数据挖掘算法和实践(十):TensorFlow和keras如何实现线性回归LinearRegression
从实践出发学习TensorFlow和teras机器学习框架,分别用tf和keras实现线性模型,两者区别在于前者相当于手推了线性回归模型,后者使用单层的感知机,很便捷,代码地址:https://github.com/yezonggang/tensorflow
一、首先使用TensorFlow(版本2.0),需要自定义优化器、拟合函数等,如下:
from __future__ import absolute_import, division, print_function
import tensorflow as tf
import numpy as np
rng = np.random
# Parameters.
learning_rate = 0.01
training_steps = 1000
display_step = 50
# Training Data.
X = np.array([1.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,7.042,10.791,5.313,7.997,5.654,9.27,3.1])
Y = np.array([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,2.827,3.465,1.65,2.904,2.42,2.94,1.3])
# Weight and Bias, initialized randomly.
# 手动设置权重w和偏置b
W = tf.Variable(rng.randn(), name="weight")
b = tf.Variable(rng.randn(), name="bias")
# Linear regression (Wx + b).
# 定义线性函数
def linear_regression(x):
return W * x + b
# Mean square error.
def mean_square(y_pred, y_true):
return tf.reduce_mean(tf.square(y_pred - y_true))
# Stochastic Gradient Descent Optimizer.
optimizer = tf.optimizers.SGD(learning_rate)
# Optimization process.
def run_optimization():
# Wrap computation inside a GradientTape for automatic differentiation.
with tf.GradientTape() as g:
pred = linear_regression(X)
loss = mean_square(pred, Y)
# Compute gradients.
gradients = g.gradient(loss, [W, b])
# Update W and b following gradients.
optimizer.apply_gradients(zip(gradients, [W, b]))
# Run training for the given number of steps.
# 开始训练,按照预定义的步长
for step in range(1, training_steps + 1):
# Run the optimization to update W and b values.
run_optimization()
if step % display_step == 0:
pred = linear_regression(X)
loss = mean_square(pred, Y)
print("step: %i, loss: %f, W: %f, b: %f" % (step, loss, W.numpy(), b.numpy()))
import matplotlib.pyplot as plt
# Graphic display 画图看效果
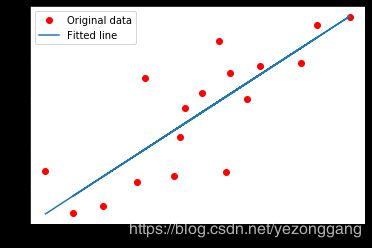
plt.plot(X, Y, 'ro', label='Original data')
plt.plot(X, np.array(W * X + b), label='Fitted line')
plt.legend()
plt.show()这里说一下TensorFlow中求平均值函数reduce_mean(),可以定义按照行或者列求平均值等;
# tf中reduce函数计算均值
tf.reduce_mean(
input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None
)
# 举个例子:n的输出[1 5 6]
m = np.array([(1,7,4),(2,3,9)])
n=tf.reduce_mean(m,axis=0)
print(m,n)在TensorFlow中,梯度下降法GradientTape的使用:
#举个例子:计算y=x^2在x = 3时的导数:
x = tf.constant(3.0)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
dy_dx = g.gradient(y, x)
# y’ = 2*x = 2*3 = 6
#GradientTape会监控可训练变量:
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
输出训练过程:

训练结果:;

二、我们使用keras 框架实现线性回归,有点就是不用在意实现细节,定义一个感知机模型(单层网络)训练即可,如下
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
# X和Y的值
X = np.array([1.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,
7.042,10.791,5.313,7.997,5.654,9.27,3.1])
Y = np.array([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,
2.827,3.465,1.65,2.904,2.42,2.94,1.3])
data=pd.DataFrame(np.vstack((X,Y))).T # 两个array合并后转秩,才能得到一个df
data.rename(columns={0:'data_input',1:'data_output'},inplace=True) # 队列名重命名
print(data)
# 画个图瞅瞅分布
sns.scatterplot(x="data_input",y="data_output",data=data)
# 定义顺序模型方法(装饰类),中间层即输出层1,输入层1,
model=tf.keras.Sequential()
model.add(tf.keras.layers.Dense(1,input_shape=(1,)))
model.summary()
# 设置优化器和损失函数
model.compile(optimizer="adam",loss="mse")
history=model.fit(x,y,epochs=500)
# 画图看效果
data_predict=model.predict(data.data_input)
plt.plot(data.data_input,data.data_output, 'ro', label='Original data')
plt.plot(data.data_input, data_predict, label='Fitted line')
plt.legend()
plt.show()
这里讲一下numpy.array和pd.dataframe的相互转换,一般py包中默认使用numpy作为基本的向量操作包,对于习惯使用pd.dataframe的人来说,要熟悉基本操作:
# 两个array合并后转秩,才能得到一个df
data=pd.DataFrame(np.vstack((X,Y))).T
# 熟练操作dataframe函数
data.rename(columns={0:'data_input',1:'data_output'},inplace=True)
# 随机生成dataframe
df = pd.DataFrame(np.random.randint(70,100,(3,5)),
index=["地区1", "地区2", "地区3"],
columns=["北京","天津", "上海","沈阳", "广州"])原始数据分布:

拟合的效果图: