NeurIPS 2019|腾讯AI Lab详解入选论文,含模仿学习、强化学习、自动机器学习等主题...
感谢阅读腾讯 AI Lab 微信号第 89 篇文章。本文将解读腾讯 AI Lab 入选 NeurIPS 2019 的 14 篇论文。
第 33 届神经信息处理系统大会(NeurIPS 2019)将于当地时间 12 月 8 – 14 日在加拿大温哥华举办。该会议的目标是促进有关神经信息处理系统的生物学、技术、数学和理论方面的研究交流。伴随着人工智能与机器学习领域的飞速发展,作为领域顶级学术会议之一的 NeurIPS 今年会议的论文投稿数量又创造了新的记录:本届会议共收到有效提交论文 6743 篇(相比去年增长近 39%),其中 1428 篇被接收,接受率为 21.17%。
腾讯公司今年共有 18 篇论文入选,引领国内产业界;其中来自腾讯 AI Lab 的论文共 14 篇,涉及强化学习、模仿学习、网络结构优化、计算机视觉和语义分割等多个研究主题。本文将汇总介绍腾讯 AI Lab 入选 NeurIPS 2019 的论文。
一、模仿学习
模仿学习是指通过演示的范例进行学习的方法。今年腾讯 AI Lab有一篇与模仿学习相关的论文入选,提出了一种基于观察进行模仿学习的新方法。
1. 通过最小化逆动力学分歧来实现从观察中模仿学习
Imitation Learning from Observations by Minimizing Inverse Dynamics Disagreement
论文:
https://papers.nips.cc/paper/8317-imitation-learning-from-observations-by-minimizing-inverse-dynamics-disagreement
本文由腾讯 AI Lab、清华大学以及 MIT-IBM Watson AI Lab 合作完成,是 NeurIPS 2019 的 Spotlight 论文之一。
本文主要讨论了如何在只提供专家状态演示(缺乏专家动作演示)下的模仿学习,即从观测中学习(LfO:Learning from Observations)。不同于从完备专家演示中学习(LfD:Learning from Demonstration),LfO 在利用更多形式的数据(比如视频,以往方法是无法使用这些数据)方面更具有实用性。同时,因为专家演示信息的不完备,所以实现 LfO 更加具有挑战性。这篇文章从理论和实践的角度讨论了 LfD 和 LfO 的不同。研究者从数学上证明:在 GAIL 的建模下,LfD 和 LfO 的差别实际上就是智能体和专家的逆运动模型的不一致性。更重要的是,这个差别的一个上界可以通过无模型的最大化熵来实现。作者将这种方法称为「逆动力学分歧最小化(IDDM)」,通过最小化 LfO 与 LfD 的区别来增强 LfO 的性能。大量实验表明,这种新方法相比传统 LfO 方法更有优势。

IDDM算法
二、强化学习
强化学习是近年来大放异彩的机器学习技术之一,基于这种技术开发的人工智能模型已经在围棋、扑克、视频游戏和机器人等领域取得了非常多的里程碑式的进步。腾讯 AI Lab的 NeurIPS 2019 入选论文中有三篇与强化学习有关,这三篇论文针对不同方向的任务分别提出了两种不同的新的算法以及一种新的多智能体学习策略。
1.基于课程引导的后验经验回放算法
Curriculum-guided Hindsight Experience Replay
论文:
https://papers.nips.cc/paper/9425-curriculum-guided-hindsight-experience-replay
本文由腾讯AI Lab/Robotics X主导,与华盛顿大学合作完成。在存在稀疏奖励的强化学习中,后验经验回放(HER)能够通过将失败经验的实现状态视为伪目标来从失败中学习。但是并非所有失败的经历对于学习都同样有用,因此使用所有失败经验的效率不高。
因此,本文提议:1)根据与真实目标的接近程度和对各种伪目标的探索好奇心,自适应地选择失败经验;2)逐渐改变选择指标中目标临近度和多样性的比例:本文采用类似人的学习的策略,即在早期阶段提高好奇心,之后又将重心转向临近度。这种「目标和好奇心驱动的课程学习」就引出了「课程指导的后验经验回放(CHER)」。该算法可以在强化学习过程中通过对失败经验选择而实现自适应,动态地控制探索与开发的权衡。实验结果表明,在具有挑战性的机器人环境(比如机器手转球等)中,CHER可以进一步提升当前最佳表现。

CHER算法
2.LIIR:多智能体学习中实现对个体即时内在奖励值的学习
LIIR: Learning Individual Intrinsic Reward in Multi-Agent Reinforcement Learning.
论文:
https://papers.nips.cc/paper/8691-liir-learning-individual-intrinsic-reward-in-multi-agent-reinforcement-learning
本文由腾讯AI Lab/Robotics X主导,与伦敦大学学院和罗彻斯特大学合作完成。在协作式多智能体强化学习(MARL)的场景中,环境的奖励值通常是回馈给整个多智能体团队的,这就产生了一个难题:如何通过整体团队的奖励值对每一个不同的智能体进行差异化和多样性的鼓励。
针对这一问题,本文提出了一种元学习的方法,即对每一个智能体学习一个虚拟的内在奖励值,但同时整体的学习目标仍然是优化团队的总体奖励。每一个智能体的虚拟即时奖励值都不相同,从而可以激励不同的智能体采取多样的有利于团队的行为。
具体来说,每一个特定的智能体的即时内在奖励涉及到为该智能体计算一个明确的代理评估函数,从而为其个体策略更新提供指示。同时,参数化的即时奖励函数也会得到更新,以最大化团队在环境中的预期累积奖励,因此这种方法的目标与原始 MARL问题的目标是一致的。这种新方法称为 LIIR。在《星际争霸 2》上的实验结果表明,通过学习多智能体的即时奖励可以激励多智能体产生有效并且多样的行为。
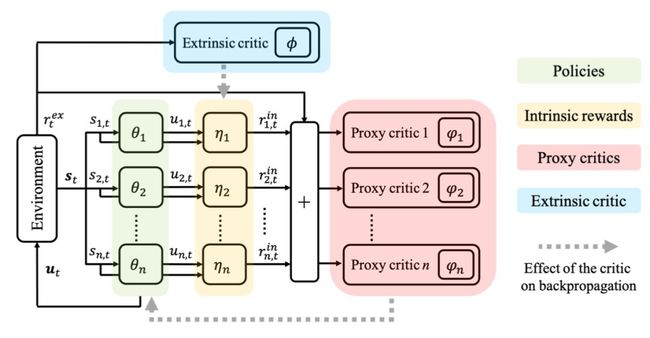
多智能体强化学习设置中的 LIIR 方法概况
3. 散度增强的策略优化算法
Divergence-Augmented Policy Optimization
论文:
https://papers.nips.cc/paper/8842-divergence-augmented-policy-optimization
本文由腾讯AI Lab与虎牙AI、香港中文大学、香港科技大学合作完成。在深度强化学习问题中,策略优化方法需要处理函数近似以及离线数据的使用问题。常用的策略梯度算法不能很好地处理离线数据,导致过早收敛和不稳定等问题。这篇论文介绍了在重复使用离线数据时能稳定策略优化训练的方法。主要思想是引入现有的策略和产生离线数据的行为策略之间的Bregman散度来保证安全的策略更新。本文的Bregman散度不只是加在两个策略的动作分布上,同时还考虑了两者状态分布上的散度,从而导出了本文的散度增强公式。在 Atari游戏上的实验说明在数据不足情况下,重复利用离线数据很有必要,而本文提出的方法可以比其它深度强化学习SOTA算法取得更好的效果。

散度增强的策略优化算法
三、自动机器学习与网络优化
腾讯 AI Lab 也在机器学习的基础方法上努力探索。今年入选 NeurIPS 的论文中有 5 篇与自动机器学习和网络优化有关,其中包括对网络架构和超参数的优化方法以及用于复合优化问题的新方法,另外还有一篇论文提出了用于分布式环境的通信优化方案——文中提出了 3 个针对不同方面的用以实现高效通信的分布式优化算法。
1. 用于复合优化问题的随机方差下降原始-对偶算法
Stochastic Variance Reduced Primal Dual Algorithms for Empirical Composition Optimization
论文:
https://papers.nips.cc/paper/9180-stochastic-variance-reduced-primal-dual-algorithms-for-empirical-composition-optimization
代码:
https://github.com/adidevraj/SVRPDA
本文由腾讯AI Lab主导,与佛罗里达大学合作完成。研究了通用的复合优化问题,在这个问题中样本平均不仅出现在非线性损失函数的里面和外面。很多机器学习问题均可以表述成这一类通用复合优化问题,因此高效求解这类问题具有很重要的实际应用意义。然而这类问题无法直接用随机梯度下降算法直接求解。
为了解决这个问题,本文现将原始的最小化问题等价表述成一个最小-最大化问题,这一等价变换可以将非线性损失函数里面的样本平均交换到外面去。充分挖掘了问题内在的结构之后,本文提出了一种随机原始-对偶算法SVRPDA-I来高效求解这个问题。同时本文对算法进行了全面的理论分析,推导了收敛速度、计算复杂度和存储复杂度,并证明了算法的线性收敛速度。
此外,本文还提出了一个近似算法SVRPDA-II,可以极大降低算法的存储复杂度(极大降低内存使用量),同时仅有很小的性能损失。在实际任务上的实验结果表明新提出的算法在性能上显著超过了现有的其他算法。

SVRPDA-I

SVRPDA-II
2. 通过分布迁移进行超参数优化
Hyperparameter Learning via Distributional Transfer
论文:
https://papers.nips.cc/paper/8905-hyperparameter-learning-via-distributional-transfer
本文由腾讯AI Lab主导,与牛津大学合作完成。贝叶斯优化是一种用于超参数优化的流行技术。但是即使在先前所解决任务与当前任务类似的情况下,贝叶斯优化通常也需要进行昂贵的初始探索。不同于传统的贝叶斯优化,本文提议了一种新的改进思路:基于这些任务的训练数据集所学到的分布表示而跨任务地迁移超参数对模型性能影响的知识。具体来说,该方法引入了一个超参数和数据表示的联合高斯过程来迁移历史任务超参数优化的知识,进而对新任务上的超参数优化起到热启动的效果。与现有基准相比,新提出的方法具有更快的收敛速度。在某些情况下,新算法仅需要迭代几次即可。

基于分布的贝叶斯优化算法
3. NAT:用于获得精确且紧凑型架构的神经网络架构变形器
NAT: Neural Architecture Transformer for Accurate and Compact Architectures
论文:
https://nips.cc/Conferences/2019/Schedule?showEvent=13305
本文由腾讯AI Lab主导,与华南理工大学合作完成。现有的神经网络架构基本都是手动设计的或者通过某些神经网络架构搜索方法得到的。但是,即使是精心设计的架构也仍然可能包含许多不重要的或冗余的计算模块或计算操作。这不仅会导致大量的内存消耗和计算成本,而且会使模型性能降低。因此,有必要在不引入额外计算成本的情况下优化已有神经网络架构内部的操作以提高性能。不幸的是,这样的约束优化问题是NP难的。
所以,本文将该问题简化为一个利用马尔可夫决策过程来自动优化神经网络架构的问题。针对该问题,本文提出一个名为神经网络架构变形器的算法。它可以将冗余操作替换为计算效率更高的操作。所研发的算法适用于对多种人工设计的以及网络架构自动搜索方法得到的网络架构的优化,并在两个标准数据集(即CIFAR-10和ImageNet)上进行了广泛实验。结果表明通过所提方法变形所得的架构显著优于其原始形式和通过其他现有方法优化所得的架构。
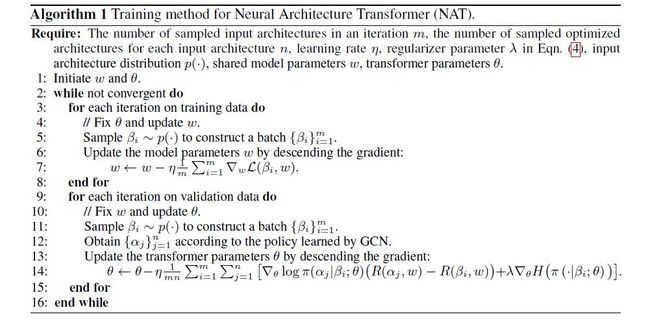
NAT的训练方法
4. 基于双重量化高效通信的分布式优化方法
Double Quantization for Communication-Efficient Distributed Optimization
论文:
https://papers.nips.cc/paper/8694-double-quantization-for-communication-efficient-distributed-optimization
本文由腾讯AI Lab与清华大学交叉信息研究院合作完成。在大规模分布式优化过程中,模型参数与梯度的同步通信往往是限制其训练效率的性能瓶颈。本文提出了一种双重量化的通信机制,同时对模型参数与梯度进行压缩以提升训练效率。具体的,本文从异步通信、梯度稀疏化以及基于动量项的加速策略三个方面,分别设计了高效通信的分布式优化算法:低精度的 AsyLPG、Sparse-AsyLPG、Accelerated AsyLPG。本文也给出了严格的理论保证。实验结果表明,本文提出的算法可以在精度无损的前提下,有效降低数据传输量,显著优于其它仅进行模型参数或者梯度量化的分布式优化方法。

AsyLPG算法

Sparse-AsyLPG算法

Accelerated AsyLPG算法
5. 基于随机递归梯度下降的有效率的光滑非凸随机复合优化
Efficient Smooth Non-Convex Stochastic Compositional Optimization via Stochastic Recursive Gradient Descent.
论文:
https://papers.nips.cc/paper/8916-efficient-smooth-non-convex-stochastic-compositional-optimization-via-stochastic-recursive-gradient-descent
本文由腾讯AI Lab与密苏里科技大学、罗切斯特大学、北京大学合作完成。在很多重要的机器学习任务如强化学习、投资组合管理等,随机复合优化有广泛的使用场景。随机复合优化问题的目标函数常态为两个随机函数的数学期望之合,其比vanilla随机优化问题更具有挑战性。
在本论文中,作者研究一般光滑非凸设定下的随机复合优化。作者使用一个最近提出的思想-随机递归梯度下降,设计出一个称为SARAH-Compositional的新算法。作者也为随机复合优化证明了一个锐利的IFO复杂度上界:在有限合情况下,该上界为$O((n+m)^{1/2}\varepsilon^{-2})$;在在线学习情况下,该上界为$\varepsilon^{-3}$。作为一项重要的理论性的结果,该复杂度为非凸随机复合优化的所有存在的IFO复杂度之最优。数值实验证明了论文中所提算法与其相关理论的优越性能。

SARAH-Compositional算法
四、语义分割
腾讯 AI Lab 还有 3 篇论文与语义分割相关,其中一篇研究的是使用图卷积网络的点云语义分割;另一篇为图像语义分割提出了一种新的非监督式域自适应方法。
1. 基于上下文信息的点表示挖掘局部和全局结构信息的点云语义分割
Exploiting Local and Global Structure for Point Cloud Semantic Segmentation with Contextual Point Representations
论文:
https://papers.nips.cc/paper/8706-exploiting-local-and-global-structure-for-point-cloud-semantic-segmentation-with-contextual-point-representations
代码:
https://github.com/fly519/ELGS
本文由腾讯AI Lab与深圳大学合作完成。本文提出了一种新型的点云语义分割模型。该模型基于上下文点云表示,可同时挖掘点云中的局部和全局结构。具体来说,本文通过对点本身及其上下文点信息设计了一种新颖的门控融合来丰富每个点的表示。然后,基于丰富点的表示,我们提出了一个新颖的图点云网模块(GPM),依靠图注意力模型动态地组成和更新局部点云结构内的每个点表示。最后,利用空间和通道的注意力模型,挖掘点云的全局结构信息,从而为每个点生成最终的语义标签。在公共点云数据库(即S3DIS和ScanNet数据集)上的大量结果证明了新提出的模型的有效性,并且结果也优于最先进的方法。相关研究代码已发布。
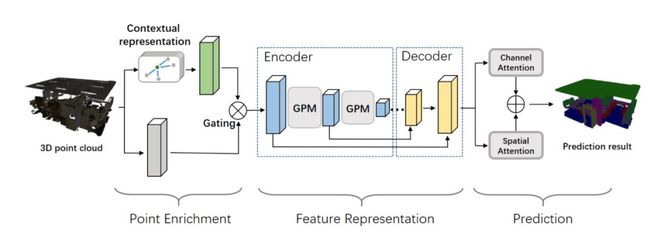
新提出的用于点云分割的模型,该模型由三个完全耦合的组件构成。其中 Point Enrichment组件不仅会考虑点本身,而且还会考虑其上下文的点信息,以便丰富其语义表示。Feature Representation组件使用了的传统的编码器-解码器架构,为每个点学习特征表示。具体来说,新提出的 GPM可通过一个 GAB模块动态地组成和更新每个点表示。Prediction 组件则同时使用通道和空间的注意力模型,进而融合全局结构信息预测每个点的语义标签。
2. 用于语义分割的基于类别锚点引导的非监督式域自适应
Category Anchor-Guided Unsupervised Domain Adaptation for Semantic Segmentation
论文:
https://papers.nips.cc/paper/8335-category-anchor-guided-unsupervised-domain-adaptation-for-semantic-segmentation
代码:
https://github.com/RogerZhangzz/CAG_UDA
本文由腾讯AI Lab与优必选悉尼大学人工智能中心合作完成。非监督的域自适应(UDA)之目的是提升一个特定学习模型从一个源域运用到一个目标域的推广能力。用户一般没有额外的精力去标注目标域的样本,因此UDA将显得非常有意义。然而,数据分布的差异或者域迁移/差异将不可避免地损害UDA的性能。虽然在匹配两个不同域的边际分布上有一些研究进展,但由于运行了类别未知的特征对齐,训练出的分类器会倾向于源域的特征,而对目标域的样本做出错误预测。
在本论文中,作者为图像语义分割提出一个新的类别锚点引导的UDA模型(CAG-UDA)。该模型可显式地运行类别可知的特征对齐,进而同步学习出共享的鉴别性强的特征与分类器。具体而言,源域特征的类别质心首先被用做引导的锚点,用来确定目标域的活跃特征并赋予它们伪标签。然后,作者使用一个基于锚点的像素级的距离损失和一个鉴别性损失分别推动类别内特征更近和类别间特征更远。最后,作者设计了一个阶段性的训练机制,用以降低累积的预测误差和逐步使模型更加适应目标域。在两个图像语义迁移分割的任务上,作者验证了所提出的CAG-UDA方法,结果表明新方法的性能超过当前业内最先进的方法。相关研究代码已发布。
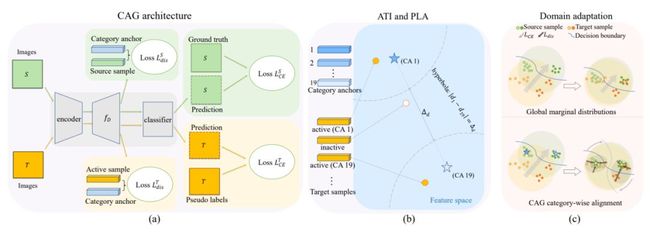
CAG-UDA 模式示意图
五、其他研究
以上研究之外,腾讯 AI Lab 还有 3 篇论文对其他(但并非不重要)的研究主题进行了探索。其中一篇提出了一种动态时间规整网络,可帮助更好地提取时间序列数据中的特征;另一篇则探索了通过使用对抗样本来提升跨模态哈希神经网络的鲁棒性。最后一篇则是视觉和语言结合方面的研究,提出了通过自然语言定位视频中语义上相关的片段的新机制
1.DTWNet:一种动态时间规整网络
DTWNet: A DynamicTime Wrapping Network
论文:
https://papers.nips.cc/paper/9338-dtwnet-a-dynamic-time-warping-network.pdf
本文由腾讯AI Lab主导,与康涅狄格大学合作完成。深度神经网络在处理时间序列数据时,传统的闵可夫斯基距离不适合作为反应序列相似度的损失函数,而动态时间规整算法(DTW)可以更好地计算序列距离,因此可以用作深度网络中的损失函数和特征提取算子。
本文提出了一种新的估计方法,使得DTW在作为算子时可以估计输入的梯度,从而实现神经网络中的反向传播。该方法首次分析了DTW作为损失函数的函数形态和应用梯度下降法的收敛性,并且首次提出了基于部分序列匹配的DTW梯度更新算法。实验结果表明,该方法作为一种新的特征抽取手段,可以更好地提取时间序列数据中的特征。此外,本文提出的梯度估算方法在实验中展现了良好的收敛性。本文也创造性地提出了该方法在数据分解上的拓展性应用。

针对一个分类任务的 DTWNet训练过程
2. 使用对抗样本的跨模态学习
Cross-Modal Learning with Adversarial Samples.
论文:
https://papers.nips.cc/paper/9262-cross-modal-learning-with-adversarial-samples
本文由腾讯AI Lab主导,与西安电子科技大学、匹兹堡大学合作完成。随着深度神经网络的快速发展,已经诞生了大量的深度跨模态分析方法,而且这些方法也在医疗AI等领域得到了广泛的应用。但是,最近关于深度神经网络的鲁棒和稳定性研究发现:样本的一个微小更改(即对抗样本,甚至人类肉眼完全无法察觉)就能轻易骗过一个主流的深度神经网络而造成性能的巨大下降。因此,对抗样本是当前跨模态分析研究探索的一大障碍。
在本论文中,作者提出了一种新的跨模态学习方法,称为CMLA,该方法是首个构造并学习出了多模态数据中的对抗样本的方法。。在基于跨模态哈希的检索任务上,新提出的CMLA方法表现出了很好的性能。在两个跨模态基准数据集上的实验论证表明:CMLA创造的对抗样本能快速地骗过一个目标跨模态哈希网络,另一方面也能通过继续的对抗训练提升该目标跨模态哈希网络的鲁棒性。
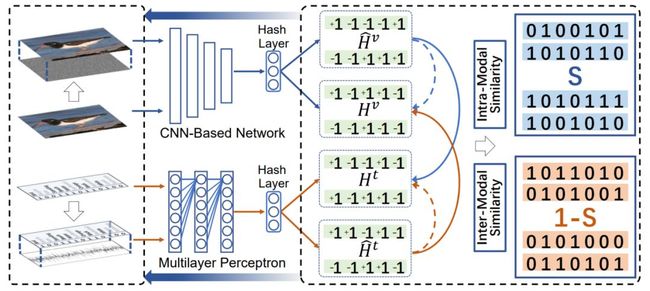
用于跨模态哈希学习的 CMLA的流程图

CMLA算法
3. 用于视频自然语言定位的语义条件动态调制机制
Semantic Conditioned Dynamtic Modulation for Temporal Sentence Grounding in Videos
论文:
https://papers.nips.cc/paper/8344-semantic-conditioned-dynamic-modulation-for-temporal-sentence-grounding-in-videos
代码:
https://github.com/yytzsy/SCDM
本文由腾讯AI Lab主导,与清华大学合作完成。视频中自然语句定位任务的目标是检测和定位一个目标视频片段,使得该片段在语义上与给定的句子语义相对应。现有方法主要通过在句子和候选视频片段之间匹配和对齐语义来解决该任务,而忽略了句子信息在时间上的关联和组成视频内容中起到的重要作用。
本文提出了一种新颖的语义条件动态调制(SCDM)机制,该机制依赖于句子语义来调制时间域卷积运算,以便随着时间的推移更好地关联和组成与句子相关的视频内容。更重要的是,提出的SCDM针对各种视频内容动态地执行,从而在句子和视频之间建立更精确的匹配关系,进而提高了时间上的定位精度。在三个公共数据集上进行的大量实验表明,新提出的模型优于已有的方法,说明了SCDM能够更好地关联和定位相关视频内容以进行时间域文本定位。相关研究代码已发布。
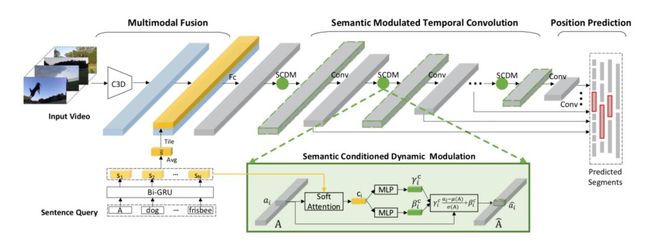
该模型由三个完全耦合的组件构成。Multimodal Fusion 组件会以细粒度的方式融合整个句子和每个视频片段。基于融合后的表示,Semantic Modulated Temporal Convolution 组件会在时间卷积过程中将与句子相关的视频内容相关联,其中新提出的 SCDM会根据句子来动态地调制时间特征图。最后,Position Prediction 组件会基于已调制的特征输出候选视频片段的位置偏移量和重叠分数。

* 欢迎转载,请注明来自腾讯AI Lab微信(tencent_ailab)