实时风格迁移:Style Transfer in Real-Time
为啥最近总是翻译呢,新年刚过,注意力不能很集中~刚好这几篇博文的图很漂亮~
翻译篇风格迁移实时计算相关的文章,原文这里
在前面的博文里,已经了解风格迁移的基本思路是将一张图的风格迁移到另一张图内容上去。gatys方法的缺陷在于生成一张图片需要大量时间,每次风格迁移图的生成都要解决一个新的优化问题。下面每张图片大约需要2个小时左右在CPU上迭代1000次。

问题来了, Prisma是如何做到在手机CPU上在几秒内让用户可以做不同风格的迁移的呢?
Real-Time Style Transfer
2016年3月,斯坦福大学的研究者发表了一篇文章,提出了一种近实时的风格迁移方法。他们能够训练一个神经网络来对任意指定的内容图像做单一的风格迁移,同时,也可以训练一个网络来搞定不同的风格。
Johnson的这篇paper Perceptual Losses for Real-Time Style Transfer and Super-Resolution表明,对指定图片应用单一的风格迁移,只需一次前向计算是可能的。
这里将对该方法做个概述,并展示一些用tensorflow实现时的结果。
Learning to Optimise
Gatys的方法,将迁移问题简化为对loss函数的寻优问题,Johnson则更进一步,如果将风格约束为单一的,那么可以训练一个神经网络来解决实时优化问题,将任意指定图片做固定风格的迁移。该方法的示意图如下:

该模型包括一个图转换网络和一个loss计算网络。图转换网络是个多层CNN网络,能够将输入内容图片 C C 装换为输出图片 Y Y ,图片 Y Y 具有 C C 的内容和 S S 的风格特点。loss计算网络用来计算生成图 Y Y 与内容图 C C 和风格图 S S 的loss。计算方式如 前文介绍,VGG网络已经用目标检测任务预训练过。
基于上述模型,我们可以训练图转换网络以降低total-loss。挑选一固定风格的图像,用大量的不同内容的图像作为训练样本。Johnson使用 Microsoft COCO dataset来训练,使用误差后传方式作为优化方法。
Image Transformation Network
Johnson所用的图转换结构如下:

如上所示,包含3个Conv+ReLU模块,5个残差模块,3个转置卷积,1个tanh层生成输出。
Downsampling with Strided Convolution
卷积层是对输入做filter卷积,通过移动一个固定尺寸的filter约束输入窗口,在窗口内应用卷积来计算每组像素的卷积值。不加说明时,默认filter的移动步幅stride=1个像素。

对于输入尺寸 n×m n × m 的图像,若filter尺寸为 k×k k × k ,且stride=1,则输出尺寸大小为 (n−k+1)×(m−k+1) ( n − k + 1 ) × ( m − k + 1 )
这样得到的图像分辨率稍低于原始图像,如果想要获得一样的分辨率,可以在输入图像四周添加zero-value(padding-method)。
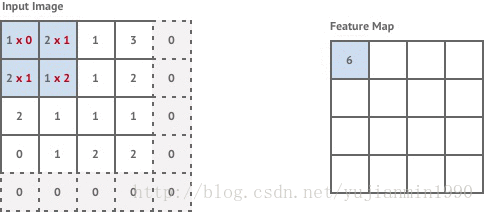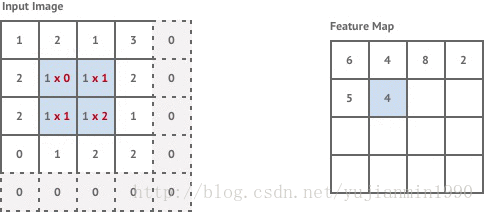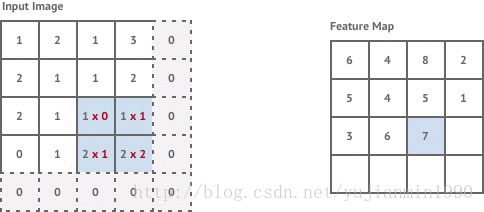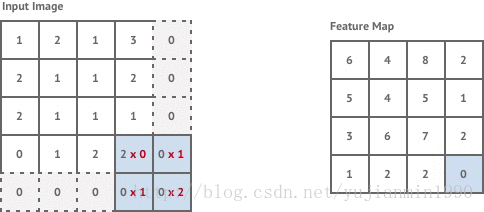
这里的第一个卷积层是stride=1,但是紧接着的两个卷积层是stride=2。当stride=2时,意味着filter的移动步幅是2个像素,加上padding之后,得到的输出尺寸是 n2×m2 n 2 × m 2 。

stride=2对输入具有downsampling的作用。
引入具有downsampling的卷积层的主要原因是,可以增加CNN的后续层卷积核的可视域。因为输入图像在像素上被下采样了,导致卷积计算可以计算原始图像更大范围的像素点。在某种程度上,允许卷积核可以在不增加核尺寸的情况下接触到更大范围的原始输入像素点。这一特性是很赞的,风格迁移会连续地对整个图片应用某种风格,所以每个filter对原始图像越多地表达越能够在风格迁移时更具有连贯性和一致性。
另外一种可以实现下采样的方法是pooling,也能够起到降低图像尺寸的效果。
Upsampling with Fractionally Strided Convolution
对图像应用两次stride=2的卷积,会降低size到原来的 14 1 4 ,但我们期望输出仍然具有与输入图相同的分辨率。为实现这一目的,我们引入stride= 12 1 2 的卷积,有时被称为转置卷积和逆卷积(注意: 这个称呼与前面的CNN的隐层可视化的转置卷积不是一个概念,尴尬脸)。这种操作可以提升图像的尺寸,起到Upsampling的作用。
stride= 12 1 2 以像素步幅1/2移动窗口,这使得输入的分辨率翻倍提高。但实际上,我们无法这么移动半个像素点的,因此将存在的每个像素点做zero-valued padding,然后再做stride=1的卷积,如下所示:

这样可以使图像分辨率翻倍,从而得到与原始输入图像同样分辨率的输出图像。
Residual Layers
在downsampling和upsampling之间有5层的残差层,将stride=1的Conv+ReLU 加上identity-connect如下:

使用残差层的原因是,对确定的任务减少训练的难度。我们的模型不需要学习如何根据输入产生新的输出,而是只需要学习如何调整输入以便产生所需输出。残差层之所以被叫做残差层,是由于我们只需要学习输入和输出之间的差距。
对一个像风格迁移这样的学习任务,使用残差层对生成相似于输入的图像是说得通的,所以加入残差层有助于学习残差。
Constraining the Output with a Tanh Layer
为了能够对神经网络的图像做处理,第一步要将图像表示为像素值在[0,255]之间的矩阵。神经网络的每一层都对该层输入做运算产生输出(下层输入),在这些层内并没有对输出值约束到[0,255]内。
当风格迁移时我们期望产生有效的图像,这意味着最后输出结果要将输出值约束到[0,255]内。为达到这一目的,我们在最后引入tanh来处理输出值。

tanh函数可以将值约束到[-1,+1]内,然后我们将这个结果调整下得到有效的像素值。
Results
下面是Johnson得到的部分结果:



我们使用来自Microsoft COCO数据集的8万条256x256(resize后)大小的样本来训练图转换网络,batch-size=4下迭代了4万次。在GTX Titan XGPU上训练每个网络大约需要4个小时左右,平均生成一张图片15毫秒。
Tensorflow Implementation
我自己实现的TF版本在这里,我训练了下面的三种风格图像转换网络。

每个图转换网络使用Microsoft COCO的8万条256x256(resize后)大小的样本来训练,batch-size=4迭代训练了10万次,在GTX1080GPU上消耗大约12个小时。
使用训练好的网络在CPU上产生一张图片大约需要5秒钟,下面举些生成的例子。