scene graph(visual relation) 简述
场景图和视觉关系主要用于理解图像,可以作为caption、text2image、retrival的基础。基本思路是object detection加上
Neural Motifs: Scene Graph Parsing with Global Context
https://rowanzellers.com/neuralmotifs/
motif指场景图中重复出现的子结构。引入relation priors(主语和宾语确定,relation很容易确定,并且类似的motif会大量出现)后,直接通过统计的方法,不需要图片信息就能得到较高的准确率。
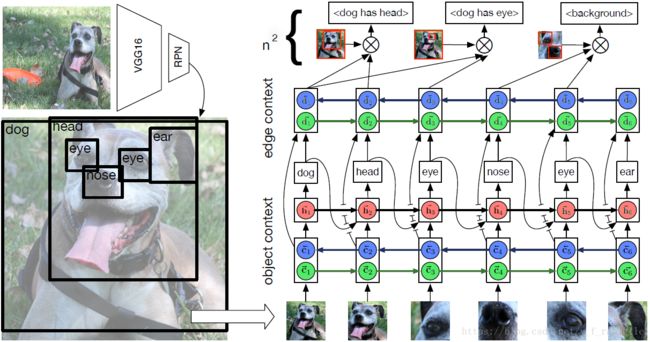
文中的方法先将图片做proposal,依次通过一个双向LSTM,得到object context(c),并作为全局信息传递,c再输入LSTM解码得到label。将c和label同时输入一个双向LSTM得到edge context(d),并作为全局信息传递,d的全连接根据motif有不同的bias,得出可能的关系预测。
考虑motif、overlap、context之后对直接预测有一定提高但效果不是特别明显。
Detecting Visual Relationships with Deep Relational Networks
https://github.com/doubledaibo/drnet_cvpr2017
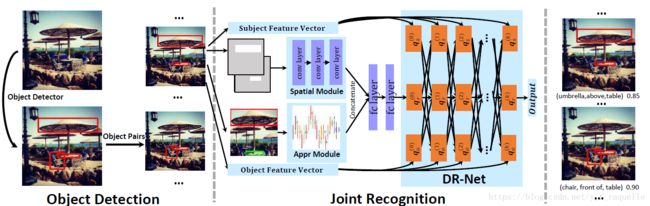
使用Faster RCNN做object detection之后对每一对object pair经过考虑它们的空间结构和物体类别过滤后进入联合识别模块。联合识别通过得到Appearance(包括单个物体和多个物体共存区域)和Spatial Configurations(如相对位置和相对大小,采用几何度量)特征,再通过两个全连接层连结压缩,输入发掘过Statistical Relations的DR-Net,最终输出三元组。这里的DR-Net采用了CRF。
Scene Graph Generation from Objects, Phrases and Region Captions
https://github.com/yikang-li/MSDN
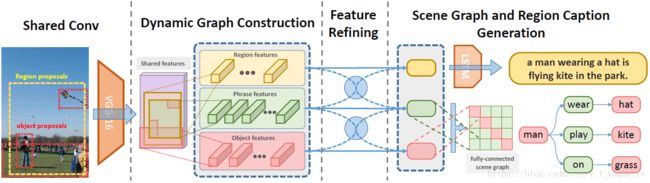
将region、phrase、object特征联合分析,经过两个全连接层将不同信息相互传递,将refine过的特征做分类、caption、预测。scene graph通过object和relations来构造。
Scene Graph Generation by Iterative Message Passing
https://github.com/danfeiX/scene-graph-TF-release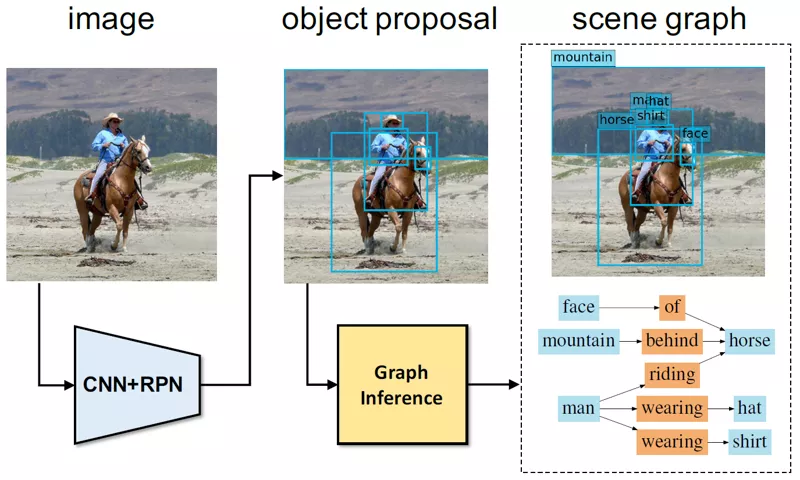

通过RPN做object proposal。从主宾组合得到edge特征和hidden状态,从rois得到node特征和hidden state。根据node state和对应的inbound edge state和outbound edge state池化得到node message,根据edge state和对应的主语node state和宾语node state池化得到edge message,再将他们用于更新对应的hidden state。多次迭代,得到最终预测结果。
Pixels to Graphs by Associative Embedding
https://github.com/princeton-vl/px2graph
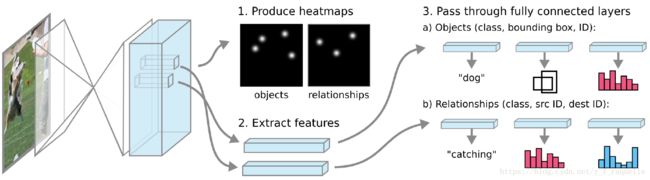
引入Human Pose Estimation中的associative embedding。构造一个像素级网络输出object和relationship的热点图并导出像素级features,将带有id的features导入全连接层预测object和relationship。
Visual Relationship Detection with Language Priors
https://github.com/Prof-Lu-Cewu/Visual-Relationship-Detection
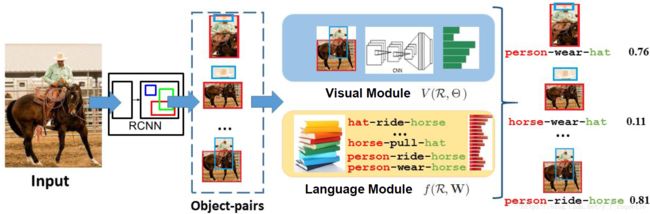
在视觉模型之外引入了语言模型,将关系映射到一个embedding space(embedding我的理解就是抽象为向量),通过学习关系先验使得相近的关系向量距离很近,输出可能性评分。
Image Retrieval using Scene Graphs
Generating Semantically Precise Scene Graphs from Textual Descriptions
Image Generation from Scene Graphs
参考链接:
https://blog.csdn.net/u013010889/article/details/80932537
https://blog.csdn.net/qq_37014750/article/details/82528396
https://zhuanlan.zhihu.com/p/35515945
https://xuewenyuan.github.io/posts/2017/07/blog-post-7/
https://blog.csdn.net/u013010889/article/details/80976534
https://zhuanlan.zhihu.com/p/34509717
https://github.com/danfeiX/scene-graph-TF-release
https://zhuanlan.zhihu.com/p/35697754
https://media.nips.cc/nipsbooks/nipspapers/paper_files/nips30/reviews/1294.html
https://blog.csdn.net/sinat_29963957/article/details/81256144