DeepGCNs-Can GCNs Go as Deep as CNNs? ICCV 2019
文章目录
- 1. 相关介绍
- 1.1 背景介绍
- 1.2 contribution
- 1.3 CNN中的dilated convolutions (膨胀卷积、扩张卷积、空洞卷积)
- 2. 模型与方法
- 2.1 图表示学习
- 图卷积
- 动态边
- 2.2 GCN中使用残差连接
- 2.3 GCN中使用dense连接
- 2.4 GCN中使用dilated聚合
- 3 实验
- 3.1 TASK: 3D Point Cloud Segmentation
- 3.2 实验指标
- 3.3 网络架构
- 3.4 实现
- 3.5 实验结果
- 资料分享
论文:DeepGCNs: Can GCNs Go as Deep as CNNs?
作者:Guohao Li, Matthias Müller, Ali Thabet, Bernard Ghanem
来源:ICCV 2019 Oral
论文链接:https://arxiv.org/abs/1904.03751
Github链接:https://github.com/lightaime/deep_gcns
本篇文章主要阐述了怎么去构建一个网络使得GCN能够堆叠更深的层且不会发生梯度消失的问题,引入了三个方法:1.Resnet 2.Densenet 3.Dilated convolutions 。最后,使用构建了一个非常深的56层的GCN,并展示它如何在点云语义分割任务中显著地提升了性能(相当于最先进的3.7%mIoU|均交并比)。
1. 相关介绍
1.1 背景介绍
GCN网络在近几年发展迅猛。对GCN的研究主要在于两点:
- 应用:现实世界中非欧氏距离的数据激增,GCN的应用广泛
- 性能:CCN处理这些数据的局限性
CNN的成功的一个关键因素是能够设计和训练一个深层的网络模型。但是,现在还不清楚如何恰当地设计一个深层的GCN结构。目前的研究工作认为,GCN中aggregate的本质其实相当于图像处理中的平滑(smooth),但是深层GCN的Aggregate容易造成over smooth问题,即节点间的feature难以区分,导致GCN模型一般在2-3层左右。因此,如何让GCN能够进行深层模型的学习一直是一个难题。

1.2 contribution
(1)借助CNN加深的思想,提出了三个深层GCN的算法:residual/dense connections, 和dilated convolutions (膨胀卷积、扩张卷积、空洞卷积)
- residual / dense connections:解决由网络加深导致的梯度消失问题
- dilated convolutions:解决由于pooling而导致的空间信息丢失,把卷积核膨胀了,增大了感受野,但没有增加参数数量
(2)使用点云语义分割(point cloud segmentation)任务作为实验平台,展示了这些新层对深度GCNs训练稳定性和性能的影响。
(3)使用提出的模型,在数据集S3DIS上实现了近4%的性能提升。
1.3 CNN中的dilated convolutions (膨胀卷积、扩张卷积、空洞卷积)
一个空洞卷积的例子如下:

Standard Convolution with a 3 x 3 kernel (and padding)

Dilated Convolution with a 3 x 3 kernel and dilation rate 2
2. 模型与方法
2.1 图表示学习
图卷积
通用的GCN网络从第 l l l层到 l + 1 l+1 l+1层的传播按如下方式:
G l + 1 = F ( G l , W l ) = U p d a t e ( A g g r e g a t e ( G l , W l a g g ) , W l u p d a t e ) ( 1 ) G_{l+1}=\mathcal{F}(G_l,W_l)=Update(Aggregate(G_l,W_l^{agg}),W_l^{update}) \qquad(1) Gl+1=F(Gl,Wl)=Update(Aggregate(Gl,Wlagg),Wlupdate)(1)
- G l = ( V l , ε l ) G_l=(V_l,\varepsilon_l) Gl=(Vl,εl)和 G l + 1 = ( V l + 1 , ε l + 1 ) G_{l+1}=(V_{l+1},\varepsilon_{l+1}) Gl+1=(Vl+1,εl+1)分别是第 l l l层的输入和输出
- W l a g g W_l^{agg} Wlagg和 W l u p d a t e W_l^{update} Wlupdate分别是可训练的聚合和更新函数的权重,它们是GCNs的关键部分
聚合函数可以是mean
aggregator、max-pooling aggregator、attention aggregator或LSTM aggregator。更新函数可以是多层感知器,门控网络等。更具体地说,通过对所有 v l + 1 ∈ V l + 1 v_{l+1} \in V_{l+1} vl+1∈Vl+1的相邻顶点特征进行聚合,计算出各层的顶点表示,如下所示:
h v l + 1 = ϕ ( h v l , ρ ( h u l ∣ u l ∈ N ( v l ) , h v l , W ρ ) , W ϕ ) ( 2 ) h_{v_{l+1}} = \phi (h_{v_l}, \rho({h_{u_l}|u_l∈ \mathcal{N}(v_l)},h_{v_l},W_\rho ), W_\phi) \qquad(2) hvl+1=ϕ(hvl,ρ(hul∣ul∈N(vl),hvl,Wρ),Wϕ)(2)
- ρ \rho ρ是一个顶点特征的聚合函数
- ϕ \phi ϕ是一个顶点特征的更新函数
- h v l h_{v_l} hvl和 h v l + 1 h_{v_{l+1}} hvl+1分别是第 l l l层和 l + 1 l+1 l+1层的顶点特征
- N ( v l ) \mathcal{N}(v_l) N(vl)是第 l l l层的顶点 v v v的邻居节点的集合
- h u l h_{u_l} hul是由 W ρ W_\rho Wρ参数化的邻居顶点的特征。
- W ϕ W_\phi Wϕ包含了这些函数的可训练的参数
本文使用一个简单的max-pooling顶点特征聚集器,在没有可学习参数的情况下,来聚集中心顶点与其所有相邻顶点之间的特征差异。使用的更新器是一个有batch normalization的多层感知器(MLP)和一个ReLU作为激活函数。
动态边
大多数GCN只在每次迭代时更新顶点特征。最近的一些工作表明,与具有固定图结构的GCN相比,动态图卷积可以更好地学习图的表示。例如,ECC(Edge-Conditioned Convolution,边缘条件卷积)使用动态边缘条件滤波器(dynamic edge-conditional filters)学习特定边的权重矩阵。EdgeConv在每个EdgeConv层之后,找到特征空间中最近的邻居来重建图形。为了学习点云的生成,Graph-Convolution GAN(生成对抗网络)还应用k-NN图来构造每一层顶点的邻域。动态变化的GCN邻居有助于缓解过度平滑的问题,并产生一个有效的更大的感受野。因此,文中在每一层的特征空间中通过一个Dilated k-NN函数来重新计算顶点之间的边,以进一步增加感受野。
2.2 GCN中使用残差连接
说简单点就是作者受到ResNet的启发把GCN改成ResGCN。文中提出了一个图的残差学习框架,通过拟合另一个残差映射 F \mathcal{F} F来学习所需的底层映射 H \mathcal{H} H。在 G l G_l Gl通过残差映射 F \mathcal{F} F变换了后,进行逐点加法得到 G l + 1 G_{l+1} Gl+1
G l + 1 = H ( G l , W l ) = F ( G l , W l ) + G l ( 3 ) G_{l+1}=\mathcal{H}(G_{l},W_l)=\mathcal{F}(G_l,W_l)+G_l \qquad(3) Gl+1=H(Gl,Wl)=F(Gl,Wl)+Gl(3)
残差映射 F \mathcal{F} F把一个图作为输入并为下一层输出一个残差图的表示 G l + 1 r e s G_{l+1}^{res} Gl+1res。 W l W_l Wl是第 l l l层的一组可学习参数。
G l + 1 r e s = F ( G l , W l ) : = G l + 1 − G l ( 4 ) G_{l+1}^{res}=\mathcal{F}(G_l,W_l):=G_{l+1}-G_l \qquad(4) Gl+1res=F(Gl,Wl):=Gl+1−Gl(4)
2.3 GCN中使用dense连接
DenseNet提出了一种更有效的方法,通过密集的连接来改进信息流并重用层之间的特征。DenseNet的启发下,文中采用了类似的思想到GCNs中,以利用来自不同GCN层的信息流,将使用了dense connection的GCN称为DenseGCN。
G l + 1 = H ( G l , W l ) = T ( F ( G l , W l ) , G l ) = T ( F ( G l , W l ) , . . . , F ( G 0 , W 0 ) , G 0 ) ( 5 ) \begin{aligned} G_{l+1} & =\mathcal{H}(G_{l},W_l) \\ & =\mathcal{T}(\mathcal{F}(G_l,W_l),G_l) \\ & =\mathcal{T}(\mathcal{F}(G_l,W_l),...,\mathcal{F}(G_0,W_0),G_0) \end{aligned} \qquad(5) Gl+1=H(Gl,Wl)=T(F(Gl,Wl),Gl)=T(F(Gl,Wl),...,F(G0,W0),G0)(5)
- 操作 T \mathcal{T} T是一个顶点连接函数,它将输入图 G 0 G_0 G0与所有中间GCN层输出紧密地融合在一起
- G l + 1 G_{l+1} Gl+1包含了来自前一层的所有GCN转换
- DenseGCN的增长率等于输出图的维数 D D D。例如,如果 F \mathcal{F} F生成一个 D D D维顶点特征,其中输入图 G 0 G_0 G0的顶点为 D 0 D_0 D0维,则 G l + 1 G_{l+1} Gl+1的每个顶点的特征尺寸为 D 0 + D × ( l + 1 ) D_0+D ×(l+1) D0+D×(l+1)。
2.4 GCN中使用dilated聚合
作者从借鉴小波分析,提出了以下方法:
(1)作者考虑在特征空间上使用 l 2 l^2 l2距离,对与目标节点(卷积中心点)的距离进行排序:
u 1 , u 2 , . . . , u k × d u_1 , u_2 , ..., u_{k×d} u1,u2,...,uk×d
(2)Dilated K-NN: 使用dilated方法确定dilated系数为 d d d时,目标节点(卷积中心点) v v v相对应的邻居节点为 ( u 1 , u 1 + d , u 1 + 2 d , . . . , u 1 + ( k − 1 ) d ) (u_1,u_{1+d} ,u_{1+2d} , ..., u_{1+(k−1)d}) (u1,u1+d,u1+2d,...,u1+(k−1)d)。
N ( d ) ( v ) = u 1 , u 1 + d , u 1 + 2 d , . . . , u 1 + ( k − 1 ) d \mathcal{N}^{(d)}(v)= {u_1,u_{1+d} ,u_{1+2d} , ..., u_{1+(k−1)d} } N(d)(v)=u1,u1+d,u1+2d,...,u1+(k−1)d
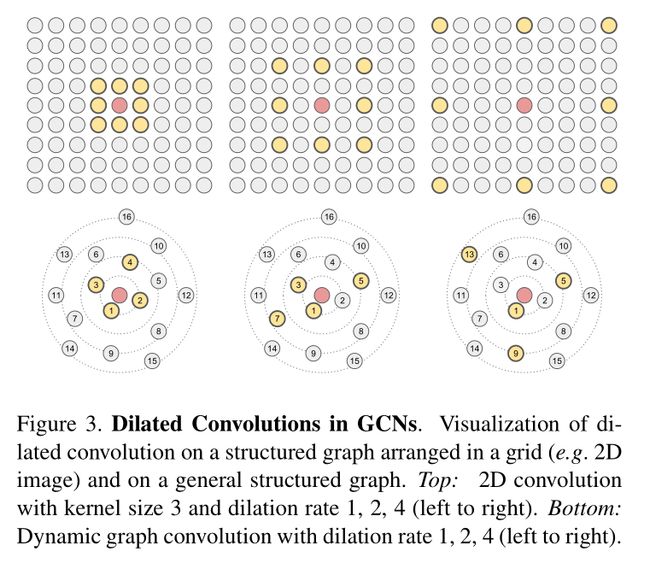
- 图3:在GCNs中的空洞卷积示意图
- 上图是一个2维空间中的空洞卷积,扩张率分别为1,2,4
- 下图是在动态图中的卷积,扩张率分别为1,2,4
3 实验
- 使用提出的ResGCN和DenseGCN来处理GCNs的消失梯度问题。
- 为了扩大接受域,定义了一个扩张的图卷积算子 dilated convolution 。
- 为了评估的框架,对大规模点云分割任务进行了大量的实验,并证明了文中的方法可以显著提高模型性能。
3.1 TASK: 3D Point Cloud Segmentation
- 由于点云结构无序、不规则,点云分割是一项具有挑战性的任务。通常,点云中的每个点都由其三维坐标和其他特征(如颜色、曲面法线等)表示。
- 在有向图 G G G中,作者将每个点视为顶点 v v v,并使用k-NN构造每个GCN层点之间的有向动态边)。
- 在第一层,执行一个dilated k-NN搜索在三维坐标空间中找到最近的邻点,构造了一个初始输入图 G 0 G_0 G0。在随后的层中,使用特征空间中的dilated k-NN动态构建边。
- 对于分割任务,预测输出层所有顶点的类别。
3.2 实验指标
对所有类别都使用了 overall accuracy (OA) 和 mean intersection over union (mIoU) 作为评价指标。
补充:
- True Positive (真正, TP)被模型预测为正的正样本;
- True Negative(真负 , TN)被模型预测为负的负样本 ;
- False Positive (假正, FP)被模型预测为正的负样本;
- False Negative(假负 , FN)被模型预测为负的正样本;
- ground truth:在有监督学习中,数据是有标注的,以(x, t)的形式出现,其中x是输入数据,t是标注。正确的t标注是ground truth
- Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation),即计算真实值集和预测值集的交集和并集之比后再求平均。这个比例可以变形为正真数(intersection)比上真正、假负、假正(并集)之和。在每个类上计算IoU,之后平均。
为了便于解释,假设如下:共有 k + 1 k+1 k+1个类(从 L 0 L_0 L0到 L k L_k Lk,其中包含一个空类或背景), p i j p_{ij} pij表示本属于类 i i i但被预测为类 j j j的像素数量。即, p i i p_{ii} pii表示真正的数量,而 p i j , p j i p_{ij},p_{ji} pij,pji则分别被解释为假正和假负,尽管两者都是假正与假负之和。
M I o U = 1 k + 1 ∑ i = 0 k p i i ∑ j = 0 k p i j + ∑ j = 0 k p j i − p i i MIoU=\frac{1}{k+1}\sum_{i=0}^{k}{\frac{p_{ii}}{\sum_{j=0}^{k}{p_{ij}}+\sum_{j=0}^{k}{p_{ji}}-p_{ii}}} MIoU=k+11i=0∑k∑j=0kpij+∑j=0kpji−piipii
3.3 网络架构
如下图所示,模型包含三个部分:GCN、fusion、MLP三个模块。

- 图2:论文中对于点云语义分割的GCNs网络结构
- 左图是组成框架的三个block(a GCN backbone block, a fusion block and an MLP prediction block)
- 右图是GCN backbone block研究的三种主要类型,如PlainGCN、ResGCN、DenseGCN。
- 采用了两种GCN跳跃连接:vertex-wise additions and vertex-wise concatenations。
- k k k是GCNs层中最临近的邻居的数量, f f f是隐藏层或滤波器的数量, d d d是扩张率。
3.4 实现
- 使用TensorFlow来实现所有模型。
- 为了公平比较,使用初始学习率0.001和相同学习率Adam优化器;
- 学习率每 3 × 1 0 5 3×10^5 3×105个梯度下降50%。
- 使用两个Nvidia Tesla V100 GPU,利用数据并行性对网络进行训练。每个GPU的batch size设置为8。
- Batch Normalization应用于每一层。
- MLP prediction block的第二个MLP层使用0.3速率的dropout。
- 对于GCNs with dilations,使用具有随机均匀抽样概率 ϵ = 0.2 \epsilon=0.2 ϵ=0.2的扩张k-nn。
- 为了隔离所提出的深度GCN架构的影响,不使用任何数据扩充和后处理技术。
3.5 实验结果

- 图5:在S3DIS中的5个区域进行的消融研究
- 将参考网络(ResGCN-28有与28层、残差图连接和扩张图卷积等与几个消融的变体进行了比较。
- 除用于评估的区域5外,所有模型在所有区域均以相同的超参数进行100个epoch的训练。


资料分享
ResGCN-Can GCNs Go as Deep as CNNs? 两份PPT(官方PPT和会议PPT)
ResGCN-Can GCNs Go as Deep as CNNs 论文ppt
Stanford Large-Scale 3D Indoor Spaces Dataset (S3DIS,斯坦福大规模三维室内空间数据集)
此论文的tensorflow版github源代码