【机器学习算法总结】GBDT
目录
1、GBDT
2、GBDT思想
3、负梯度拟合
4、损失函数
4.1、分类
4.2、回归
5、GBDT回归算法
6、GBDT分类算法
6.1、二分类
6.2、多分类
7、正则化
8、RF与GBDT之间的区别与联系
9、优缺点
优点
缺点
10、应用场景
11、主要调参的参数
12、sklearn.ensemble.GradientBoostingClassifier参数及方法说明
参考
1、GBDT
GBDT(Gradient Boosting Decision Tree)是boosting系列算法中的一个代表算法,它是一种迭代的决策树算法,由多棵决策树组成,所有树的结论累加起来作为最终答案。
2、GBDT思想
我们利用平方误差来表示损失函数,其中每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树。其中残差=真实值-预测值,提升树即是整个迭代过程生成的回归树的累加。
我们通过以下例子来详解算法过程,希望通过训练提升树来预测年龄。
训练集:(A, 14岁)、(B,16岁)、(C, 24岁)、(D, 26岁);
特征:购物金额是否小于1K;经常去百度提问还是回答;
训练数据的均值:20岁;(这个很重要,因为GBDT与i开始需要设置预测的均值,这样后面才会有残差!)
决策树的个数:2棵;

首先,输入初值20岁,根据第一个特征(具体选择哪些特征可以根据信息增益来计算选择),可以把4个样本分成两类,一类是购物金额<=1K,一类是>=1K的。假如这个时候我们就停止了第一棵树的学习,这时我们就可以统计一下每个叶子中包含哪些样本,这些样本的均值是多少,因为这个时候的均值就要作为所有被分到这个叶子的样本的预测值了。比如AB被分到左叶子,CD被分到右叶子,那么预测的结果就是:AB都是15岁,CD都是25岁。和他们的实际值一看,结果发现出现的残差,ABCD的残差分别是-1, 1, -1, 1。这个残差,我们要作为后面第二棵决策树的学习样本。

然后学习第二棵决策树,我们把第一棵的残差样本(A, -1岁)、(B,1岁)、(C, -1岁)、(D, 1岁)输入。此时我们选择的特征是经常去百度提问还是回答。这个时候我们又可以得到两部分,一部分是AC组成了左叶子,另一部分是BD组成的右叶子。那么,经过计算可知左叶子均值为-1,右叶子均值为1. 那么第二棵数的预测结果就是AC都是-1,BD都是1. 我们再来计算一下此时的残差,发现ABCD的残差都是0!学习完成。
测试样本:预测一个购物金额为3k,经常去百度问淘宝相关问题的女生的年龄。25-1=24,即最终预测结果为24岁。
我们能够直观的看到,预测值等于所有树值的累加,如A的预测值=树1左节点(15)+树2左节点(-1)=14。因此给定当前决策树模型![]() ,只需拟合决策树的残差,便可迭代得到提升树,算法过程如下
,只需拟合决策树的残差,便可迭代得到提升树,算法过程如下
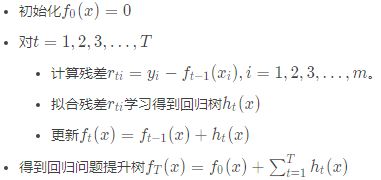
我们介绍了Boosting Decision Tree的基本思路,但是没有解决损失函数拟合方法的问题。针对这个问题,Freidman提出用损失函数的负梯度来拟合本轮损失的近似值,进而拟合一个CART回归树。了解Boosting Decision Tree方法后,我们便可将Gradient与Boosting Decision Tree相结合得到Gradient Boosting Decision Tree的负梯度拟合。
3、负梯度拟合
在GBDT迭代过程中,假设我们前一轮迭代得到的强学习器是![]() ,损失函数是
,损失函数是 ![]() ,我们本轮迭代的目标是找到一个回归树模型的弱学习器
,我们本轮迭代的目标是找到一个回归树模型的弱学习器![]() ,让本轮的损失
,让本轮的损失 ![]() =
= ![]() 最小。也就是说,本轮迭代找到的决策树,要让样本的损失函数尽量变得更小。
最小。也就是说,本轮迭代找到的决策树,要让样本的损失函数尽量变得更小。
常见的损失函数如下:

在上述损失函数中,GBDT选取了相对来说容易优化的损失函数——平方损失。针对怎样去拟合这个损失,大牛Freidman提出了用损失函数的负梯度来拟合本轮损失的近似值。第t轮的第i个样本的损失函数的负梯度为:
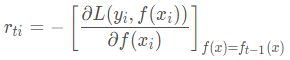
对应损失函数列表可知,GBDT使用的平方损失,经过负梯度拟合得到了![]() ,这就是我们最终要去拟合的,它的另一个名字叫作残差。
,这就是我们最终要去拟合的,它的另一个名字叫作残差。
4、损失函数
4.1、分类
分类算法常用的损失函数有:指数损失函数和对数损失函数。
- 对数损失函数(二分类):
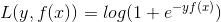
- 对数损失函数(多分类):
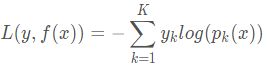
- 指数损失函数:
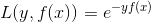
4.2、回归
回归算法常用损失函数有:均方差、绝对损失、Huber损失和分位数损失。
- 均方差:
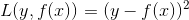
- 绝对损失:L(y,f(x))=∣y−f(x)∣
- Huber损失:Huber损失是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心点附近采用均方差。这个界限一般用分位数点来度量,损失函数和对应的负梯度误差如下:

- 分位数损失:分位数损失和负梯度误差如下所示。其中其中θ 为分位数,需要我们在回归前指定。
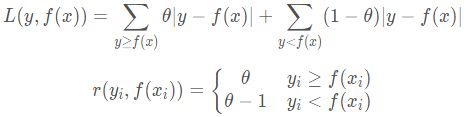
对于Huber损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。
5、GBDT回归算法
假设训练集样本![]() ,最大迭代次数为T,损失函数L,输出是强学习器f(x)。回归算法过程如下:
,最大迭代次数为T,损失函数L,输出是强学习器f(x)。回归算法过程如下:
1、初始化弱学习器,c的均值可设置为样本y的均值。
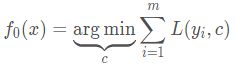
2、对迭代次数t=1,2,3,…,T有:
2.1、对样本i=1,2,3,…,m,计算负梯度:
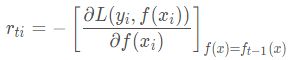
2.2、利用![]() ,拟合一棵CART回归树,得到第t棵回归树,其对应的叶子节点区域为
,拟合一棵CART回归树,得到第t棵回归树,其对应的叶子节点区域为![]() 。其中J为回归树t的叶子节点个数。
。其中J为回归树t的叶子节点个数。
2.3、对叶子区域j=1,2,3,…,J,计算最佳拟合值:
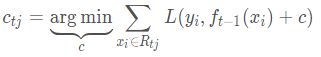
2.4、更新强学习器
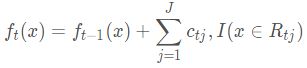
3、得到强学习器f(x)表达式:
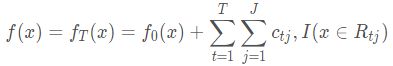
6、GBDT分类算法
GBDT分类算法在思想上和回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。为解决此问题,我们尝试用类似于逻辑回归的对数似然损失函数的方法,也就是说我们用的是类别的预测概率值和真实概率值来拟合损失函数。对于对数似然损失函数,我们有二元分类和多元分类的区别。
6.1、二分类
对于二元GBDT,如果用类似于逻辑回归的对数似然损失函数,则损失函数表示为:![]()
其中,![]() 。则此时的负梯度误差为:
。则此时的负梯度误差为:
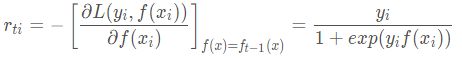
对于生成的决策树,我们各个叶子节点的最佳残差拟合值为:
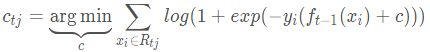
由于上式比较难优化,我们一般使用近似值代替:
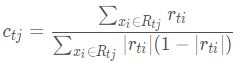
除了负梯度计算和叶子节点的最佳残差拟合的线性搜索外,二元GBDT分类和GBDT回归算法过程相同。
6.2、多分类
多元GBDT要比二元GBDT复杂一些,对应的是多元逻辑回归和二元逻辑回归的复杂度差别。假如类别数为K,则我们的对数似然函数为:
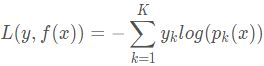
其中如果样本输出类别为k,则![]() 。第k类的概率
。第k类的概率![]() 的表达式为:
的表达式为:
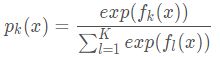
集合上两式,我们可以计算出第t轮的第i个样本对应类别l的负梯度误差为:
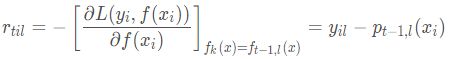
其实这里的误差就是样本i对应类别l的真实概率和t-1轮预测概率的差值。对于生成的决策树,我们各个叶子节点的最佳残差拟合值为:
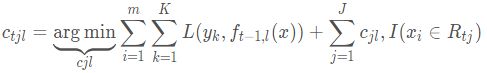
由于上式比较难优化,我们用近似值代替:

除了负梯度计算和叶子节点的最佳残差拟合的线性搜索,多元GBDT分类和二元GBDT分类以及GBDT回归算法过程相同。
7、正则化
和Adaboost一样,我们也需要对GBDT进行正则化,防止过拟合。GBDT的正则化主要有3种方式:learning_rate(学习率);subsample(子采样比例);min_samples_split(叶子结点包含的最小样本数)。
针对GBDT正则化,我们通过子采样比例方法和定义步长v方法来防止过拟合。
1、learning_rate。学习率是正则化的一部分,它可以降低模型更新的速度(需要更多的迭代)。通常我们用learning_rate和最大迭代次数一起来决定算法的拟合效果。
![]()
- 经验表明:一个小的学习率 (v<0.1) 可以显著提高模型的泛化能力(相比较于v=1) 。
- 如果学习率较大会导致预测性能出现较大波动。
2、subsample,子采样比例。Freidman 从bagging 策略受到启发,采用随机梯度提升来修改了原始的梯度提升树算法。
- 每一轮迭代中,新的决策树拟合的是原始训练集的一个子集(而并不是原始训练集)的残差。这个子集是通过对原始训练集的无放回随机采样而来。
- 无放回抽样的子采样比例(subsample),取值为(0,1]。
- 如果取值为1,则与原始的梯度提升树算法相同,即使用全部样本。如果取值小于1,则使用部分样本去做决策树拟合。
- 较小的取值会引入随机性,有助于改善过拟合,因此可以视作一定程度上的正则化;但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间。
- 这种方法除了改善过拟合之外,另一个好处是:未被采样的另一部分子集可以用来计算包外估计误差。因此可以避免额外给出一个独立的验证集。
3、min_samples_split,叶子结点包含的最小样本数。梯度提升树会限制每棵树的叶子结点包含的样本数量至少包含m个样本,其中m为超参数。在训练过程中,一旦划分结点会导致子结点的样本数少于m,则终止划分。
8、RF与GBDT之间的区别与联系
相同点:
- 都是由多棵树组成;
- 最终的结果都由多棵树共同决定;
不同点:
- 组成随机森林的树可以分类树也可以是回归树,而GBDT只由回归树组成;
- 组成随机森林的树可以并行生成(Bagging);GBDT 只能串行生成(Boosting);这两种模型都用到了Bootstrap的思想;
- 随机森林的结果是多数表决表决的,而GBDT则是多棵树加权累加之和;
- 随机森林对异常值不敏感,而GBDT对异常值比较敏感;随机森林
- 是减少模型的方差,而GBDT是减少模型的偏差;
- 随机森林不需要进行特征归一化。而GBDT则需要进行特征归一化;
- 随机森林对训练集一视同仁权值一样,GBDT是基于权值的弱分类器的集成 ;
9、优缺点
优点
- 可以灵活处理各种类型的数据,包括连续值和离散值。
- 使用了一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
- 充分考虑的每个分类器的权重。
缺点
- 由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
10、应用场景
GBDT 可以适用于回归问题(线性和非线性);
GBDT 也可用于二分类问题(设定阈值,大于为正,否则为负)和多分类问题。
11、主要调参的参数
GradientBoostingClassifier和GradientBoostingRegressor的参数绝大部分相同,不同点会单独指出。
- n_estimators: 也就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是100。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑。
- learning_rate: 即每个弱学习器的权重缩减系数,也称作步长,在原理篇的正则化章节我们也讲到了,加上了正则化项,我们的强学习器的迭代公式为。的取值范围为。对于同样的训练集拟合效果,较小的意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。所以这两个参数n_estimators和learning_rate要一起调参。一般来说,可以从一个小一点的开始调参,默认是1。
- subsample: 即我们在原理篇的正则化章节讲到的子采样,取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间,默认是1.0,即不使用子采样。
- init: 即我们的初始化的时候的弱学习器,拟合对应原理篇里面的,如果不输入,则用训练集样本来做样本集的初始化分类回归预测。否则用init参数提供的学习器做初始化分类回归预测。一般用在我们对数据有先验知识,或者之前做过一些拟合的时候,如果没有的话就不用管这个参数了。
- loss: 损失函数。(1)对于分类模型,有对数似然损失函数"deviance"和指数损失函数"exponential"两者输入选择。默认是对数似然损失函数"deviance"。在原理篇中对这些分类损失函数有详细的介绍。一般来说,推荐使用默认的"deviance"。它对二元分离和多元分类各自都有比较好的优化。而指数损失函数等于把我们带到了Adaboost算法。(2)对于回归模型,有均方差"ls", 绝对损失"lad", Huber损失"huber"和分位数损失“quantile”。默认是均方差"ls"。一般来说,如果数据的噪音点不多,用默认的均方差"ls"比较好。如果是噪音点较多,则推荐用抗噪音的损失函数"huber"。而如果我们需要对训练集进行分段预测的时候,则采用“quantile”。
- alpha:这个参数只有GradientBoostingRegressor有,当我们使用Huber损失"huber"和分位数损失“quantile”时,需要指定分位数的值。默认是0.9,如果噪音点较多,可以适当降低这个分位数的值。
12、sklearn.ensemble.GradientBoostingClassifier参数及方法说明
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html#sklearn.ensemble.GradientBoostingClassifier
基于scikit-learn v0.20.1
class sklearn.ensemble.GradientBoostingClassifier(loss=’deviance’, learning_rate=0.1, n_estimators=100, subsample=1.0, criterion=’friedman_mse’, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None, max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, presort=’auto’, validation_fraction=0.1, n_iter_no_change=None, tol=0.0001)[source]¶
| Parameters | loss | 可选,默认:’deviance’。‘deviance’, ‘exponential’。损失函数。 ‘deviance’:此时损失函数为对数损失函数。 ‘exponential’:指数损失函数。 |
| learning_rate | float,可选,默认:1。学习率。 通过learning_rate缩减每棵树的贡献。 在learning_rate和n_estimators之间进行权衡。 |
|
| n_estimators | int,可选,默认:100。基础决策树的数量。 值越大越好。 |
|
| subsample | float,可选,默认:1.0。指定提取原始训练集中多大比例的一个子集用于训练基础决策树。 如果 subsample小于1.0,则梯度提升决策树模型就是随机梯度提升决策树。 此时会减少方差但是提高了偏差。 它会影响n_estimators参数。 |
|
| criterion | string,可选,默认:“friedman_mse” 。 “friedman_mse”:Friedman改进得分的均方误差。 “mse”:均方误差。 “mae”:平均绝对误差。
|
|
| min_samples_split | int, float,可选,默认:2。分割内部节点所需的最小样本数。 如果是int,则将min_samples_split视为最小数字。 |
|
| min_samples_leaf | int, float,可选,默认:1。叶子节点所需的最小样本数。 只有在每个左右分支中留下至少min_samples_leaf训练样本时,才会考虑任何深度的分裂点。 这可能具有平滑模型的效果,尤其是在回归中。 如果是int,则将min_samples_leaf视为最小数字。 |
|
| min_weight_fraction_leaf | float,可选,默认:0。需要在叶节点处的权重总和(所有输入样本)的最小加权分数。当未提供sample_weight时,样本具有相同的权重。 | |
| max_depth | int,可选,默认:3。树的最大深度。 调整该参数可以获得最佳性能。 |
|
| min_impurity_decrease | float,可选,默认:0。如果该划分导致impurity的减少大于或等于该值,则将划分该节点。 | |
| min_impurity_split | float,默认:1e-7。阈值。Threshold for early stopping in tree growth.如果节点的impurity高于此阈值,则划分节点,否则它是叶子节点。 从v0.19开始不推荐使用:min_impurity_split已被弃用。min_impurity_split的默认值将在v0.23中从1e-7变为0,并且将在v0.25中删除。 请改用min_impurity_decrease。 |
|
| init | estimator,可选。用于计算初始预测的estimator。 init必须提供fit和predict。如果是None,则使用loss.init_estimator。 |
|
| random_state | int, RandomState instance或None,可选,默认:”None”。让结果可以复现,再次运行代码时可以得到之前一样的结果。 如果是int,则random_state是随机数生成器使用的种子; 如果是RandomState实例,则random_state是随机数生成器; 如果为None,则随机数生成器是np.random使用的RandomState实例。 |
|
| max_features | int, float, string或None,可选,默认:”auto”。寻找最佳划分时要考虑的特征数量。 如果 max_features< n_features,则会减少方差但是提高了偏差。 如果是int,则在每次划分时考虑max_features特征。 |
|
| verbose | int,可选,默认:0。是否输出一些模型运算过程中的东西(任务进程)。如果为1则会偶尔输出进度和性能(树越多,频率越低)。如果大于1,则会输出每棵树的进度和性能。 | |
| max_leaf_nodes | int或None,可选,默认:”None”。以最佳方式使用max_leaf_nodes生成树。 最佳节点定义为不纯度的相对减少。如果为None,则表示不限制叶节点数。 |
|
| warm_start | bool,默认:False。是否使用上次的模型结果作为初始化,False表示不使用。 | |
| presort | bool或'auto',可选,默认:'auto'。是否预先分配数据以加快拟合找到最佳划分。 在稀疏数据上将presort设置为true将引发错误。 |
|
| validation_fraction | float,可选,默认:0.1。留作提前停止的验证集的训练数据比例。 必须介于0和1之间。仅在n_iter_no_change设置为整数时使用。 |
|
| n_iter_no_change | int,默认:None。用于确定在验证得分没有改善时是否将使用提前停止来终止训练。 默认情况下,它设置为“None”以禁用提前停止。 如果设置为数字,则将训练数据的validation_fraction大小留作验证,并在所有先前的n_iter_no_change迭代次数中验证得分未得到改善时终止训练。 |
|
| tol | float,可选,默认:1e-4。提前停止的阈值。 如果n_iter_no_change迭代的损失的改善值小于tol ,则训练停止。 |
|
| Attributes | n_estimators_ | 提前终止的决策树数量,如果指定了n_iter_no_change 则为n_iter_no_change ,否则设置为n_estimators。 |
| feature_importances_ | 返回特征的重要性(值越大,特征越重要)。 | |
| oob_improvement_ | 数组。shape为(n_estimators,)。相对于前一次迭代,袋外样品的损失(=deviance)改进。 oob_improvement_ [0]是init决策树第一阶段的loss改进。 |
|
| train_score_ | 数组。shape为(n_estimators,)。train_score_[i]表示袋内样本第i次迭代时,模型的deviance (= loss)。如果subsample == 1,则这是训练数据的deviance 。 | |
| loss_ | 损失函数。 | |
| init_ | 初始决策树。通过init参数或loss.init_estimator设置。 | |
| estimators_ | DecisionTreeRegressor的ndarray,shape为(n_estimators, loss_.K)。拟合的子分类器集合。 二分类,loss_.K=1;多分类,loss_.K=n_classes。 |
|
| Methods | apply(X) |
将树应用到X,返回叶子节点索引。 |
decision_function(X) |
计算X的决策函数。 | |
fit(X, y[, sample_weight, monitor]) |
训练模型。 其中monitor是一个可调用对象,它在当前迭代过程结束时调用。如果它返回True,则训练过程提前终止。 | |
get_params([deep]) |
获取分类器的参数。 | |
predict(X) |
用模型进行预测,返回预测值。 | |
predict_log_proba(X) |
返回一个数组,数组的元素依次是X预测为各个类别的概率的对数值。 | |
predict_proba(X) |
返回一个数组,数组的元素依次是X预测为各个类别的概率值。 | |
score(X, y[, sample_weight]) |
返回模型的预测性能得分。 | |
set_params(**params) |
设置分类器的参数。 | |
staged_decision_function(X) |
计算每一轮迭代的X的决策函数。 | |
staged_predict(X) |
返回一个数组,数组元素依次是:GBDT 在每一轮迭代结束时的预测值。 | |
staged_predict_proba(X) |
返回一个二维数组,数组元素依次是:GBDT 在每一轮迭代结束时,预测X为各个类别的概率值。 |
参考
https://shimo.im/docs/LItvmnbkRwAe2KM0