 0 || when < p.when) {
msg.next = p;
mMessages = msg;
} else {
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
}
msg.next = p;
prev.next = msg;
}
if (needWake) {
nativeWake(mPtr);
}先看下新消息需要放到队头的情况:p == null || when == 0 || when < p.when。即队列为空,或者新消息需要立即处理,或者新消息处理的事件比队头消息更早被处理。这时只要让新消息的next指向当前队头,让mMessages指向新消息即可完成插入操作。
除了上述三种情况就需要遍历队列来确定新消息位置了,下面结合示意图来说明。
假设当前消息队列如下

开始遍历:p向队尾移,引入prev指向p上一个元素

假设此时p所指消息的when比新消息晚,则新消息位置在prev与p中间

最后便是调用native方法来唤醒(Linux的epoll,有兴趣的自行百度)。
从队列取出消息next()
这部分内容有点高能,请根据个人BPU(BrainProcessUnit)酌情理解。
首先这个方法需要返回Message,那么我们现在来看看哪里有return。(共三段,我们最后看第二段。)
第一段
final long ptr = mPtr;
if (ptr == 0) {
return null;
}如果mPtr为0则返回null。那么mPtr是什么?值为0又意味着什么?在MessageQueue构造方法中调用了native方法并返回了mPtrmPtr = nativeInit();;在dispose()方法中将其值置0mPtr = 0;并且调用了nativeDestroy()。而dispose()方法又在finalize()中被调用。另外每次mPtr的使用都调用了native的方法,其本身又是long类型,因此推断它对应的是C/C++的指针。因此可以确定,mPtr为一个内存地址,当其为0说明消息队列被释放了。这样就很容易理解为什么mPtr==0的时候返回null了。
第三段
你没有看错,第二段在后面
if (mQuitting) {
dispose();
return null;
}这里的意思也很明显,当这个消息队列退出的时候,返回空。而且在返回前调用了dispose()方法,显然这意味着该消息队列将被释放。
第二段
这部分涉及到的代码基本上就是这个next()方法本身了,但可以肯定的是这里的返回语句是return msg;。同时从enqueueMessage()方法可以看出来,在这个队列中取到的message对象不可能为空,因此这里的返回绝对不为空。
如此一来就可以得出一个结论:如果next()方法为空说明这个消息队列正在退出或将被释放回收。
继续来看这个next(),这个代码有点长,所以先做个减法。
第一个要减的就是pendingIdleHandlerCount,这个局部变量初始为-1,后面被赋值mIdleHandlers.size();。这里的mIdleHandlers初始为new ArrayList,在addIdleHander()方法中增加元素,在removeIdleHander()方法中移除元素。而我们所用的Handeler并未实现IdleHandler接口,因此在next()方法中pendingIdleHandlerCount的值要么为0,要么为-1,因此可以看出与该变量相关的部分代码运行情况是确定的,好的,把不影响循环控制的代码减掉。
第二个要减的是Binder.flushPendingCommands()这个代码看源码说明:
Flush any Binder commands pending in the current thread to the kernel driver. This can be useful to call before performing an operation that may block for a long time, to ensure that any pending object references have been released in order to prevent the process from holding on to objects longer than it needs to.
这段话啥意不懂也没关系,这里只需要知道:Binder.flushPendingCommands()方法被调用说明后面的代码可能会引起线程阻塞。然后把这段减掉。
第三个要减的是一个log语句if (DEBUG) Log.v(TAG, "Returning message: " + msg);
第四个要减的是上面提到的“第一段”返回null的语句,但是“第三段”得留着。
最后再把注释干掉给上代码:
Message next() {
int nextPollTimeoutMillis = 0;
for (;;) {
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
msg.markInUse();
return msg;
}
} else {
nextPollTimeoutMillis = -1;
}
if (mQuitting) {
dispose();
return null;
}
if (pendingIdleHandlerCount <= 0) {//上面分析过该变量要么为0要么为-1
mBlocked = true;
continue;
}
}
nextPollTimeoutMillis = 0;
}
}虽然还是很长,但也不能再减了。大致思路如下:先获取第一个同步的message。如果它的when不晚与当前时间,就返回这个message;否则计算当前时间到它的when还有多久并保存到nextPollTimeMills中,然后调用nativePollOnce()来延时唤醒(Linux的epoll,有兴趣的自行百度),唤醒之后再照上面那样取message,如此循环。代码中对链表的指针操作占了一定篇幅,其他的逻辑很清楚,就不一句句分析了。
从队列移除消息removeMessages()
该方法有2个重载,除此之外还有removeCallbacksAndMessages()等方法也可以移除消息。但代码段都基本一样,这里以void removeMessages(Handler h, int what, Object object){}方法为例。
该方法完整源码如下
void removeMessages(Handler h, int what, Object object) {
if (h == null) {
return;
}
synchronized (this) {
Message p = mMessages;
// Remove all messages at front.
while (p != null && p.target == h && p.what == what
&& (object == null || p.obj == object)) {
Message n = p.next;
mMessages = n;
p.recycleUnchecked();
p = n;
}
// Remove all messages after front.
while (p != null) {
Message n = p.next;
if (n != null) {
if (n.target == h && n.what == what
&& (object == null || n.obj == object)) {
Message nn = n.next;
n.recycleUnchecked();
p.next = nn;
continue;
}
}
p = n;
}
}
}最开始判断handler是否为空不必多说,然后便是同步代码段,只里面有两个while循环。为什么有两个呢?学过数据结构链表的都知道,链表分两种:带头结点和不带头结点。而这两种链表的遍历方式有所不同:不带头结点的链表中,第一个元素需要单独处理,然后才能将后续部分当做带头结点的链表来使用while循环遍历。可以看出MessageQueue是不带头结点的链表,而且遍历过程中有需要删除节点,因此要特殊处理的不只是第一个元素,而是第一组符合删除条件的元素。有点晕了是吧,不要紧,我们开始斗图。
第一个while
假设需要遍历的消息队列如图所示。

为了让第一个while可以执行,我们假设前3个元素符合移除条件,即前三个Message的targe、what、obj分别与指定的handler、what、object相同。首先第一个元素满足条件进行如下操作:
执行n=p.next;

后移mMessage;
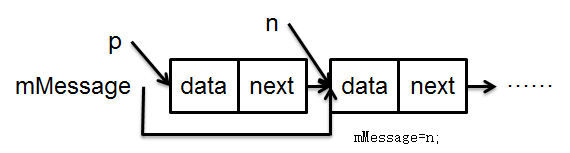
回收p指向的元素,即第一个元素。
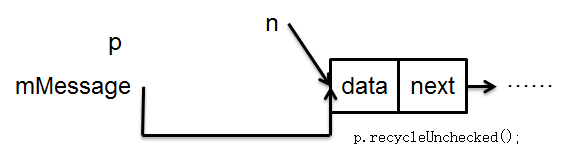
让p指向新的队头。
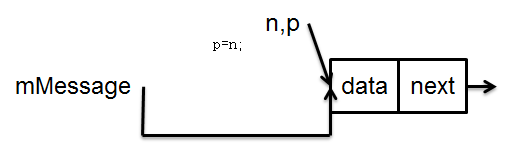
此时又与初始队列状态一样了。先前我们假设队头有三个元素符合移除条件,因此再循环执行上面4图2边后又得到初始状态的队列,此时队头元素不满足移除条件因此while终止,同时新的队列变成了“带头结点的链表”,因此mMessage指向的元素永远不用被判断是否满足移除条件。
第二个while
此时消息队列状态如下:

执行n=p.next;
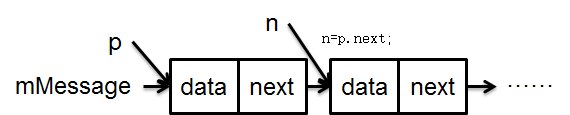
假设n指向的元素不满足移除条件,则只需要将p和n后移,如此也说明,p指向的元素总是已经被判断过不满足移除条件的。这部分逻辑很简单到给图就是看不起读者的智商,现在我们假设n指向的元素满足移除条件,即当前队列如下:

执行nn=n.next;

回收n指向的元素

执行p.next=nn;

这时p之后的队列又是一个带头结点的链表。可以继续while了。