命名实体识别NER-bilstm+crf
文章目录
- 1.数据预处理
- 1.1 整理数据,划分数据集
- 1.2 构建字典
- 1.3 构建标签字典
- 2.流程
- 2.1 网络架构图
- 2.2 代码架构图
- 3.运行
- 4.部分函数详解
- 4.1 训练阶段数据大小
- 4.2 CRF层的输入和输出是什么样子的
- 4.3 demo中utils.get_entity的输入和输出是什么样子的
- 5.实验结果
学习对象: https://github.com/Determined22/zh-NER-TF
基于字向量的BiLSTM+CRF实体识别方法,输入的是句子中各个字的char embedding,char embedding可以是随机初始化的,也可以通过预训练语言模型获取,本实验中char embedding是以随机初始化方式获得;输出的是经过BiLSTM-CRF模型得到的每个单词对应的预测标签。
本文主要介绍如何整理数据集,定义实体类别,训练出实体识别模型,可根据需求自定义实体类别,按特定格式标记数据,实现不同领域的实体识别。本文以BiLSTM-CRF模型在两类数据上训练与测试为例,验证模型效果。
1.数据预处理
1.1 整理数据,划分数据集
数据格式:数据集以BIO格式进行标记,每一行由char和标签组成,char和标签之间以“\t”隔开,且句子与句子之间用空行隔开。
BIO标注:将每个元素标注为“B-X”、“I-X”或者“O”。其中,“B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头,“I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间位置,“O”表示不属于任何类型。
如下图两个标注示例,图(A)是人名、地名、机构名三类实体识别的数据标注示例,图(B)是电子病历中识别身体部位、症状、治疗等实体的数据标注格式。

1.2 构建字典
根据训练集数据,将每个字映射为唯一的id,加入入’’, ‘’, ‘’, ‘’,分别表示填充字符,未知字符,数字字符和英文字符,同时限定字典大小,本实验中将训练集中出现3次以上的字存入字典。
例如:人名、地名、机构名识别中字典存储了4312个单词
![]()
1.3 构建标签字典
整理数据集中存在的标签转化为固定的数字标记,下图以人名、地名、机构名识别为例。
![]()
2.流程
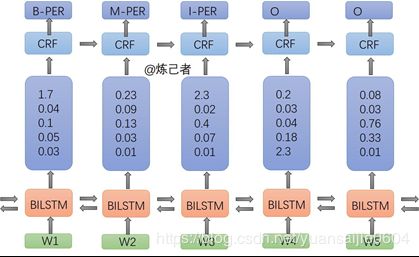
2.1 网络架构图

For one Chinese sentence, each character in this sentence has / will have a tag which belongs to the set {O, B-PER, I-PER, B-LOC, I-LOC, B-ORG, I-ORG}.
- The first layer, look-up layer, aims at transforming each character representation from one-hot vector into character embedding. In this code I initialize the embedding matrix randomly and I know it looks too simple. We could add some language knowledge later. For example, do tokenization and use pre-trained word-level embedding, then every character in one token could be initialized with this token’s word embedding. In addition, we can get the character embedding by combining low-level features (please see paper[2]'s section 4.1 and paper[3]'s section 3.3 for more details).
- The second layer, BiLSTM layer, can efficiently use both past and future input information and extract features automatically.
- The third layer, CRF layer, labels the tag for each character in one sentence. If we use a Softmax layer for labeling, we might get ungrammatic tag sequences beacuse the Softmax layer labels each position independently. We know that ‘I-LOC’ cannot follow ‘B-PER’ but Softmax doesn’t know. Compared to Softmax, a CRF layer can use sentence-level tag information and model the transition behavior of each two different tags.
2.2 代码架构图

3.运行
train python main.py --mode=train
test python main.py --mode=test --demo_model=1521112368
demo python main.py --mode=demo --demo_model=1521112368
4.部分函数详解
4.1 训练阶段数据大小
train_data 有50658条语句,有3905个不同的字
batches = int(50658/64)+1=792 64为自定义的batch_size
在运行完batch_yield函数后查看每个batch的数据

此时的数据是长度不一的
经过self.get_feed_dict调用 pad_sequences 来统一训练句子的长度
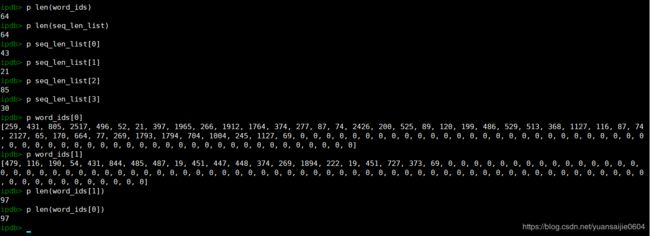
可见现在的句子长度都是97,但仍然有一个参数 seq_len_list 记录着句子原本的长度。
这个参数要传给 tf.nn.bidirectional_dynamic_rnn 和 crf_log_likelihood
4.2 CRF层的输入和输出是什么样子的

4.3 demo中utils.get_entity的输入和输出是什么样子的
demo例子:于大宝的进球帮助中国队在长沙贺龙体育中心以1-0的比分获胜
def demo_one(self, sess, sent):
label_list = []
for seqs, labels in batch_yield(sent, self.batch_size, self.vocab, self.tag2label, shuffle=False):
# seqs:[[273, 55, 1071, 8, 430, 1912, 1092, 7, 52, 21, 569, 73, 14, 2065, 2405, 600, 922, 451, 52, 237, 134, 94, 3904, 94, 8, 805, 786, 725, 831]]
# labels:[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
label_list_, _ = self.predict_one_batch(sess, seqs)
label_list.extend(label_list_)
label2tag = {}
for tag, label in self.tag2label.items():
label2tag[label] = tag if label != 0 else label
tag = [label2tag[label] for label in label_list[0]]
# tag:['B-PER', 'I-PER', 'I-PER', 0, 0, 0, 0, 0, 'B-ORG', 'I-ORG', 'I-ORG', 0, 'B-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 0, 0, 0, 0, 0, 0, 0, 0, 0]
return tag
def predict_one_batch(self, sess, seqs):
feed_dict, seq_len_list = self.get_feed_dict(seqs, dropout=1.0)
if self.CRF:
logits, transition_params = sess.run([self.logits, self.transition_params],
feed_dict=feed_dict)
# logits的大小是[1,29,7],29是句子长度,7是类别数目
# transition_params的大小是[7,7]
label_list = []
for logit, seq_len in zip(logits, seq_len_list):
viterbi_seq, _ = viterbi_decode(logit[:seq_len], transition_params)
label_list.append(viterbi_seq)
# label_list:[[1, 2, 2, 0, 0, 0, 0, 0, 5, 6, 6, 0, 3, 4, 4, 4, 4, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
# seq_len_list:[29]
return label_list, seq_len_list
else:
label_list = sess.run(self.labels_softmax_, feed_dict=feed_dict)
return label_list, seq_len_list
输入:
![]()
输出:

5.实验结果
测试集中共有实体15883个,用该模型识别出16164个实体,其中识别的正确实体个数为14310,整体准确度在89.31%,具体评价结果如下表所示。
| 人名、地名、机构名识别 | 准确率(P) | 召回率(R) | F值 |
|---|---|---|---|
| 整体 | 88.53% | 90.10% | 89.31% |
| LOC | 86.80% | 90.20% | 88.47% |
| ORG | 84.12% | 84.36% | 84.24% |
| PER | 94.92% | 94.51% | 94.71% |
电子病历实体识别
医疗领域电子病历中治疗方式、身体部位、症状、疾病、医学检查五类实体识别,测试集中共有实体7080个,用该模型识别出7138个实体,其中识别出的正确实体个数为5687,整体准确度为80%,具体评价结果如下表所示。
| 电子病历 实体识别 | 准确率(P) | 召回率(R) | F值 |
|---|---|---|---|
| 整体 | 79.67% | 80.32% | 80.00% |
| BODY(身体部位) | 80.90% | 82.09% | 81.49% |
| CHECK(检查) | 31.43% | 28.82% | 30.07% |
| DISEASE(疾病) | 90.23% | 92.32% | 91.27% |
| SIGNS(症状) | 75.56% | 74.40% | 74.97% |
| TREATMENT(治疗) | 57.75% | 67.58% | 62.28% |