Feature Pyramid Networks for Object Detection (FPN-2017CVPR)主要内容翻译与理解
摘要
在检测不同尺度物体的识别系统中,特征金字塔是一个基本的组成成分。但是最近的深度学习物体检测器有着无效的金字塔表达,在某种程度上因为他们计算和内存紧张。在这篇文章中,我们利用深度卷积网络的金字塔形的层--内在的多尺度去几乎没有额外损失地构造特征金字塔。我们提出一个带有横向连接的自顶向下结构去建立所有尺度的高水平语义特征图。这个结构,称为FPN,作为一个通用的特征提取器在几个应用中有着显著的改善。在一个基本的Faster R-CNN系统中使用FPN,我们的方法毫无花里胡哨地在COCO检测基准中达到最高的单模型结果,胜过所有存在的单模型记录,包括COCO2016挑战赛的胜者。此外,我们的方法在一块GPU上可以跑到每秒6帧,因此在多尺度目标检测中是一个实用的和准确的方案。
1.介绍
在计算机视觉中,识别不同尺度的物体是一个根本的挑战。基于图像金字塔建立的特征金字塔(简而言之,我们称这些特征图像为金字塔)构成了标准解决方案的基础 [1] (Fig. 1(a))。这些金字塔具有尺度不变性,因为一个物体的尺度变化被金字塔的层变化所抵消。直观地,这个属性通过在空间位置和金字塔层上扫描模型,使模型可以在一个很大范围的尺度上检测物体。
在人工设计特征的时代 ,特征化的图像金字塔被广泛使用[5, 25]。他们如此重要以至于许多物体检测方法,像DPM [7],需要密集的尺度取样去实现好的结果(例如,每octave10个尺度)。对于识别任务,设计的特征很大程度上已经被深度卷积网络(ConvNets)计算的特征所取代 [19, 20]。除了能够表示更高水平的语义,ConvNets对于尺度变化的鲁棒性也更强,因此有利于利用单个输入尺度提取的特征进行识别 [15, 11,29] (Fig. 1(b))。但是即使有了这种鲁棒性,金字塔仍然需要得到最精确的结果。在ImageNet [33] 和COCO [21] 的检测挑战中,所有最近的top记录都在特征化的图像金字塔上使用多尺度测试 (例如,[16, 35])。特征化的图像金字塔的每一层的主要优点是,它产生了一个多尺度的特征表示,其中所有的层都具有很强的语义,包括高分辨率层。
然而,特征化图像金字塔的每一层有着明显的限制。推理时间显著增加(例如, 增加4倍 [11]),使得这种方式在实际应用中不切实际。而且,就内存而言,在图像金字塔上端到端地训练深度神经网络是不可行的,因此,如果用的话,图像金字塔仅在测试时使用[15, 11,16,35],这也造成了训练/测试时推理的不一致。基于这些原因,Fast 和Faster R-CNN[11, 29]选择在默认设置下不使用特征化的图像金字塔。
然而,图像金字塔不是计算多尺度特征表达的唯一方式。一个深度卷积网络逐层地计算一个特征层次结构,并且通过下采样层,特征层次结构有着一个固有的多尺度的、金字塔形的形状。这种网络内的特征层次结构产生不同空间分辨率的特征图,但是引入了由不同深度造成的巨大的语义差异。高分辨率图有着低层次的特征,这也损害了它们用于物体识别的表达能力。
Single Shot Detecter(SSD)是使用ConvNet的金字塔形的特征层级结构的首批尝试之一,就像这种结构是一个特征化图像·金字塔 (Fig. 1(c))一样。理论情况下,SSD形式的金字塔再次利用前向传播过程中计算出来的来自不同层的多尺度特征图,因此没有什么消耗。但是为了避免使用低层特征,SSD放弃重用已经计算的层,而是从网络的高层开始建立金字塔(例如,VGG网络的conv4_3),然后增加几个新的层。因此,SSD错过了重用特征层级结构中高分辨率图的机会。(在后文)我们显示了这些高分辨率图对于检测小物体是非常重要的。
这篇文章的目标是自然地利用ConvNet的特征层级结构的金字塔形状,同时创造一个在所有尺度有着强语义的特征金字塔。为了完成这一目标,我们依靠一种将低分辨率、强语义特征和高分辨率、弱语义特征结合的结构,基于一种自顶向下的路径和横向连接的方式 (Fig. 1(d))。这种结构可以产生一个在所有层都有着丰富语义的特征金字塔,并且可以从单个输入图像上快速建立。换句话说,我们展示了怎样去创建一个网络内特征金字塔,它可以没有牺牲表达能力、速度、或者内存地取代特征化的图像金字塔。
 图1. (a)使用一个图像金字塔去建立一个特征金字塔。在每个尺度的图像上独立地计算特征,很慢。(b)最近的检测系统仅仅使用单个尺度特征,为了更快的检测。(c)另一种方法是再次使用通过ConvNet计算得到的金字塔形的特征层级结构,就好像它是一个特定的图像金字塔。 (d)我们提出的 Feature Pyramid Network (FPN) 和(b)(c) 一样快,但是更准确。图中, 由蓝色的更厚的轮廓指出的特征图有着更强的语义特征。
图1. (a)使用一个图像金字塔去建立一个特征金字塔。在每个尺度的图像上独立地计算特征,很慢。(b)最近的检测系统仅仅使用单个尺度特征,为了更快的检测。(c)另一种方法是再次使用通过ConvNet计算得到的金字塔形的特征层级结构,就好像它是一个特定的图像金字塔。 (d)我们提出的 Feature Pyramid Network (FPN) 和(b)(c) 一样快,但是更准确。图中, 由蓝色的更厚的轮廓指出的特征图有着更强的语义特征。
相似的结构采用自顶向下和跳过连接的方式,在最近的研究中很流行 [28, 17,8,26]。他们的目标是去产生单个好的分辨率的高层特征图,然后在这个特征图上进行预测 (Fig. 2 top)。相反,我们的思想是将这种结构作为一种特征金字塔使用,然后在每一个层上独立地预测(Fig. 2 bottom)。我们的模型模仿了特征化的图像金字塔,这在这些工作中没有被研究过。
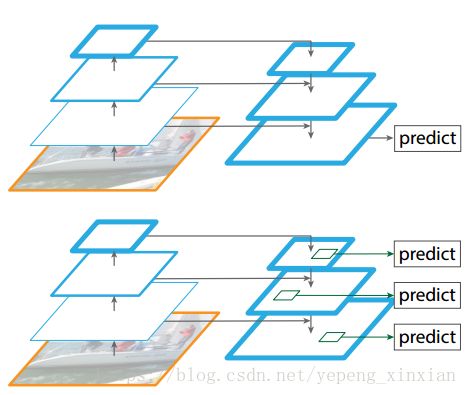 图 2. 上面:带有跳过连接的自顶向下结构,在最好的层预测(比如,[28])
图 2. 上面:带有跳过连接的自顶向下结构,在最好的层预测(比如,[28])
下面:我们的模型有着相似的结构,但是将它作为一个特征金字塔使
用,所有层独立预测
我们在各种各样检测和分割系统中评估我们的思想,称之为特征金字塔网络(FPN) [11, 29,27]。毫无花里胡哨地,基于FPN和一个基本的Faster R-CNN检测器 [29],我们在具有挑战性的COCO检测基准 [21]中报告了一个最先进的单模型结果,超过了所有存在的设计复杂的竞争胜者的单模型记录。在ablation实验中,我们发现对于bounding box proposals,FPN提高了平均召回率(AR)8个百分点;对于目标检测,FPN提高了COCO形式的平均准确度(AP)2.3个百分点,提高了PASCAL形式的AP3.8个百分点,超过了ResNets上的Faster R-CNN的单尺度基线 [16]。我们的思想也很容易扩展到mask proposals并且提高实例分割AR和速度,超过那些严重依靠图像金字塔的最先进的思想。
除此之外,我们的金字塔结构可以在所有尺度上端到端训练,并且在训练/测试时具有一致性,而这点在使用图像金字塔时将会因为内存而不可行。因此,相对于所有存在的最先进的思想,FPN可以达到更高的准确率。而且,这种提高在没有增加单尺度基线的测试时间的情况下就可以达到。我们相信这些进步将促进未来的研究和应用。我们的代码将会公开。
2.相关工作
手动设计特征和早期的神经网络
深度卷积网络物体检测器
使用多层的思想
3.特征金字塔网络
我们的目标是去利用Convnet的金字塔形的特征层级结构(这种结构有着从低到高水平的语义),并建立一个全部是高水平语义的特征金字塔。由此产生的FPN是通用的,在这篇文章中我们关注滑动窗口提议器(区域提议网络RPN)和基于区域的检测器(Faster R-CNN)[11]。在 Section 6,我们也推广FPN到实例分割方案中。
我们的思想将任意大小的单尺度图像作为输入,用全卷积的方式,在多个层输出成比例大小的特征图。这个过程独立于主体的卷积结构(例如,[19,36,16]),在这篇文章中我们使用ResNets呈现结果 [16]。我们金字塔的结构涉及一个自底向上的方式、一个自顶向下的方式和横向连接,就像下面介绍的那样。
自底向上的方式 自底向上方式是主体ConvNet的前向计算,它计算了一个由多个尺度特征图组成的特征层次结构,每步的缩放大小为2。通常有许多层产生相同大小的输出图,我们说这些层处于相同的网络阶段。我们选择每个阶段的最后一层的输出作为我们的特征图的参考集,我们将丰富它来创建我们的金字塔。这种选择是有道理的,因为每个阶段最深的层应该有着最强的特征。
具体来说,对于ResNets[16],我们使用每个阶段最后的残差块的特征激活层的输出。我们将这些残差块最后的输出(即conv2、conv3、conv4和conv5的输出)表示为{C2,C3,C4,C5},注意,与输入图像相比,它们的步长为 {4,8,16,32}。由于conv1占用了大量内存,所以我们不将其包含在金字塔中。
自顶向下的方式和横向连接 自顶向下路径通过在更高的金字塔层中,向上采样在空间上更粗但语义上更强的特征图,产生更高分辨率的特征。这些特征被从自底向上途径中利用横向连接得到的特征增强。每个横向连接都融合自底向上路径得到的和自顶向下路径得到的相同大小的特征图。自底向上的特征图具有较低层次的语义,但是它具有更精确定位的激活,因为它的下采样次数更少。
图3显示了构造自顶向下特征图的构建模块。首先,对于更粗分辨率的特征图,我们将其空间分辨率提高了2倍(简单地使用最近邻上采样)。然后,通过像素相加的方式将上采样的图和相应的自底向上的图(经过了一个1x1卷积层的处理,目的是降低通道维度)融合。迭代这个过程,直到生成最好分辨率的图。迭代开始时,我们简单地采用1x1卷积层处理C5得到最粗分辨率的特征图。最后,我们添加一个3×3卷积处理每个融合后的特征图生成最终的特征图,这是为了减少upsampling过程的混叠效应。最终的特征图集合被称为{P2,P3,P4,P5} ,对应于{C2,C3,C4,C5},它们分别具有相同的空间大小。
因为金字塔的所有层共享分类器/回归器,就像在传统的特征化图像金字塔中一样,我们固定所有特征图的特征维度(通道的数量,记为d)。我们在本文中设置d = 256,因此所有额外的卷积层(即横向连接中的1x1卷积)都有256个通道的输出。在这些额外的层中没有非线性,我们在经验上发现它们有很小的影响。
简单性是我们设计的核心,我们发现我们的模型对作为许多设计的选择都是鲁棒的。我们尝试了一些更复杂的模块(例如,使用多层残差块[16]作为连接),并观察到稍微更好的结果。设计更好的连接模块不是本文的重点,所以我们选择了上面描述的简单设计。
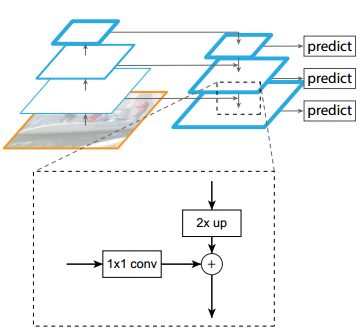 图 3. 一个基本模块阐述横向连接和自顶向下的方式,用相加的方式融合
图 3. 一个基本模块阐述横向连接和自顶向下的方式,用相加的方式融合
4.应用
4.1 特征金字塔网络用于RPN
4.2 特征金字塔网络用于R-CNN
5.在物体检测上的实验
5.1 用RPN 提取候选区域(Region Proposal)
实现细节
5.1.1 融合方案
和基准的对比
自顶向下的改进有多重要?
横向连接有多重要?
金字塔表达有多重要?
5.2 用Fast/Faster R-CNN 目标检测
实现细节
5.2.1 Fast R-CNN (在固定的候选区域)
5.2.2 Faster R-CNN(在一致的候选区域)
5.2.3 和COCO竞争胜者的对比
6.扩展:分割方案
7.总结
A.分割方案的实现
Tips:
基本思路:图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来
对图1的理解:(a)对原始图像构造图像金字塔,然后在图像金字塔的每一层提出不同的特征,然后进行相应的预测。(b)在图像的特征空间中构造金字塔。实验表明,浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助我们准确的检测出目标。(c)同时利用低层特征和高层特征,分别在不同的层同时进行预测,优点是在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不需要进行多余的前向操作。对于卷积神经网络而言,不同深度对应着不同层次的语义特征,浅层网络分辨率高,学的更多是细节特征,深层网络分辨率低,学的更多是语义特征。深层的特征图具有更加抽象的语义信息,而浅层特征图具有较高的分辨率。(d)FPN能够很好地处理小目标的主要原因:1. FPN可以利用经过top-down模型后的那些上下文信息(高层语义信息)2. 对于小目标而言,FPN增加了特征映射的分辨率(即在更大的feature map上面进行操作,这样可以获得更多关于小目标的有用信息)