一种解决Impala自定义属性查询的方案
背景
在使用Impala做自助分析的过程中,我们经常发现自定义属性的需求,通常情况下用户会将这种不确定key的字段全部塞到一个MAP字段中,然后通过Impala的复杂结构查询语法进行查询,目前Impala只支持Parquet格式表的schema中使用复杂数据类型(包括STRUCT、ARRAY和MAP),查询语法可以参考 Impala复杂类型语法,但是它存在两个弊端:语法不兼容hive和查询性能不理想。第一个问题是由于特定的实现方式导致的,第二个问题则是由于parquet存储MAP类型的字段决定的。那么有没有办法提升用户的这种查询需求和简化查询SQL的写法呢?
JSON UDF VS. MAP
为了避免MAP在impala中复杂的使用方式和性能不好的问题,我们一般建议使用JSON字符串的方式代替map存储表达的字段内容,毕竟json能够完全表示出MAP的语义,而开发一般使用JAVA实现,也比较方便生成JSON格式的数据。通过使用json解析的UDF来抽取其中想要的字段,我们首先使用了一个开源的JSON UDF的实现 ,这个开源的实现使用了rapidjson作为json解析器,它的使用方法类似于hive的get_json_object,函数定义如下:
STRING get_json_object(STRING, STRING)
第一个参数为输入的json字符串,第二个参数是需要解析的内容,该内容通过如下方式解析:
- $ : Root object(表示根节点)
- . : Child operator(表示父节点和子节点的分隔符)
- [] : Subscript operator for array(访问数组)
-
- : Wildcard for [] (通配符)
例如对于一个{“hello”, “world”}的JSON字段(字段名为col)想要提取hello的值,可以使用get_json_object(col, “$.hello”)得到的值就是”world”。
通过它可以提取map中想要的字段,它的实现原理是用rapidjson解析输入的第一个参数,解析成Document之后再通过解析第二个参数选取想要的字段内容,通过对比测试原生map的查询和使用这个UDF进行测试的结果如下:
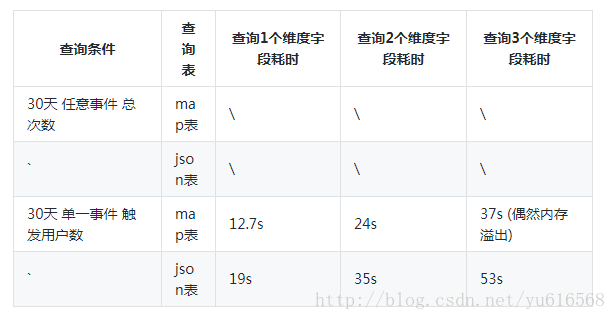
测试发现json自定义函数的性能并不如原生map查询的性能,我认为主要是基于两方面的原因:
- 使用json字符串需要读取更多的数据,根据profile可以看到JSON格式的列要比map多读取一倍的数据量。
- 每一个JSON列都需要解析转换成Document对象,解析过程中rapidjson不可避免的又会进行一些数据拷贝操作,整个解析的代价是比较大的。
JSON UDF优化
意识到该问题之后,我们就需要想办法减少如上两个方面的开销,首先对于存储空间的减少,但是对于json的结构,内容是相对比较规定的,这点不容易优化,而第二点,我们是否能够在不解析整个json字符串就获取到想要的结果呢?假设它不是一个json字符串,而是一个key:value的存储格式,我们可以轻松的顺序查找,找到对应的key就直接返回value的,按照这个思路,我们自己涉及了一种解析JSON的逻辑,基于如下的状态机:
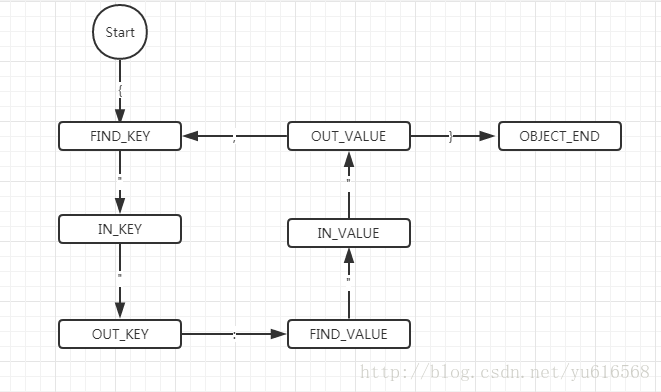
这是一个对于一层结构的JSON的字符串进行解析的状态机(也不考虑数组),将这个字符串遍历分为多个状态,例如当从字符串开始遇到‘{’字符就将状态转换为FIND_KEY,进行查找key的操作,当遇到双引号表示已经找到了key,此时我们就可以将找到的key与输入的key进行比较,如果相同则下一个找到的value就是查找的结果,这样的做法将JSON的解析转换成了一个关键字查找的过程,平均时间复杂度大大降低,添加该UDF进行测试发现如下的对比结果:

通过测试结果可以发现,随着查询的关键字个数的增加两者都是X + N * Y(N是关键字的个数),其中MAP表的Y = 13s,新的JSON UDF的Y大于等于7s,这意味着随着查找关键字个数的增长,查询性能有了大约45%的提升,这也意味着我们减少查询平均时间复杂度的做法是可行的,但是这种方案的查询时间复杂度仍然是O(n),有没有什么办法进一步提升查询性能呢?
优化的存储结构
将之前JSON格式的查询问题转换成字符串查找问题之后,思路就可以放宽了,我们都知道在查找算法中有两种实现的性能比较好,分别是哈希表和二分查找树,这也对应着Map的两种实现,我们是否可以将需要写入的key:value转换成这样的格式呢?但是看着这样复杂的结构序列化和反序列化都是一个比较头大的问题,除了这两个数据结构,我们还知道二分查找的性能最快情况下是O(log N),那我们能不能使用二分查找呢?
先来分析一下二分查找的两个前提条件:
- 待查找的值必须是有序的。
- 待查找的值必须能够随机访问(随机访问意味着访问任意一个key的时间复杂度都是O(1))。
对于第一个条件我们比较熟悉,因为二分查找都是通过数组来实现存储的,数组的每一个元素都是可以随机访问的,这意味着我们可以通过arr [(high + low) / 2]访问下一个比较的元素。但是输入的key和value都是未知大小的,我们需要根据key进行比较,难不成要将所有的key都存储成一样的大小?这样意味着所有的key都需要存储成最大的key的长度,浪费了不少存储空间,最终我们选择这样一种二进制的存储格式:
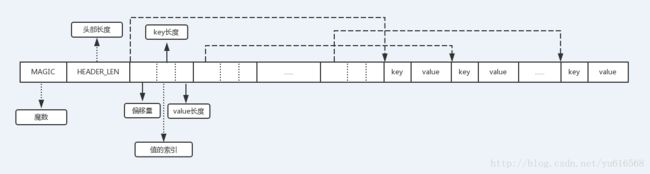
通过这样的结构,我们将key:value转换成一个定长的索引信息,整个结构从前往后包括如下几部分:
- Magic Number:魔数,用于标记该值是否是可识别的存储格式,4个字节
- HEADER_LEN:标记该结构中存储的key:value值的个数,如果预定义该结构最大的值数量为65535,只需要2个字节。
- 值的索引数组:每一个值通过固定大小的索引来表示,它包含三部分:偏移量(表示当前key的偏移量,对一个key从0开始,第二个key的偏移量等于第一个key长度+value长度,依此类推,2个字节或者4个字节);key的长度(如果key的大小限定在256字节,只需要1个字节);value的长度(value的偏移量可以通过该值的偏移量+key的长度计算,1个字节或者2个字节)。
- 真正的key和value对,key和value连续存储。
这样除了真正的key和value的值,额外需要4 + 4 + (4 + 2 + 2) * N的存储空间存储索引信息(为了保持8字节对齐可以扩大成8 * (N + 1)字节),其中N等于key/value对的个数。这种格式可以存储多大65536个key/value对,每一个key和value的最大长度为65536字节。
从上面的JSON和MAP对比测试可以发现数据量的增大并不是性能变慢的主要原因(优化之后的JSON UDF同样需要读取两倍的数据量,但是性能提升了许多),因此这种存储上的浪费是可以接受的。而采用了新的存储结构,可以使得查询的时间复杂度从O(N)提升到O(log N),那么对于写入和查询的流程又需要做哪些额外的工作呢?
写入端(Java端):
- 写入的时候需要首先将key进行排序(放入到一个TreeMap中)。
- 分别构造出每一段,最后通过UDF-8编码成byte数组写入(不像JSON有现成的库使用)。
读取端(C++ UDF):
- 读取的时候首先读取前4个字节,判断魔数是否等于预定义的值,如果不等于直接返回错误。
- 读取第二个4字节,获取成员的个数,该值也就是后面数组的大小。
- 读取第三部分索引数组,根据二分查找的算法,定位到最中间的索引内容(偏移量、key的长度),然后和待查找的值进行比较,指导查找结束。
- 如果没有找到则返回NULL,找到该key根据偏移量、key长度和value的长度计算出value的偏移量和长度返回。
进一步扩展和优化
有了这样的一个存储结构,是否可以再进行进一步的优化呢?答案是肯定的,在二分查找的过程中,最坏情况下的时间复杂度是O(log N),是当待查找的值不存在的情况,是否有更高效的方案判断一个key是否存在呢,如果不存在则可以直接返回NULL了,于是想到了Bloom Filter算法,它存在一定的误差,但是具有如下的特性:
- 它判断一个key不存在,那么这个key肯定不存在。
- 它判断一个key存在,那么这个key可能不存在。
这个特性正好能够符合我们的需求,因此可以考虑在MAGIC和HEADER_LEN部分中间插入计算好的bloom filter信息,但是这个是否值得还需要进一步测试对比,因为引入了Bloom Filter会增大了计算的开销(虽然Bloom Filter的计算只是几个哈希函数的计算),如果待查找的key在大部分情况下(例如90%)都是能够找到的,那么这个开销就有点得不偿失;如果待查找的key大多数情况下是不存在的,这种开销可以大大提升查询的性能。
但是上面的结构只表示除了单层的key/value结构,这和json表示的语义是有差别的,怎么协调这种差别呢?其实在JSON中无外乎两种嵌套结构,一种是MAP一种是ARRAY,假设MAP中的key不包含字符’.’,我们可以将子节点通过’.’和父节点进行连接,转换成扁平的格式,数组同样,可以通过父节点的名字和数组下表将其转换成扁平结构。如下:
{
"name" : "yu",
"location" : {
"province" : "ZZ",
"city" : "HZ"
},
"education" : ["ABC", "DEF", "GH"]
}
可以转换成name = yu,location.province = ZZ, location.city = HZ, educaion.0 = ABC, education.1 = DEF education.2 = GH 这样扁平的结构存储在上面提到的结构中,查询的时候也根据需要查询的节点路径输入就可以解决了。
总结
本文我们对比了impala中原生MAP和使用JSON UDF的方法进行不确定属性字段的查询,然后提出了一种新的基于关键字查找的方案提升了JSON字段内容解析的性能,并比原生的MAP有了将近50%的性能提升,但是我们没有止步于此,而是探索出一种特定的可以实现二分查找的存储结构,使用这种结构可以使用二分查找来完成属性的查找,并提出进一步基于Bloom Filter的优化方案。最终结果有待于进一步的对比测试。