R语言时间序列之数据平滑及预测
数据及代码参考书目:赵华老师的《时间序列数据分析》
一 移动平均
移动平均能消除数据中的季节变动和不规则变动。若序列中存在周期变动,则通常以周期为移动平均项数。移动平均法可以通过数据显示出数据长期趋势的变动规律。
R可用filter()函数做移动平均。用法:filter(data,filter,sides)
| 参数 | 含义 |
|---|---|
| data | 时间序列 |
| filter | 通常为一个向量,表示移动平均模型里的系数。如若为3项移动平均,则为c(1/3.1/3,1/3) |
| sides | 取1或者2,“1”表示单边卷积,“2”表示双边卷积 |
1、简单移动平均
简单移动平均就是将n个观测值的平均数作为第(n+1)/2个的拟合值。当n为偶数时,需进行二次移动平均。简单移动平均假设序列长期趋势的斜率不变。
以我国1992到2014年的季度GDP数据为例。
data<-read.csv("gdpq.csv")
tdata<-ts(data,start=1992,freq=4)
m1<-filter(tdata,filter=c(rep(1/4,4)))
plot(tdata,xlab="时间",ylab="gdp")
lines(m1,col="red",cex=1.5)
代码运行结果如上图,红色表示拟合值,黑色表示真实值。
2、二次移动平均
二次移动平均即在一次移动平均的基础上再进行一次移动平均。一般两次移动平均的项数是一致的。二次移动平均假设序列长期趋势的斜率是随时间的变化而变化的。
二次移动平均长期趋势的拟合公式为: at=2M1t−M2t ,其中 M1t 表示第一次移动平均的拟合值, M2t 表示二次移动平均的拟合值。
同样以上述数据为例,进行二次移动平均。代码如下:
plot(tdata,type="l",xlab="时间",ylab="季度GDP")
m2<-filter(m1,filter=c(rep(1/4,4)),sides=1)
lines(2*m1-m2,col="red",cex=2)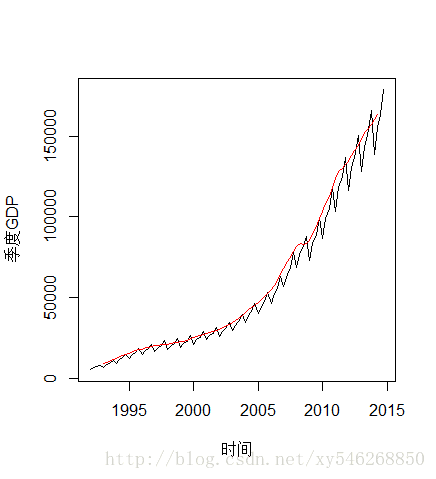
代码运行结果如上图所示,红色为二次移动的拟合值。
二 指数平滑
指数平滑的思想与移动平均是一样的,只是随着时间间隔的增加,加权的权重会呈指数衰减。它认为时间间隔越远的数据对当期数据的影响越小。R调用的函数为
HoltWinters(data, alpha=, beta=, gamma=,seasonal=c(“additive”,”multiple”)…)
| 参数 | 含义 |
|---|---|
| data | 时间序列 |
| alpha | 平滑系数a |
| beta | 斜率值的平滑系数 |
| gamma | 季节因子的平滑系数 |
| seasonal | 季节模型,additive表示加法季节模型;mutiple表示乘法季节模型 |
1、简单指数平滑
简单指数平滑假设序列中不存在季节变动和系统的趋势变化。模型公式为:
> data<-read.csv("consumer_cf.csv")
> newdata<-ts(data[,2],start=c(2010,1),freq=12)
> plot(newdata,type="o",cex.axis=1.5,cex.lab=1.5,
+ xlab="时间",ylab="消费者信心指数")
> a<-HoltWinters(newdata,beta=F,gamma=F)
> b<-HoltWinters(newdata,alpha=0.5,beta=F,gamma=F) #估计参数a
> b
Holt-Winters exponential smoothing without trend and without seasonal component.
Call:
HoltWinters(x = newdata, alpha = 0.5, beta = F, gamma = F)
Smoothing parameters:
alpha: 0.5
beta : FALSE
gamma: FALSE
Coefficients:
[,1]
a 105.2898
> pdata<-predict(a,6,prediction.interval = T)
> plot(a,pdata,type="o",xlab="时间",ylab="消费者信心指数")
代码运行结果如上所示。用HoltWinters()函数估计出来的a=0.78,且向后预测值为图中红色部分,黑色为真实值。这种预测方法预测出的值往往不够精确,因为它没有考虑序列中存在的其他变动。
2、Holt_Winters指数平滑
Holt_Winters指数平滑考虑了序列中存在的季节变动,这种方法对存在季节变动的经济数据有较好的拟合效果,可以用来进行向后预测。
加法季节模型:
其中p为季节变动的周期长度。其他含义同上。以上述的GDP数据为例,用HoltWinters指数平滑法分解GDP的水平,斜率及季节变动水平,并预测未来5年的值。代码如下:
> data<-read.csv("gdpq.csv")
> tdata<-ts(data,start=1992,freq=4)
> gdp.hw<-HoltWinters(tdata,seasonal="multi")
> plot(gdp.hw$fitted,type="o",main="分解图")
> plot(gdp.hw,type="o")
> pdata<-predict(gdp.hw,n.ahead=4*5)
> pdata
Qtr1 Qtr2 Qtr3 Qtr4
2015 149826.6 168126.7 176640.3 192627.9
2016 161252.4 180708.2 189616.2 206523.1
2017 172678.2 193289.7 202592.1 220418.2
2018 184104.1 205871.2 215568.0 234313.4
2019 195529.9 218452.8 228543.8 248208.5
> ts.plot(tdata,pdata,type="o",lty=1:2,col=c("red","black"))
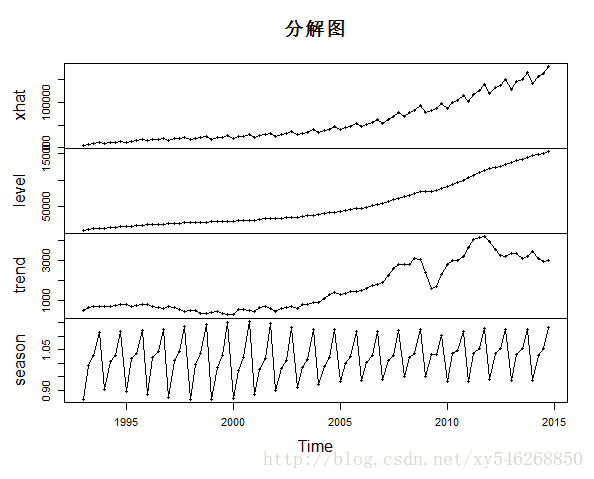
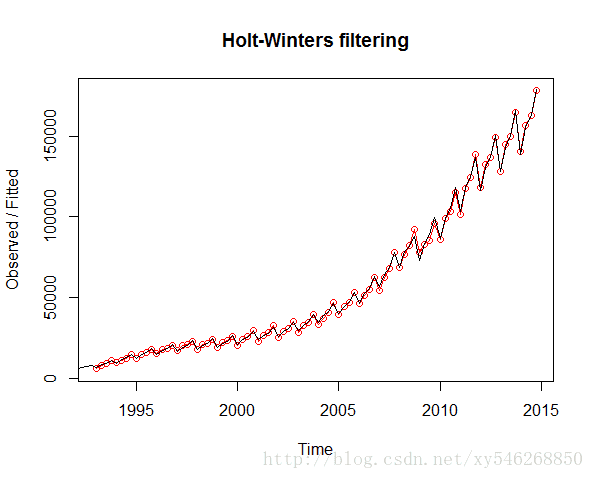
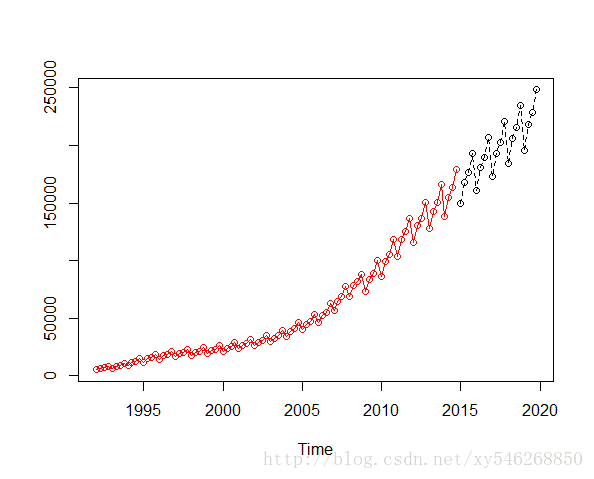
代码中采用了加法模型。序列的分解图如上图所示。第二个图为模型对数据的拟合图,第三个图的虚线部分为后5年的预测。