Netflix: VMAF 视频质量评价工具简介
来源
160606 VMAF:Toward A Practical Perceptual Video Quality Metric
概要
这篇文章是Netflix主观质量评价工具VMAF的介绍文章。文章包含以下方面:
- 构建自家数据集的必要性;
- 分析传统质量评价工具PSNR/SSIM的问题,结合VQA(视频质量评价)领域的研究成果,选取3个主要评价指标:保真度、细节丢失和运动是三个指标;通过训练主观评价打分结果,最终得到一套针对自家数据集的基于以上三个指标的评价模型;
- 按照SRCC, PCC和RMSE等指标评价工具,对VMAF的表现进行测试。
存在问题:VMAF主要问题是其结果非绝对指标,不同视频、不同分辨率的VMAF得分不能直接比较。
译文
打造实用的视频流媒体质量评估工具
Zhi Li, Anne Aaron, Ioannis Katsavounidis, Anush Moorthy and Megha
Manohara 译者:大愚若智Netflix极为看重视频质量,我们也非常重视在大规模环境中精确衡量视频质量的方法。为了反应观众在欣赏视频流播服务时获得的画面质量,我们采用了一种名为Video Multimethod Assessment Fusion(VMAF)的方法。目前该工具已开源,我们邀请广大研究人员就这个重要项目展开合作。
对高质量视频的不断探索
我们致力于为会员提供最佳观赏体验:流畅的视频播放过程,赏心悦目的画质。为了实现这一目标,我们的一个主要方式是不断努力通过各种成果完善自身服务,为不同网络带宽下使用各种设备的会员提供尽可能出色的观赏质量。
我们在视频编码领域进行了大量创新。为了以合理的码率进行流播,流媒体视频需要通过标准化的格式进行压缩,例如H.264/AVC、HEVC以及VP9。如果视频过度压缩或压缩参数不当,这些技术将导致画面质量受损,也就是很多人常说的压缩失真。专家通常会将这种现象称之为“块效应(Blocking)”、“振铃效应(Ringing)”或“蚊式噪声(Mosquito noise)”,但是就普通观众来说,只会感觉视频看起来怪怪的。因此我们会定期对不同编码器供应商的压缩效率、稳定性以及性能进行对比,并根据结果选用业界最佳解决方案。我们会研究不同视频编码标准,以确保始终使用最先进的视频压缩技术。例如,我们会对H.264/AVC、HEVC和VP9进行比较,而不远的将来还打算针对Alliance for Open Media(AOM)和Joint Video Exploration Team(JVET)开发的下一代编码器开展相关实验。就算成熟的标准,为了能更充分地运用现有工具,我们也会继续尝试使用不同的配置选项(可参阅:Per-Title Encode Optimization)和速率分配算法。
我们会使用一种分布式的云端媒体管线对Netflix视频流进行编码,这样即可通过伸缩满足业务需求。为了将错误的源交付、软件Bug,以及云实例的不可预见性(临时出错)等问题的影响降至最低,我们在整个管线的多个点位部署了自动化的质量监控机制。通过这样的监控即可在从原始素材进入系统到管线中传输过程的每一点检测出视频质量问题。
随着Netflix生态体系的中诸多领域(例如Adaptive Streaming或CDN)的不断迭代以及A/B测试的进行,我们会尽力完善整个系统以维持并改善视频质量。例如,自适应流播算法中的一项改进可降低视频开始播放前的缓冲时间,同时确保了流播过程中重新缓冲不会导致视频整体质量降级。
上述所有努力都立足于一个最基本的前提:我们可以精确高效地衡量大规模环境中流播视频质量的观感。以往在视频编码器的开发和研究领域主要使用两种方法衡量视频质量:1) 视觉主观测试,以及2) 对PSNR以及最新提出的SSIM等简单指标进行计算。
毫无疑问,以我们生产环境的吞吐率、A/B测试监控、以及编码技术研究实验等工作来说,以人工方式进行视觉检查无论在可行性或经济性方面都是不现实的。图像质量的衡量是个老问题,对此人们提出过很多简单可行的解决方案。例如: 均方误差(Mean-squared-error,MSE)、峰值信噪比(Peak-signal-to-noise-ratio,PSNR)以及结构相似性指数(Structural Similarity Index,SSIM),这些指标最初都是被设计用于衡量图像质量的,随后被扩展到视频领域。这些指标通常会用在编码器(“循环”)内部,可用于对编码决策进行优化并估算最终编码后视频的质量。虽然这一领域的研究人员和工程师都很清楚PSNR无法始终如一地反应出人的观感,但这一指标依然成为编码器对比和编码器标准化工作中约定俗成的标准。构建Netflix-Relevant的数据集
在评估视频质量评价算法的过程中我们使用了一种数据驱动的方法。第一步需要收集与我们的具体用例密切相关的数据集。虽然针对视频质量指标的设计和测试已经有可以公开使用的数据库,但这些数据库的内容缺乏多样性,而多样性正是Netflix这种流媒体服务的最大特点。很多数据库在源素材和编码后结果的质量方面也不是最先进的,例如其中还包含标清分辨率(SD)内容或只涵盖一些比较老的压缩标准。由于视频质量的评估远不仅仅是压缩失真的评估,现有数据库会试图考虑更广范围的画质损失,不仅有压缩导致的损失,还有传输过程中的损失、随机噪声,以及几何变形等情况。例如实时传输的监控视频通常是黑白画面的低分辨率视频(640x480),观看这些内容时的体验与坐在客厅欣赏喜爱的Netflix节目时的体验就截然不同。
在设计能精确反应流播视频质量观感的指标过程中,Netflix的流播服务为我们造成了一系列独特挑战和机遇,例如:视频源的特征 : (high-level的内容特征 vs low-level的编码特征 )
Netflix提供了适合各类人群观看的大量影视内容,例如儿童内容、动漫、快节奏动作片、包含原始视频的纪录片等。另外这些内容还呈现出多样化的底层源素材特征,例如胶片颗粒、传感器噪声、计算机生成的纹理、连续黑暗场景或非常明亮的色彩等。过去制定的很多质量指标并未充分考虑到不同类型的源内容。例如,很多现有数据库中缺乏动漫内容,大部分数据库并未考虑胶片颗粒,而在专业娱乐内容中这些都是非常普遍的信号特征。
失真(artifact)的来源。Netflix流播视频是通过强壮的传输控制协议(TCP)传输的,丢包和误码绝对不会导致视觉损失。这就使得编码过程中的两类失真最终影响到观众所感受到的体验质量(QoE):压缩失真(由于有损压缩)以及缩放失真(为了降低码率,压缩前会下采样,随后又会在观众的设备上采样)。通过专门针对压缩和缩放失真制定质量指标,牺牲普遍性换来精确性,即可获得在效果上超越通用指标的精确度。
为了针对Netflix的用例构建更有针对性的数据集,我们选择了34个源短片作为样本(也叫做参考视频),每个短片长度6秒,主要来自Netflix提供的流行电视剧和电影,并将其与一系列公开发布的短片相结合。源短片包含具备各种高级特征high-level feature(动漫、室内/室外、镜头摇移、面部拉近、人物、水面、显著的物体、多个物体)以及各种底层特性low-level characteristics(胶片噪声、亮度、对比度、材质、活动、颜色变化、色泽浓郁度、锐度)。我们将这些源短片编码为H.264/AVC格式的视频流,分辨率介于384x288到1920x1080之间,码率介于375kbps到20,000kbps之间,最终获得了大约300个畸变(Distorted)视频。这些视频涵盖了很大范围的视频码率和分辨率,足以反映Netflix会员多种多样的网络环境。
随后我们通过主观测试确定非专业观察者对于源短片编码后视频画质损失的评价。在标准化的主观测试中,我们使用了一种叫做双刺激损伤评价法(Double Stimulus Impairment Scale,DSIS)的方法论。参考视频和畸变视频将按顺序显示在家用级别的电视机上,并且我们对电视机周围的环境光线进行了控制(按照ITU-R BT.500-13 [2]的建议进行)。如果畸变视频编码后的分辨率小于参考视频,则会首先放大至源分辨率随后才显示在电视上。观察者坐在类似客厅的房间沙发上,需要针对画质损失给出1(非常恼人)到5(完全不可察觉)分的评价。将所有观察者针对每个畸变视频的分数汇总在一起计算出微分平均意见分数(Differential Mean Opinion Score)即DMOS,并换算成0-100的标准分,其中100分是指参考视频的分数。本文会将参考视频、畸变视频,以及观察者给出的DMOS分数作为整体称之为NFLX视频数据集。传统的视频质量指标
传统的,已经被广泛使用的视频质量指标与NFLX视频数据集中所包含的“人工校正”后的DMOS分数之间有什么关联? 一个直观的例子
上图可以看到从4个不同畸变视频截取出的静态画面的局部内容,上方两个视频检测出其PSNR值为大约31dB,下方两个的PSNR值约为34dB。人们很难察觉“人群”视频有何差异,但两个“狐狸”视频的差异就很明显了。人类观察者针对两个“人群”视频给出的DMOS分数分别为82(上方)和96(下方),而两个“狐狸”视频的DMOS分数分别为27和58。详细结果
下图显示的散点图中X轴对应了观察者给出的DMOS分数,Y轴对应了不同质量指标预测的分数。这些散点图是从NFLX视频数据集中挑选部分信息创建的,我们将其标注为NFLX-TEST(详情见下节)。每个点代表一个畸变视频。我们为下列四个指标绘制了散点图:
* PSNR亮度分量(Luminance component)
* SSIM [3]
* Multiscale FastSSIM[4]
* PSNR-HVS [5]
有关SSIM、Multiscale FastSSIM以及PSNR-HVS的详细信息请参阅脚注部分列出的参考文献。对于这三个指标我们实现基于Daala代码[6]中的实现,因此图表中的标题以“Daala”作为前缀。
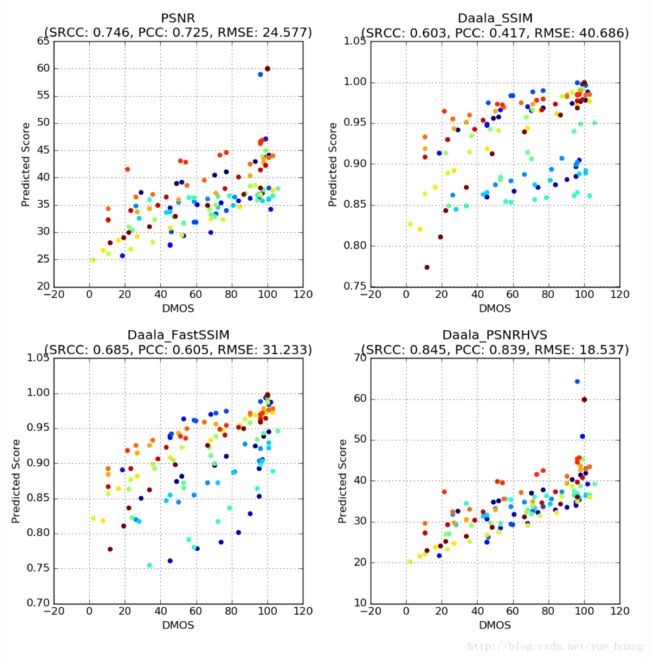
注意:相同颜色的点对应了畸变视频和相应参考视频的结果。由于个体差异和参考视频需要换算成标准化的100分成绩,一些DMOS分数可能会超过100。
从图中可以看出,这些指标的分数与观察者给出的DMOS分数并非始终一致。以左上角的PSNR图为例,PSNR值约为35dB,而“人工校正”的DMOS值的范围介于10(存在恼人的画质损失)到100(画质损失几乎不可察觉)之间。SSIM和Multiscale FastSSIM指标也存在类似情况,接近0.90的分数对应的DMOS值介于10到100之间。
指标的准确度评价:SRCC/PCC
在上述每个散点图中,我们发现每个指标的斯皮尔曼等级相关系数(Spearman’s rank correlation coefficient,SRCC)、皮尔森积差相关系数(Pearson product-moment correlation coefficient,PCC)以及均方根误差(Root-mean-squared-error,RMSE)数值经过非线性逻辑拟合(Non-linear logistic fitting)计算后的结果符合ITU-R BT.500-13 [7]标准中3.1条款的概括。我们希望SRCC和PCC值接近1.0,RMSE值接近0。在这四个指标中,PSNR-HVS的SRCC、PCC和RMSE值是最理想的,但依然缺乏预测精度。
为了针对不同种类的内容实现一套有意义的评价标准,所用指标必须能呈现出较为理想的相对质量分数,例如指标中的增量(Delta)应该能体现出观感质量的增量。下图中我们选择了三个典型的参考视频:一个高噪声视频,一个CG动漫,以及一个电视剧,并用每个视频的不同畸变版本的预测分数与DMOS分数创建散点图。为了获得有效的相对质量分数,我们希望不同视频短片在质量曲线的相同范围内可以实现一致的斜率(Slope)。例如在下方的PSNR散点图中,在34dB到36dB的范围内,电视剧PSNR数值大约2dB的变化对应的DMOS数值变化约为50(50到100),但CG动漫同样范围内类似的2dB数值变化对应的DMOS数值变化低于20(40到60)。虽然CG动漫和电视剧短片的SSIM和FastSSIM体现出更为一致的斜率但表现依然不够理想。
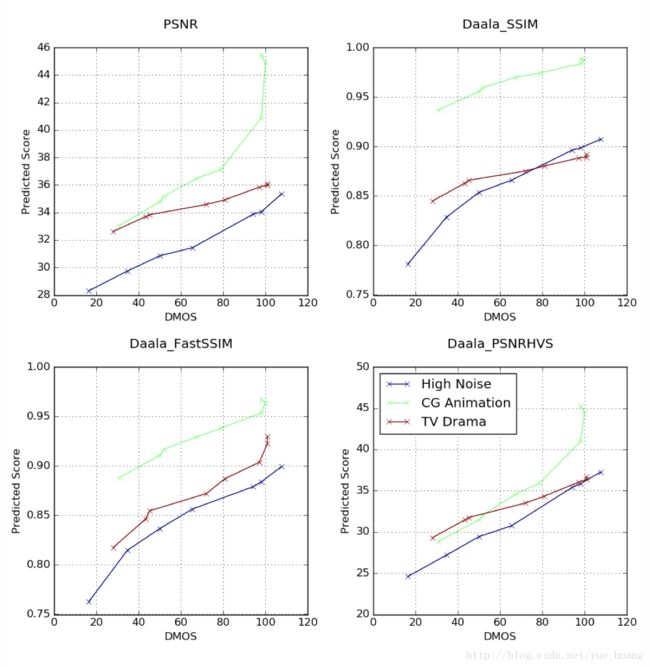
简单总结来说,我们认为传统指标不适合我们的内容。为了解决这一问题,我们使用了一种基于机器学习的模型设计能真实反映人对视频质量感知情况的指标。下文将介绍这一指标。我们的方法:Video Multimethod Assessment Fusion(VMAF)
通过与美国南加州大学[8] [9]的C.-C. J. Kuo教授以及他的团队合作,我们研究开发了视频多方法评估融合(Video Multimethod Assessment Fusion,VMAF),这种方式可以将多种基本的质量指标结合在一起预测主观质量。这种方法的基本想法在于,面对不同特征的源内容、失真类型,以及扭曲程度,每个基本指标各有优劣。通过使用机器学习算法(我们在本例中使用了支持向量机(Support Vector Machine,SVM)回归因子)将基本指标“融合”为一个最终指标,可以为每个基本指标分配一定的权重,这样最终得到的指标就可以保留每个基本指标的所有优势,借此可得出更精确的最终分数。我们还使用主观实验(本例中使用了NFLX视频数据集)中获得的意见分数对这个机器学习模型进行训练和测试。
VMAF算法和模型的最新版本(VMAF 0.3.1)已包含在VMAF开发包中并以开源软件的形式发布,可在支持向量机(SVM)回归因子中使用下列基本指标进行融合[10]:
1. 视觉信息保真度(Visual Information Fidelity,VIF)[11]。VIF是一种获得广泛使用的图像质量指标,该指标基于这样一种前提:质量与衡量信息保真度丢失情况的措施是互补的。在最初的形式中,VIF分数是通过将四个尺度(Scale)下保真度的丢失情况结合在一起衡量的。在VMAF中我们使用了一种改进版的VIF,将每个尺度下保真度的丢失看作一种基本指标。
2. 细节丢失指标(Detail Loss Metric,DLM)[12]。DLM是一种图像质量指标,其基本原理在于:分别衡量,可能影响到内容可见性的细节丢失情况,以及可能分散观众注意力的不必要损失。(描述失真的两个指标)这个指标最初会将DLM和Additive Impairment Measure(AIM)结合在一起算出最终分数。在VMAF中我们只使用DLM作为基本指标,但也对一些特殊情况采取了必要的措施,例如会导致原始公式中的数值计算失效的黑帧。
VIF和DLM都是衡量图片质量的指标。考虑到视频的时域特性(Temporal characteristic),我们还进一步引入了下列这些特性:
3. 运动量。这是一种衡量相邻帧之间时域差分的有效措施。计算像素亮度分量的均值反差即可得到该值。
经过多次测试和验证作为迭代,我们最终选择了使用这些基本指标和特性。
我们将VMAF与上文提到的其他几个质量指标的精确度进行了对比。为保持公平,避免将VMAF过拟合(Overfitting)到数据集,我们首先将NFLX数据集拆分为两个子集,分别名为NFLX-TRAIN和NFLX-TEST。这两个子集不包含相同的参考短片。随后使用SVM回归因子通过NFLX-TRAIN数据集进行训练,并针对NFLX-TEST进行测试。下列散点图是使用NFLX-TEST数据集对所选参考短片(高噪声视频、CG动漫、电视剧)得出的VMAF指标分数。为了方便对比,我们也附上了上文提到的结果最理想的PSNR-HVS指标散点图。无疑VMAF的效果更好。

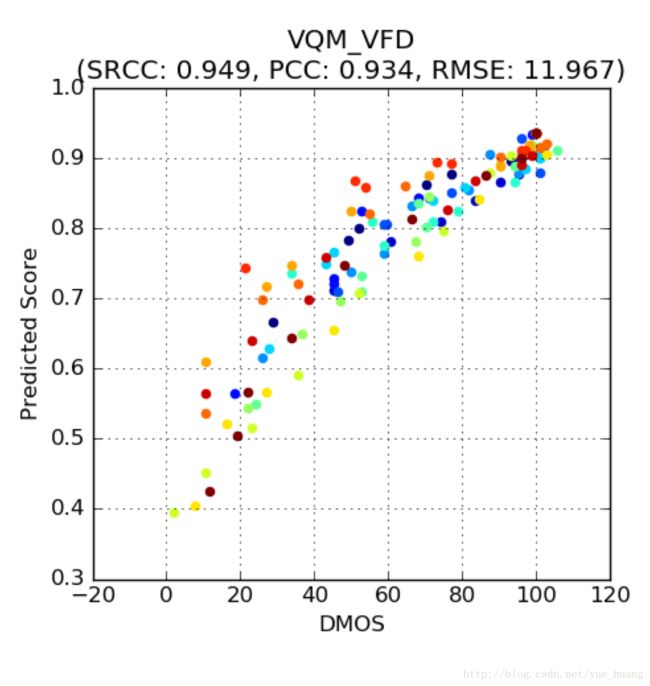
我们还将VMAF与该领域内目前公认最先进的具有可变帧延迟的视频质量模型(Video Quality Model with Variable Frame Delay,VQM-VFD)[13]进行了对比。VQM-VFD是一种使用神经网络模型将底层特性融合得到最终指标的算法。思路方面该方法与VMAF类似,但这种方式更偏重空间和时间坡度等更底层的特性。
毫无疑问,在NFLX-TEST数据集的测试中,VQM-VFD的效果非常接近VMAF。由于VMAF方法可以更容易地将新增的基本指标纳入框架中,VQM-VFD也可以直接成为VMAF的一个基本指标。
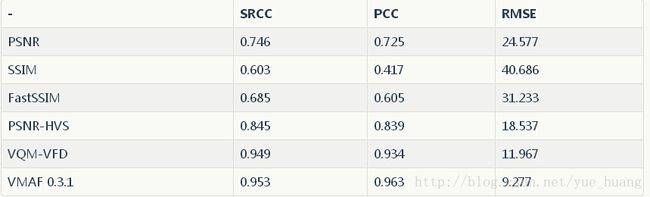
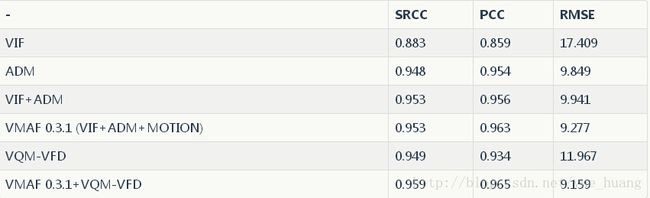
下表列出了针对NFLX-TEST数据集,将不同基本指标结合在一起通过VMAF模型获得的SRCC、PCC和RMSE数值,以及VMAF 0.3.1的最终分数。另外我们还列出了通过VQM-VFD增强后的VMAF效果。结果证明了我们最初的设想:将能够提供最佳表现的质量指标以智能的方式融合在一起,能够得到更接近于人类观感的效果。
NFLX-TEST数据集
结果总结
下表中我们总结了上文讨论的不同指标针对NLFX-TEST,以及VQEG HD(仅vqeghd3集)[14]、LIVE Video Database[15],和LIVE Mobile Video Database [16]这三个流行的公开数据集最终得到的SRCC、PCC、RMSE值。结果证明VMAF 0.3.1在LIVE数据集之外其他数据集的测试中效果都好于别的指标,就算在LIVE数据集中与效果最好的VQM-VFD也没有太大差距。由于VQM-VFD在四个数据集中效果都很不错,目前我们考虑通过实验将VQM-VFD作为基本指标纳入VMAF,不过该指标并未包含在目前已经开源发布的VMAF 0.3.1中,可能会包含在后续发布的新版中。
NFLX-TEST数据集
LIVE数据集*
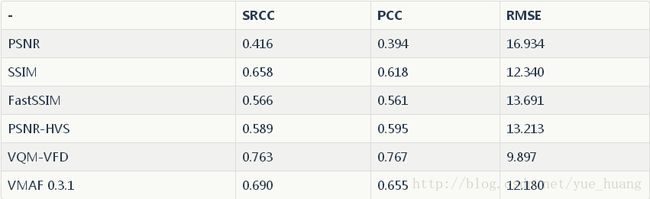
*仅对比压缩损失(H.264/AVC和MPEG-2视频)
VQEGHD3数据集**仅使用SRC01-SRC09的源内容以及与流播有关的损失HRC04、HRC07和HRC16-HRC21。
LIVE Mobile数据集VMAF开发包(VDK)开源程序包
为了通过互联网提供高质量视频,我们认为整个行业需要更实用的视频质量指标,这些指标不仅要易用,而且要方便大规模部署。针对这些需求我们开发了VMAF,并通过Apache License Version 2.0许可将VMAF开发包(VDK 1.0.0)程序包开源到GitHub。通过将VDK开源,我们希望大家能一起完善这一技术,进而提高视频质量的衡量手段。
VDK核心中特性的提取(包括基本指标的计算)任务是一种计算密集型操作,为了提高效率我们使用C语言编写这部分内容。为了能快速创建原型,控制代码部分是使用Python编写的。
该程序包提供了一个简单的命令行界面,可供用户以单模式(run_vmaf命令)或批处理模式(run_vmaf_in_batch命令,可选支持并行执行)运行VMAF。另外由于特性的提取是开销最大的操作,用户也可以将特性提取的结果存储起来以供重复使用。
该程序包还提供了针对下列因素对VMAF模型进行进一步定制所需的框架:
- 训练所用的视频数据集
- 要使用的基本指标和其他特性
- 回归因子及其超参数(Hyper-parameter)
run_training命令可以接受三个配置文件:包含训练数据集所需信息的数据集文件,特性参数文件,以及回归因子模型参数文件(包含回归因子的超参数)。下列代码示例定义了一个数据集,一系列所要使用的特性,以及回归因子及其超参数。
##### define a dataset #####
dataset_name = 'example'
uv_fmt = 'yuv420p'
width = 1920
height = 1080
ref_videos = [
{'content_id':0, 'path':'checkerboard.yuv'},
{'content_id':1, 'path':'flat.yuv'},
]
dis_videos = [
{'content_id':0, 'asset_id': 0, 'dmos':100, 'path':'checkerboard.yuv'}, # ref
{'content_id':0, 'asset_id': 1, 'dmos':50, 'path':'checkerboard_dis.yuv'},
{'content_id':1, 'asset_id': 2, 'dmos':100, 'path':'flat.yuv'}, # ref
{'content_id':1, 'asset_id': 3, 'dmos':80, 'path':'flat_dis.yuv'},
]
##### define features #####
feature_dict = {
# VMAF_feature/Moment_feature are the aggregate features
# motion, adm2, dis1st are the atom features
'VMAF_feature':['motion', 'adm2'],
'Moment_feature':['dis1st'], # 1st moment on dis video
}
##### define regressor and hyper-parameters #####
model_type = "LIBSVMNUSVR" # libsvm NuSVR regressor
model_param_dict = {
# ==== preprocess: normalize each feature ==== #
'norm_type':'clip_0to1', # rescale to within [0, 1]
# ==== postprocess: clip final quality score ==== #
'score_clip':[0.0, 100.0], # clip to within [0, 100]
# ==== libsvmnusvr parameters ==== #
'gamma':0.85, # selected
'C':1.0, # default
'nu':0.5, # default
'cache_size':200 # default
}最后,还可通过扩展FeatureExtractor基类(Base class)的方式开发自定义的VMAF算法。为此可使用其他可用基本指标和特性进行实验,或创建新的指标。同理还可以通过扩展TrainTestModel基类测试其他回归模型,详情请参阅CONTRIBUTING.md。用户还可以使用现有的开源Python库使用其他机器学习算法进行实验,例如可以使用scikit-learn [17]、cvxopt [18],或tensorflow [19]。程序包中还提供了一个与scikit-learn的随机森林回归因子(Random forest regressor)进行集成的示例。
VDK程序包提供了VMAF 0.3.1算法和精心挑选的特性,以及使用NFLX视频数据集收集的主观分数进行训练的SVM模型。我们想邀请整个社区使用该软件包为视频质量观感的评估开发更完备的特性和回归因子。另外我们也鼓励用户使用其他数据集测试VMAF 0.3.1,针对我们的用例以及更多其他使用场景继续进行完善和提高。有关质量评估的未决问题
观赏条件。Netflix支持从智能电视、游戏主机、机顶盒、计算机、平板,到智能手机等数千种主流设备,会员会在各种不同条件下观赏内容。观赏环境和显示设备也会对视频质量的观感产生影响。例如在60英寸4K电视上观看1Mbps码率的720p电影,所获得的观感与5英寸智能手机上观看同一部电影的体验就截然不同。目前NFLX视频数据集只涵盖在标准距离下通过电视观看这一种观赏条件。为了进一步完善VMAF,我们正在进行其他条件下的主观测试。有了更多数据后,即可创建出更为通用的算法,将观赏条件(显示设备尺寸、屏幕距离等)纳入回归因子。
时序累加(Temporal pooling)。目前的VMAF实现会分别针对每一帧画面计算质量分数。在很多用例中,需要对这些分数进行时序累加以获得一个值并将其作为一个时间段的总值。例如可能需要得出某个场景的分数,某个特定时间段的分数,或整部电影的分数。目前我们使用了一种简单的时序累加方式对每一帧的值求得算术平均值。然而这种方法有可能让我们“忽略”某些质量较差的帧。能够为较低分数提供更高权重的累加算法也许能得到更接近人类观感的结果。如果要使用汇总分数对比编码后不同帧的质量波动或将其用作优化编码或流播过程的目标指标,此时高质量的累加算法尤为重要。为VMAF和其他质量指标提供更接近实际观感的时序累加机制依然是一个有待研究并充满挑战的问题。
一致的指标。由于包含完整的参考基本指标,VMAF高度依赖参考内容的质量。然而不幸的是Netflix所提供内容的源视频质量并不统一。我们系统中存储的源内容分辨率从标清到4K五花八门,就算用相同分辨率播放,最高质量的源内容也可能存在某种程度的视频质量损失。因此对不同内容的VMAF分数进行对比(或汇总)无法获得精确的结果。例如当一个标清分辨率源内容生成的视频流获得99分(满分100)的VMAF分数,与相同得分,但使用高清分辨率源内容生成的视频流的质量完全不可同日而语。为了进行质量监控,我们亟需针对不同来源的内容计算出一个绝对质量分。毕竟当观众欣赏Netflix的节目时除了从屏幕上看到的画面,并没有参考视频可供对照。希望通过某种自动化方式预测观众对于所看到视频画面质量的观感,并充分考虑可能对视频在屏幕上最终呈现效果产生影响的各种因素。总结
为了向会员提供最佳质量的视频流播服务,我们开发了VMAF 0.3.1和VDK 1.0.0软件包。在不懈追求更高质量服务的过程中,我们的团队每天会使用这些工具评估视频编解码参数和策略。为了改善自动化的质量控制机制,我们已将VMAF和其他几个指标集成在编码管线中。在监控整个系统的A/B测试过程中使用VMAF作为客户端指标之一,我们才刚刚迈出了第一步。
改善视频压缩标准,以更智能的方式确定最实用的编码系统,这些要求在当今的互联网大环境中十分重要。我们认为,使用传统的指标(这些指标不一定能精确反映出人的观感)会妨碍到视频编码技术领域的技术进步,然而单纯依赖人工视觉测试在很多情况下并不可行。因此我们希望VMAF能解决这一问题,使用来自我们内容中的样本帮助大家设计和验证算法。正如业界会通过合作的方式一起制定新的视频标准,我们也邀请整个社区密切合作共同改善视频质量的衡量机制,而最终目标是更高效地利用网络带宽,让每个人都能看到赏心悦目的视频。致谢
感谢下列人员对VMAF项目的帮助:Joe Yuchieh Lin、Eddy Chi-Hao Wu、C.-C Jay Kuo 教授(美国南加州大学)、Patrick Le Callet教授(法国南特大学),以及Todd Goodall。
–