视频预测算法vid2vid比MCNet好在哪里?
视频是一个时序性的图像,所以在模型中既需要捕捉时间相关性,也需要捕捉空间上的特征。时间相关性可以用LSTM这样的类RNN模型来捕捉,而空间相关性则需要CNN网络。更早一点的ConvLSTM单元就是这种思想。深度学习能够处理各种各样的问题,前提是根据问题本身需要设计相关的网络结构, MCNet和vid2vid是17年和18年比较优秀的视频序列处理算法,本文主要分析vid2vid网络与MCNet相比更加优秀的设计,同时尝试解读设计背后的思考和理由。
首先讲一下2017年 ICLR的论文MCNet:Decomposing Motion and Content for Natural Video Sequence
顾名思义,MCNet考虑动态motion信息和空间content信息,使用不同的网络结构将两种特征分开捕捉,试图更好地获取视频时间线和空间线特征,再将二者合并,用于下游任务(视频预测)。视频预测是一个生成任务,下图是MCNet的Generator。
上图左是一个简单的Motion Content Generator,上图右是一个含有Encoder各层不同尺度的残差Generator。整个Generator包含5种结构:
- Motion Encoder:公式
 。Motion Encoder包含两个部分,分别是CNN特征提取网络和ConvLSTM层。其中CNN特征提取层是三层卷积网络,且每帧都共享参数;每个ConvLSTM单元则包含一次卷积和一层LSTM。CNN特征提取层的输入是x(t)-x(t-1),它是当前帧图像和上一帧图像的像素值差;ConvLSTM 单元则还需要输入上帧输出的隐藏状态向量d(t-1)和c(t-1),类比于LSTM,d相当于LSTM里的h,是上帧的ConvLSTM单元输出的特征向量,c(t-1)是上帧单元输出的记忆单元(类似于LSTM单元中的累加的记忆通道)。最后一个ConvLSTM单元输出d(t)和c(t),其中d(t)相当于Motion Encoder捕捉到的动态特征,会传到后面的Combination layer中与Content信息结合。
。Motion Encoder包含两个部分,分别是CNN特征提取网络和ConvLSTM层。其中CNN特征提取层是三层卷积网络,且每帧都共享参数;每个ConvLSTM单元则包含一次卷积和一层LSTM。CNN特征提取层的输入是x(t)-x(t-1),它是当前帧图像和上一帧图像的像素值差;ConvLSTM 单元则还需要输入上帧输出的隐藏状态向量d(t-1)和c(t-1),类比于LSTM,d相当于LSTM里的h,是上帧的ConvLSTM单元输出的特征向量,c(t-1)是上帧单元输出的记忆单元(类似于LSTM单元中的累加的记忆通道)。最后一个ConvLSTM单元输出d(t)和c(t),其中d(t)相当于Motion Encoder捕捉到的动态特征,会传到后面的Combination layer中与Content信息结合。 - Content Encoder:内容(空间信息)编码器的输入只有当前帧的图像,网络主体是CNN网络,官方代码中使用的是多层3*3卷积,Pooling次数必须保持和Motion Encoder一致。
- 多尺度残差:为了加强网络适应不同scale的图像的能力,且给Decoder提供更多的信息,在Decoder中对两个Encoder中对应的Pooling后获得的特征进行残差操作。
- Motion Content结合层:普通concat之后接3层卷积。
- Decoder:使用转置卷积进行“上采样”,转置卷积的层数与Content Encoder类似,每一种scale进行了residual操作。
以上是MCNet的生成器的结构,生成模型当然少不了Discriminator提供的GAN loss。这里的鉴别器很简单,就是一个普通卷积网络,不过鉴别器的输入是整个序列,真实样本是输入序列+输出帧gt,fake样本是输入序列+模型输出序列。Loss具体情况如下图所示:

由于视频预测的是多帧,所以对于单个样本(一个视频序列)的loss是多帧loss的和。Loss分为Limg和Lgan。Limg又分为Lp和Lgdl,其中Lp用于指导网络去匹配像素均值(思考:若只匹配像素均值,容易让生成的图中出现模糊像素区域),Lgdl则是指导网络去匹配像素点像素值的梯度(和相邻像素点像素值的差),Lgdl弥补了一些Lp无法做到的生成清晰的轮廓或线条的能力。但由于Limg指导的是整个视频的生成(不是单帧),指导整个序列的平均也可能带来模糊的生成,所以作者又整了个GAN loss让生成的图片更真实。
![]()
![]()
为了测试MCNet和其他网络的性能差别,本文在不同的任务上使用了PSNR(峰值信噪比)和SSIM(结构相关性),
PSNR基于对应像素点间的误差,即基于误差敏感的图像质量评价。峰值信噪比的值越高越好。由于并未考虑到人眼的视觉特性(人眼对空间频率较低的对比差异敏感度较高,人眼对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围邻近区域的影响等),因而经常出现评价结果与人的主观感觉不一致的情况。
SSIM结构相关性试图比较失真图像和原图像的结构相似性,结构相似性的范围为0到1。当两张图像一模一样时,SSIM的值等于1。作为结构相似性理论的实现,结构相似度指数从图像组成的角度将结构信息定义为独立于亮度、对比度的,反映场景中物体结构的属性,并将失真建模为亮度、对比度和结构三个不同因素的组合。用均值作为亮度的估计,标准差作为对比度的估计,协方差作为结构相似程度的度量。SSIM可以较好地反映人眼主观感受。
Vid2Vid主要做的是视频转换工作,不过也可以用作生成视频(视频预测),文中也与MCNet进行了比较。vid2vid
vid2vid的architecture不能直接套用在视频预测上,因为vid2vid的输入视频和生成视频相邻帧之间有相同的时间相关性(flow)。文中用于视频预测任务时,是先使用一个语义生成网络,生成图片对应的segmentation mask,然后再使用vid2vid将其转换成真实图像,生成的图像反而能比MCNet好很多。我们来看看vid2vid中有哪些优秀的设计。
由于仍然是生成任务,所以网络仍然是Generator+Discriminator,使用特殊Loss来指导网络的学习。先来看Generator的结构。
该问题转化成一个条件概率问题:![]() ,即用source的T帧s生成需要的T帧x。
,即用source的T帧s生成需要的T帧x。
本文将该问题转化成: ,即对于第t帧的生成,使用之前生成的L帧和之前source的L帧+当前的source帧共L+1帧source。
,即对于第t帧的生成,使用之前生成的L帧和之前source的L帧+当前的source帧共L+1帧source。
比视频预测更简单的是,vid2vid的任务source和target图像具有相同的运动趋势和相同的结构特征。这里使用了光流信息来加强监督。Generator的公式如下:
![]()
 是使用网络预测t-1帧到t帧的光流,将光流与t-1帧图像结合,可以生成预测的第t帧的图像。其中预测光流的输入即网络W的输入为之前生成的L帧x和之前source的L帧+当前的source帧共L+1帧source。
是使用网络预测t-1帧到t帧的光流,将光流与t-1帧图像结合,可以生成预测的第t帧的图像。其中预测光流的输入即网络W的输入为之前生成的L帧x和之前source的L帧+当前的source帧共L+1帧source。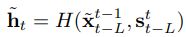 是网络H生成的图像,输入与光流的输入一致。
是网络H生成的图像,输入与光流的输入一致。- 同时,还有一个mask网络
 ,用于控制光流和生成图像的权重,用于对两种信息的权衡。
,用于控制光流和生成图像的权重,用于对两种信息的权衡。
在MCNet中,对于每个单元运动的信息的描述使用了当前帧图像和上帧图像的差作为输入,同时LSTM的结构可能能够保留一些更早之前的运动信息。而vid2vid中则是使用网络来生成最近L帧的光流信息。
vid2vid中的Discriminator也有特别的设计,除了与gt image进行真假比对Di(conditional image Discriminator)之外,还有视频级别的Discriminator Dv(conditional video Discriminator)。与MCNet中Discriminator直接输入整段视频不同的是,这里Dv的输入是近K-1帧图片的光流,生成值与实际值比较。
vid2vid的loss如下:
![]()
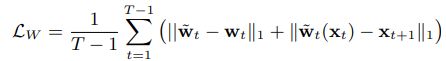
MCNet中使用Limg控制图像生成质量,使用GAN loss控制生成视频的真实度。而vid2vid这里对image单帧和视频都使用了GAN loss,且采用了随机采样的方法。
除此之外,添加了T-1帧的光流loss,且光流loss里使用了光流的L1 loss和光流变形后的图片L1 loss。
同时,为了提升训练的稳定性,辅助了VGG feature matching loss和Discriminator feature matching loss。
在使用segmentation mask视频作为输入时,还可以使用前景(行人、车)、背景(树、建筑)先验信息辅助生成:![]()
与MCNet的评价指标不同的是,本文选择了更有说服力的FID指标和人工评价的human preference socre。前者是使用一个中立的视频信息提取器同时提取生成视频和输入视频的视频信息(包括空间特征和时序特征),再通过公式计算二者相似度,这里的视频特征提取器选择了I3D 和ResNeXt两种。后者是人工比较该模型生成的视频和另外一个模型生成的视频哪个是真实视频。