【飞桨PaddlePaddle学习心得】被遗忘的8张图片(day2爬虫的王姝慧的问题)
问题描述:
在day2的《青春有你2》选手信息爬取任务中。标答给出的图片个数是482张,而且大部分的同学也爬去的是482张。
但是一位同学(在此手动@MR.GAO同学)由于代码的优秀(在此不得不提,try-catch是个好东西),竟然爬出了490张。并在群中提出了疑问。
原来问题出现在王姝慧的图册的问题上面。通过下面图册的编号可以发现,她有长达38张图片(不得不感叹一下,这图片也太多了吧,一切问题的根源就在这里)。
表达对于王姝慧这位选手的图片指爬去了30张,但是人家明明有38张呀,那么被遗忘的8张图片去了哪里呢。
题主就这个问题,进行了一番强势debug!!!

问题根源

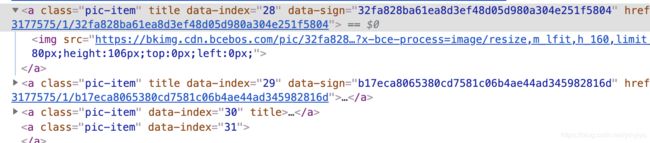
通过对源代码的查看,不难看出,该代码在渲染超过30张图片(序号从0开始)的时候,对于30张以后的图片的href是不会显示出来的,进一步尝试发现,从选中标号28即第29张图片的时候,标号30即第31张图片显示了出现。这里很明显是一个ajax的异步加载。从标号28开始,会加载出后面的两张图片。
代码分析
这里不得不说一句:真的一切的存在都是有原因的。其实题主之前自己的代码也是能够发现这个文题的,但是题主没有去深究他,遇到问题直接使用判空处理,然后为空就略过。
题主代码第一版
#题主代码第一版
for i in img_node_list:#img_node_list 为所有的a节点的列表
url = prifix+i['href']
img_url_list.append(url)
第一版在第二行报错,说有的i对象没有href的属性。当时还想报错时候的i给输出看了下,发现只有一个但是当时也没有多想,就以为是本来页面上就是为空的,也没有去网页上查看到底是为什么为空。所有就有了第二版的偷懒做法。
题主代码第二版
#题主代码第一版
for i in img_node_list:#img_node_list 为所有的a节点的列表
if 'href' in str(i):#
url = prifix+i['href']
img_url_list.append(url)
这一版就是直接判断i是否有href的属性,有的话就继续,没有的话就跳过,就因为这个偷懒,所有导致没有发现问题所在。
##MR.GAO同学的代码
for pic in pic_list:
try:
pic_url = 'https://baike.baidu.com' + pic.attrs['href']
except:
print('a对象没有href')
response = requests.get(pic_url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
src_target = soup.find('img', {'id': 'imgPicture'}).attrs['src']
pic_urls.append(src_target)
可以发现,该同学这里使用了一个try-except的方法进行了异常的捕获。第一眼看他的代码发现其实并没有找到后面的url呀,应该也是只能爬去30行图片,后面的8张图片是爬去不到的吧。但是该同学说自己是爬到了38张图片的。然后这就让我很迷了。都没有找到后面的url,是怎么把后面的图片爬到的呢?
带着这个问题,是这debug了一下他的代码,发现王姝慧选手文件夹下面真的有38张图片。(当时心里是瞬间感觉这段代码充满着恶意,感觉对他失去了控制)
带着不抛弃不放弃的心理,仔细看了一下图片,发现从30张开始 后面的9张都长一个样。
破案了!!!
原来,该同学由于代码的原因,即使后面的8个a元素没有href对象,但是被except捕获了没有报错,而且上一轮的pic_url也连续被使用了,所有从30-39的url都是同一个url,所有也就有了9个相同的图片,后面8个没有url的图片都被最后同一个有url的图片给替代了(备胎)
不过这个代码肯定是达不到将8个遗忘的图片找回来的功能的。所有题主在此进行了一番修改,力求把消失的8张图片找回来。
I got you
对代码做了改进,中心思想是在每一次打开图片的时候,都将页面中的pic-list节点下面的a元素统计进来,然后将其中href不为空并且没有在pic_list中出现过的a元素加进去
a_list_tmp = []
count1 = 0
for pic in pic_list:
if 'href' in str(pic):
a_list_tmp.append(pic)
pic_list = a_list_tmp
a_list_tmp = []
for pic in pic_list:
count2 = 0
count1 = count1 + 1
print(count1)
pic_url = 'https://baike.baidu.com' + pic.attrs['href']
response = requests.get(pic_url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
a_list_tmp = soup.find('div', {'class': 'pic-list'}).find_all('a')
if count1 == 29:
print(soup)
for a in a_list_tmp:
count2 = count2 + 1
print('******{}'.format(count2))
if 'href' in str(a) and a not in pic_list:
pic_list.append(a)
……
# 这样的话会讲每次选中的那个a元素再次添加进去,因为a元素被选中了就会添加一个selected的class
#所有最后得到了pic_urls后 还需要对其去重
pic_urls = set(pic_urls)
迷之尴尬的事情发生了
然而,事情并没有想像中的那么顺利,迷之前端在页面的时候如果当前点击的是28的图片,30的图片链接会出来,但是当查看源码的时候,其实链接并没有出来,很密很密。
图片为证:
选中29号图片后页面上的审查代码:
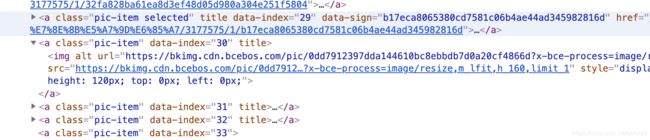
选中29号图片后源代码:

可以看到,在源代码中,30后面的图片的链接并没有出来。好迷好迷!!! (我来填坑了)
顶不住了,睡觉了!!!
未完待续!!!
可以确定后面的8张图片是通过ajax动态加载的,那么想到这个问题,第一个思路当然是打开强大的chrome浏览器的控制台查看network里面的请求了呀。所有有了下面的发现。
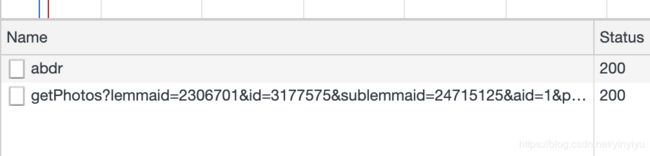

可以发现,当访问的图片从第22张开始的是多了一个getPhotos的请求。那么下一步就是分析这个请求拿到了什么。于是题主讲返回的json数据解析后进行了查看:
首先是张这样的,可以看到里面有8个src(这个数字好巧呀,看到这里心里好激动。)
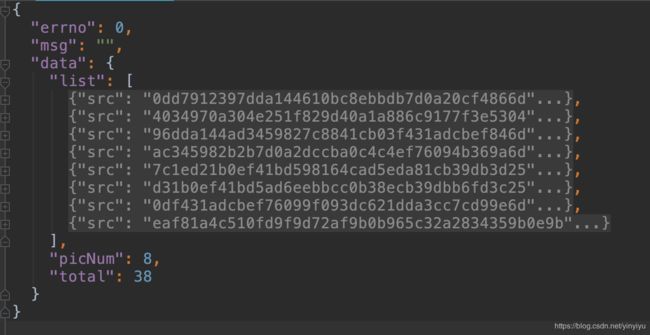
打开每一个src后可以发现:
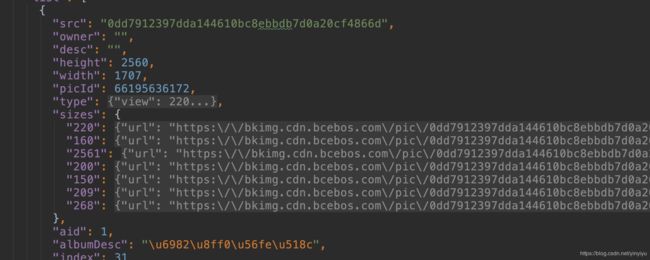
然后直接复制里面的链接打开,哇小姐姐出来了耶!(此处就不放小姐姐图片了。)
My Solution
如果图片数量超过30就模拟浏览器发送get请求得到动态加载的图片数据
#如果图片数量超过30就模拟浏览器发送get请求得到动态加载的图片数据
def crawl_json_data():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
url = 'https://baike.baidu.com/ajax/getPhotos?lemmaid=2306701&id=3177575&sublemmaid=24715125&aid=1&pn=30&rn=30'
getpic_response = requests.get(url, headers=headers).text
json_data = json.loads(str(getpic_response).replace("\'", "\""))
print(json_data)
with open('pic_res.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
然后在原本的代码中做如下修改,从json文件i里面找到高清图片的url添加到pic_urls里面就行了
if len(pic_list)>30:
#如果图片的个数大于30 则模拟浏览器发送请求 然后解析json拿到剩下的图片的链接
crawl_json_data()
#解析json
with open('pic_res.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
lists_list = json_array['data']['list']
for li in lists_list:
#会发现list节点下面的第三个元素是最大图片的链接
#通过下标访问json 自己写
count = 0
for key in li['sizes']:
count+=1
if count == 3:
key_2 = key
img_bg_url = li['sizes'][key_2]['url']
print(img_bg_url)
pic_urls.append(img_bg_url)
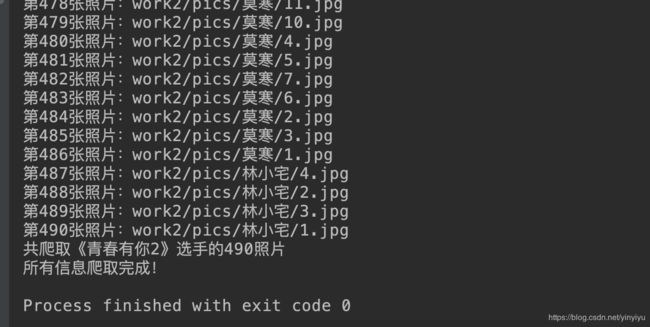
至此 这个由8张消失的图片引出的一个坑终于被自己使用一种偷懒的方法解决了!!!
最终效果图(490张 不带重复的图片)