百度文库下载器Python实现
简介
以前可以用学校的企业账户下载文档,后来百度文库改版,需要买下载券或者会员。因此需要一个百度文库下载器。
之前有冰点文库下载器但是后来不好使了。
下面给出利用Python写的百度文库下载器。
此下载器可以下载doc类型的,txt类型的文本文档及PPT,不过PPT最终将以图片的形式保存。由于百度文库限制,暂时无法突破有试阅读的文档。PDF文档随缘下载。
实现思想及步骤
①文档链接网页GBK转码
②获取文档类型
③获取文档ID,每个文档都有一个ID,获取ID值,以下面的格式获取(以PPT为例)图片资源
https://wenku.baidu.com/browse/getbcsurl?doc_id=” + doc_id + “&pn=1&rn=99999&type=ppt
原理,预览页面中的这个不是PPT而是PPT图片,我们需要了解这个PPT是从哪儿获取的,找到了地址也就能把这些图片下载下来。
PPT转换核心源码
def gen_PPT(doc_id):
global url
index = 0
content_url = "https://wenku.baidu.com/browse/getbcsurl?doc_id=" + doc_id + "&pn=1&rn=99999&type=ppt"
content = fetch_url(content_url)
urlList = re.findall('{"zoom":"(.*?)","page"', content)
urllist = [item.replace("\\", '') for item in url_list]
if not os.path.exists(doc_id):
os.mkdir(doc_id)
for url in URLlist:
content = session.get(url).content
path = os.path.join(doc_id, str(index) + '.jpg')
with open(path, 'wb') as f:
f.write(content)
index = index + 1界面

界面太丑,不要在意
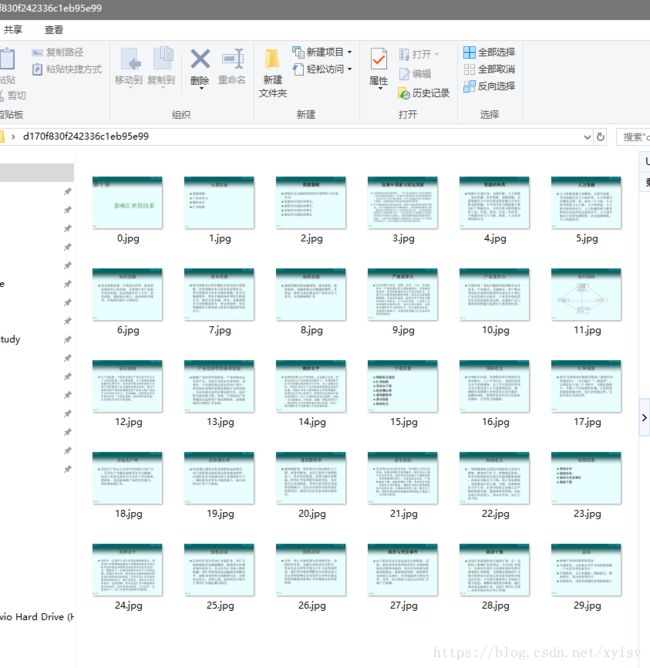
保存的文件
CSDN下载地址
https://download.csdn.net/download/xyisv/10531452
谢谢支持!
更多内容访问omegaxyz.com
网站所有代码采用Apache 2.0授权
网站文章采用知识共享许可协议BY-NC-SA4.0授权
© 2018 • OmegaXYZ-版权所有 转载请注明出处