Python数据挖掘基础(二):Numpy
目录
- 1. Numpy的优势
- 2. 数组属性
- 3. 创建数组
- 4. 数组形状与类型变化
- 4. 数组运算
- 4.1 逻辑运算
- 4.2 统计运算
- 4.3 数组间运算
- 4.4 合并分割
1. Numpy的优势
Python已经提供了很多丰富的内置包,我们为什么还要学习NumPy呢?先看一个例子,找寻学习 NumPy 的必要性和重要性。如下:

完成同样的都对元素相加的操作,NumPy比Python快了11倍之多。这就是我们要学好NumPy的一个重要理由,它在处理更大数据量时,处理效率明显快于Python。并且内置的向量化运算和广播机制,使得使用NumPy更加简洁,会少写很多嵌套的for循环,因此代码的可读性大大增强。NumPy计算为什么这么快呢?原因如下:
Python的list是一个通用结构。它能包括任意类型的对象,并且是动态类型。NumPy的ndarray是静态、同质的类型,当ndarray对象被创建时,元素的类型就确定。由于是静态类型,所以ndarray间的加、减、乘、除用C和Fortran实现才成为可能,所以运行起来就会更快。根据官方介绍,底层代码用C语言和Fortran语言实现,实现性能无限接近C的处理效率。

从图中我们看出来NumPy其实在存储数据的时候,数据与数据的地址都是连续的,这样就给我们操作带来了好处,处理速度快。- 支持并行化运算,也叫向量化运算。当然向量是数学当中的概念,我们不过多解释,只需要知道他的优势即可。也就是说
NumPy底层使用BLAS做向量,矩阵运算。numpy的许多函数不仅是用C实现了,还使用了BLAS(一般Windows下link到MKL的,下link到OpenBLAS) 基本上那些BLAS实现在每种操作上都进行了高度优化 例如使用AVX向量指令集,甚至能比你自己用C实现快上许多,更不要说和用Python实现的比
由此可见,NumPy 就非常适合做大规模的数值计算和数据分析。
2. 数组属性
数组属性反映了数组本身固有的信息。
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.flags | 有关阵列内存布局的信息 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组元素的长度(字节) |
| ndarray.nbytes | 数组元素消耗的总字节数 |
示例代码如下:
import numpy as np
# 数组的属性
# 1.创建数组 这里先不用管 后续会详细讲解数组的创建方法
a = np.array([[1,2,3],[4,5,6]])
b = np.array([1,2,3,4])
c = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
# 创建数组的时候指定类型
# dtype更多取值: int complex bool object
# 还可以显示的定义数据位数的类型,如: int64、int16、float128、complex128。
d = np.array([1,2,3,4], dtype=np.float)
# 2.测试数组属性
print(a.shape) # 数组形状 (2, 3): 二维数组
print(b.shape) # (4,) 一维数组: 有4个元素
print(c.shape) # (2, 2, 3): 三维数组
print(a.ndim) # 数组维数 2
print(a.size) # 元素的数量 6
print(a.itemsize) # 每一个元素占的位数(字节) 8
print(a.nbytes) # 总共占的字节数 6*8 ==> 48
print(a.flags) # 阵列内存布局
print(a.dtype) # 数组类型 int64
print(d.dtype) # float64
上述代码执行结果如下:

3. 创建数组
1. 创建0和1的数组 示例代码如下:
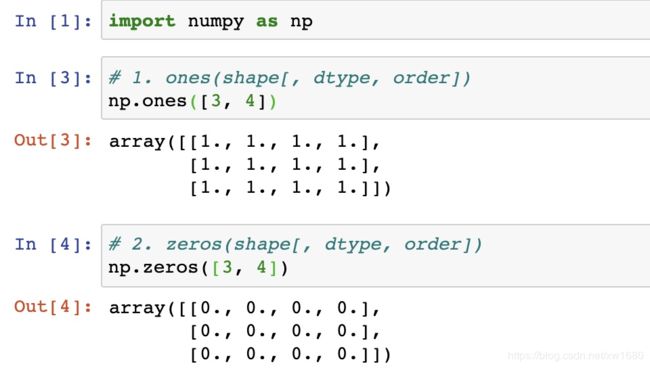
2. 从现有的数据中创建 示例代码如下:
num_list = [[1,2,3], [4,5,6]]
a = np.array(num_list)
a1 = np.array(a) # 创建了一个新的数组
a2 = np.asarray(a) # 还是引用原来的数组
print(a)
print(a1)
print(a2)
a[0] = 10
a, a1, a2
上述代码执行结果如下:

3. 创建固定范围的数组,语法格式如下:
np.linspace(start, stop, num, endpoint, retstep, dtype) 生成等间隔的序列
start:序列的起始值
stop:序列的终止值
num:要生成的等间隔样例数量,默认为50
endpoint:序列中是否包含stop值,默认为True
retstep:如果为True,返回样例,以及连续数字之间的步长
dtype:输出ndarray的数据类型
示例代码如下:
arr = np.linspace(0, 10, 10)
arr
执行结果如图所示:

其它的还有:
- numpy.arange(start,stop, step, dtype) 示例代码如下:
运行结果如图所示:np.arange(1, 10, 2)

- numpy.logspace(start,stop, num, endpoint, base, dtype) 构造一个从
10的-2次方到10的2次方的等比数列,这个等比数列的长度是10个元素,示例代码如下:
运行结果如图所示:np.logspace(-2,2,10)

如果不想是10的次方,也就是想改变基数,那么可以这么写,代码如下:
运行结果如图所示:np.logspace(-2,2,10,base=2)

4. 创建随机数组
np.random 模块生成随机数组,更加方便,示例代码如下:

上面产生的数据是属于一个均匀分布。那么什么是均匀分布呢?在概率论和统计学中,均匀分布也叫矩形分布,它是对称概率分布,在相同长度间隔的分布概率是等可能的。 均匀分布由两个参数a和b定义,它们是数轴上的最小值和最大值,通常缩写为U(a,b)。
正态分布?给定均值/标准差/维度的正态分布,示例代码如下:
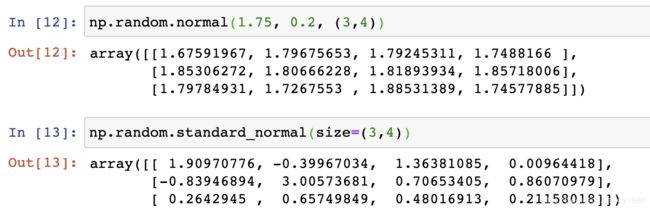
正态分布是一种概率分布。正态分布是具有两个参数μ和σ的连续型随机变量的分布,第一参数μ是服从正态分布的随机变量的均值,第二个参数σ是此随机变量的方差,所以正态分布记作N(μ,σ )。
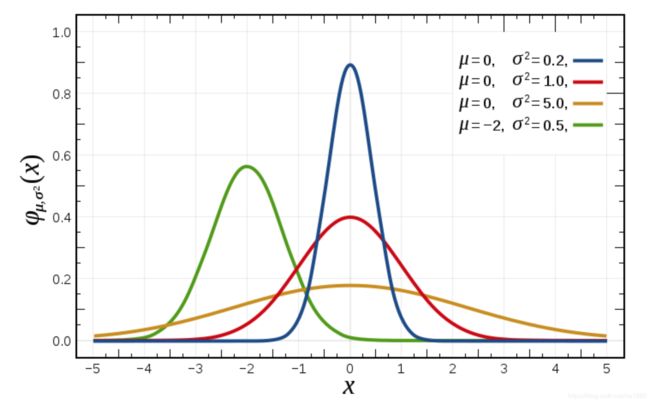
生活、生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。μ决定了其位置,其标准差σ。决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。
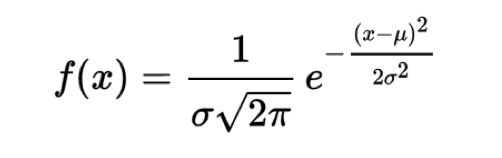
标准差如何来?方差是在概率论和统计方差衡量一组数据时离散程度的度量。
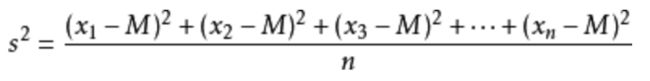
其中M为平均值,n为数据总个数,s为标准差,s^2可以理解一个整体为方差。

通过索引切片等获取数组中的值,一维数组示例代码如下:

二维数组示例代码如下:

三维数组示例代码如下:

4. 数组形状与类型变化
1. ndarray.reshape(shape[, order]) Returns an array containing the same data with a new shape. 示例代码如下:

2. ndarray.resize(new_shape[, refcheck]) Change shape and size of array in-place. 示例代码如下:

3. 修改类型 ndarray.astype(type) 示例代码如下:

4. 修改小数位数 ndarray.round(arr, out) Return a with each element rounded to the given number of decimals. 示例代码如下:

5. ndarray.flatten([order]) Return a copy of the array collapsed into one dimension. 示例代码如下:

6. ndarray.T 数组的转置 将数组的行、列进行互换 示例代码如下:

7. ndarray.tostring([order])或者ndarray.tobytes([order]) Construct Python bytes containing the raw data bytes in the array. 转换成bytes

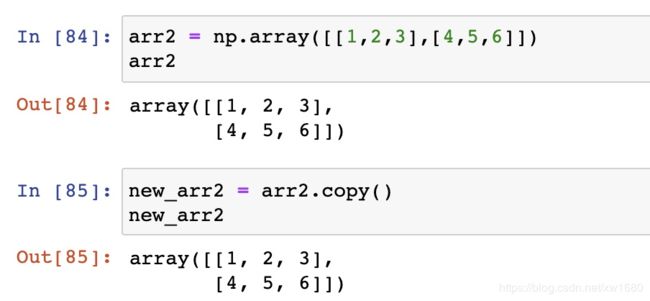
8. ndarray.copy([order]) Return a copy of the array. 当我们不想修改某个数据的时候,就可以去进行拷贝操作。在拷贝的数据上进行操作,示例代码如下:
4. 数组运算
4.1 逻辑运算
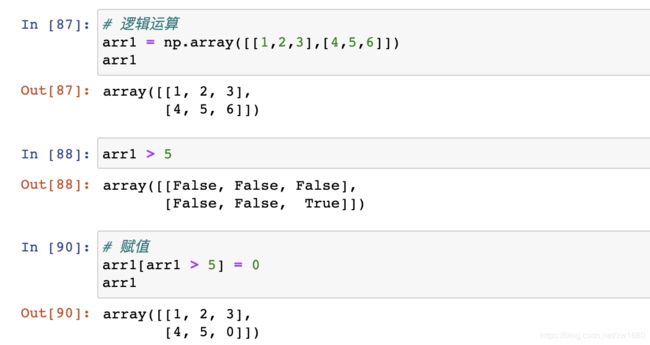
通用判断函数,np.all(),示例代码如下:

np.unique():返回新的数组的数值,不存在重复的值,示例代码如下:

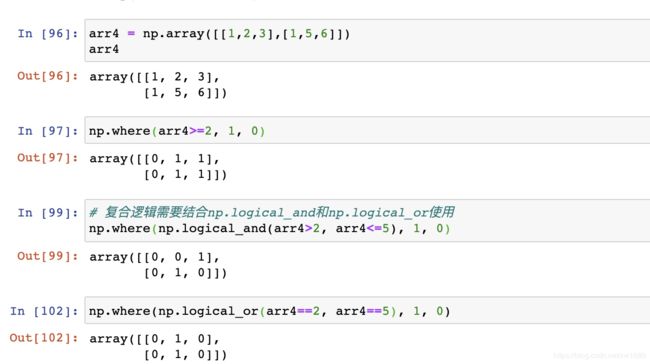
np.where (三元运算符):通过使用np.where能够进行更加复杂的运算,示例代码如下:
4.2 统计运算
在数据挖掘/机器学习领域,统计指标的值也是我们分析问题的一种方式。注意:进行统计的时候,axis轴 的取值并不一定, NumPy中不同的API轴的值都不一样,在这里,axis 0代表列, axis 1代表行 去进行统计。常用的指标如下:
- min(a[, axis, out, keepdims]) Return the minimum of an array or minimum along an axis. 示例代码如下:

- max(a[, axis, out, keepdims]) Return the maximum of an array or maximum along an axis. 示例代码如下:

- median(a[, axis, out, overwrite_input, keepdims]) Compute the median along the specified axis. 示例代码如下:

- mean(a[, axis, dtype, out, keepdims]) Compute the arithmetic mean along the specified axis. 示例代码如下:

- std(a[, axis, dtype, out, ddof, keepdims]) Compute the standard deviation along the specified axis. 示例代码如下:

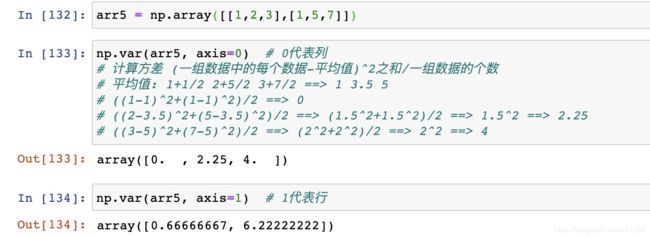
- var(a[, axis, dtype, out, ddof, keepdims]) Compute the variance along the specified axis. 示例代码如下:
- np.argmax(temp, axis=) 示例代码如下:

- np.argmin(temp, axis=) 示例代码如下:

4.3 数组间运算
数组与数的运算,示例代码如下:

矩阵运算,什么是矩阵?矩阵,英文matrix,和array的区别矩阵必须是2维的,但是array可以是多维的。示例代码如下:

4.4 合并分割
- numpy.concatenate((a1, a2, …), axis=0) 示例代码如下:

- numpy.hstack(tup) Stack arrays in sequence horizontally (column wise). 示例代码如下:

- numpy.vstack(tup) Stack arrays in sequence vertically (row wise). 示例代码如下:

- numpy.split(ary, indices_or_sections, axis=0) Split an array into multiple sub-arrays. 示例代码如下:

切割如果不太懂的话,可以点击 此处 参考学习。