Java常见面试题汇总-----------Java框架
47、struts2的执行流程?
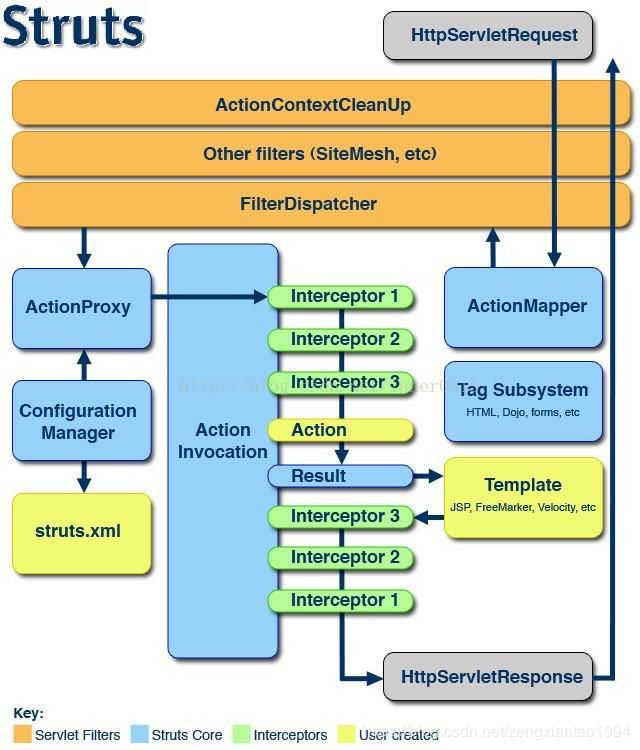
在Struts2框架中的处理大概分为以下的步骤
1、用户发送请求;
2、这个请求经过一系列的过滤器(Filter)(这些过滤器中有一个叫做ActionContextCleanUp的可选过滤器,这个过滤器对于Struts2和其他框架的集成很有帮助,例如:SiteMesh Plugin);
3、接着FilterDispatcher被调用,FilterDispatcher询问ActionMapper来决定这个请求是否需要调用某个Action;
4、如果需要处理,ActionMapper会通知FilterDispatcher,需要处理这个请求,FilterDispatcher会停止过滤器链以后的部分,(这也就是为什么,FilterDispatcher应该出现在过滤器链的最后的原因)。FilterDispatcher把请求的处理交给ActionProxy;
5、ActionProxy通过Configuration Manager询问框架的配置文件struts.xml,找到需要调用的Action类 。(在服务器启动的时候,ConfigurationManager就会把struts.xml中的所有信息读到内存里,并缓存,当ActionProxy带着URL向他询问要运行哪个Action的时候,就可以直接匹配、查找并回答了);
6、ActionProxy创建一个ActionInvocation的实例。
7、ActionInvocation实例使用命名模式来调用,在调用Action的过程前后,涉及到一系列相关拦截器(Intercepter)的调用。
8、一旦Action执行完毕,ActionInvocation负责根据struts.xml中的配置找到对应的返回结果。返回结果通常是(但不总是,也可能是另外的一个Action链)一个需要被表示的JSP或者FreeMarker的模版。在表示的过程中可以使用Struts2 框架中继承的标签。
9、最后,ActionInvocation对象倒序执行拦截器。
10、ActionInvocation对象执行完毕后,响应用户。
注意:2.1.3之后的核心过滤器由FilterDispatcher换成StrutsPrepareAndExecuteFilter。
48、SpringMVC的执行流程?
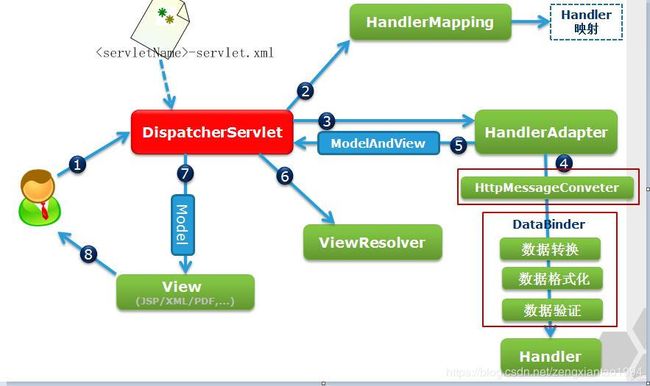
1、用户向服务器发送请求,请求被Spring 前端控制Servelt DispatcherServlet捕获;
2、DispatcherServlet对请求URL进行解析,得到请求资源标识符(URI)。然后根据该URI,调用HandlerMapping获得该Handler配置的所有相关的对象(包括Handler对象以及Handler对象对应的拦截器),最后以HandlerExecutionChain对象的形式返回;
3、DispatcherServlet 根据获得的Handler,选择一个合适的HandlerAdapter。(附注:如果成功获得HandlerAdapter后,此时将开始执行拦截器的preHandler(…)方法);
4、提取Request中的模型数据,填充Handler入参,开始执行Handler(Controller)。在填充Handler的入参过程中,根据你的配置,Spring将帮你做一些额外的工作:
HttpMessageConveter:将请求消息(如Json、xml等数据)转换成一个对象,将对象转换为指定的响应信息;
数据转换:对请求消息进行数据转换。如String转换成Integer、Double等;
数据格式化:对请求消息进行数据格式化。如将字符串转换成格式化数字或格式化日期等;
数据验证:验证数据的有效性(长度、格式等),验证结果存储到BindingResult或Error中;
5、Handler执行完成后,向DispatcherServlet 返回一个ModelAndView对象;
6、根据返回的ModelAndView,选择一个适合的ViewResolver(必须是已经注册到Spring容器中的ViewResolver)返回给DispatcherServlet;
7、ViewResolver 结合Model和View,来渲染视图;
8、将渲染结果返回给客户端。
49、struts2和springMVC的区别
目前企业中使用SpringMVC的比例已经远远超过Struts2,那么两者到底有什么区别,是很多初学者比较关注的问题,下面我们就来对SpringMVC和Struts2进行各方面的比较:
1、核心控制器(前端控制器、预处理控制器):对于使用过mvc框架的人来说这个词应该不会陌生,核心控制器的主要用途是处理所有的请求,然后对那些特殊的请求(控制器)统一的进行处理(字符编码、文件上传、参数接受、异常处理等等),SpringMVC核心控制器是Servlet,而Struts2是Filter。
2、控制器实例:SpringMVC会比Struts快一些(理论上)。SpringMVC是基于方法设计,而Sturts是基于对象, 每次发一次请求都会实例一个action,每个action都会被注入属性,而Spring更像Servlet一样,只有一个实例,每次请求执行对应的方法即可(注意:由于是单例实例,所以应当避免全局变量的修改,这样会产生线程安全问题)。
3、管理方式:大部分的公司的核心架构中,就会使用到spring,而SpringMVC又是spring中的一个模块,所以spring对于SpringMVC的控制器管理更加简单方便,而且提供了全注解方式进行管理,各种功能的注解都比较全面,使用简单,而struts2需要采用XML很多的配置参数来管理(虽然也可以采用注解,但是几乎没有公司那样使用)。
4、参数传递:Struts2中自身提供多种参数接受,其实都是通过(ValueStack)进行传递和赋值,而SpringMVC是通过方法的参数进行接收。
5、学习难度:Struts有更多的新技术点,比如拦截器、值栈及OGNL表达式,学习成本较高,SpringMVC比较简单,用较少的时间都能上手。
6、intercepter 的实现机制:struts有自己的interceptor机制,SpringMVC用的是独立的AOP方式。这样导致struts的配置文件量还是比SpringMVC大,虽然struts的配置能继承。所以理论使用上来讲,SpringMVC使用更加简洁,开发效率SpringMVC确实比struts2高。SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上SpringMVC就容易实现restful url。struts2是类级别的拦截,一个类对应一个request上下文;实现restful url要费劲,因为struts2 action的一个方法可以对应一个url;而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了。SpringMVC的方法之间基本上独立的,独享request、response数据,请求数据通过参数获取,处理结果通过ModelMap交回给框架,方法之间不共享变量,而struts2搞的就比较乱,虽然方法之间也是独立的,但其所有Action变量是共享的,这不会影响程序运行,却给我们编码,读程序时带来麻烦。
7、SpringMVC处理ajax请求,直接通过返回数据,方法中使用注解@ResponseBody,SpringMVC自动帮我们对象转换为JSON数据。而struts2是通过插件的方式进行处理。
在SpringMVC流行起来之前,Struts2在MVC框架中占核心地位,随着SpringMVC的出现,SpringMVC慢慢的取代struts2,但是很多企业都是原来搭建的框架,使用Struts2较多。
50. Spring两大核心IOC与AOP
50.1、IoC(Inversion of Control)
IOC的基本概念是:不创建对象,但是描述创建它们的方式。在代码中不直接与对象和服务连接,但在配置文件中描述哪一个组件需要哪一项服务。容器负责将这些联系在一起。
其原理是基于OO设计原则的The Hollywood Principle:Don’t call us, we’ll call you(别找我,我会来找你的)。也就是说,所有的组件都是被动的(Passive),所有的组件初始化和调用都由容器负责。组件处在一个容器当中,由容器负责管理。
简单的来讲,就是由容器控制程序之间的关系,而非传统实现中,由程序代码直接操控。这也就是所谓“控制反转”的概念所在:控制权由应用代码中转到了外部容器,控制权的转移,是所谓反转。
(1)IoC(Inversion of Control)是指容器控制程序对象之间的关系,而不是传统实现中,由程序代码直接操控。控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。对于Spring而言,就是由Spring来控制对象的生命周期和对象之间的关系;IoC还有另外一个名字——“依赖注入(Dependency Injection)”。从名字上理解,所谓依赖注入,即组件之间的依赖关系由容器在运行期决定,即由容器动态地将某种依赖关系注入到组件之中。
(2)在Spring的工作方式中,所有的类都会在spring容器中登记,告诉spring这是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
(3)在系统运行中,动态的向某个对象提供它所需要的其他对象。
(4)**依赖注入的思想是通过反射机制实现的,**在实例化一个类时,它通过反射调用类中set方法将事先保存在HashMap中的类属性注入到类中。
总而言之,在传统的对象创建方式中,通常由调用者来创建被调用者的实例,而在Spring中创建被调用者的工作由Spring来完成,然后注入调用者,即所谓的依赖注入or控制反转。
注入方式有两种:依赖注入和设置注入;
IoC的优点:降低了组件之间的耦合,降低了业务对象之间替换的复杂性,使之能够灵活的管理对象。
50.2、AOP(Aspect Oriented Programming)
AOP即Aspect-Oriented Programming的缩写,中文意思是面向切面编程,也有译作面向方面编程的,因为Aspect有“方面、见地”的意思。AOP实际上是一种编程思想,由Gregor Kiczales在Palo Alto研究中心领导的一个研究小组于1997年提出。在传统的面向对象(Object-Oriented Progr amming,OOP)编程中,对垂直切面关注度很高,横切面关注却很少,也很难关注。也就是说,我们利用OOP思想可以很好的处理业务流程,却不能把系统中的某些特定的重复性行为封装在某个模块中。比如在很多的业务中都需要记录操作日志,结果我们不得不在业务流程种嵌入大量的日志记录代码。无论是对业务代码还是对日志记录代码来说,今后的维护都是非常复杂的。由于系统种嵌入了这种大量的与业务无关的其它重复性代码,系统的复杂性、代码的重复性增加了,从而使bug的发生率也大大的增加。
在OOP面向对象编程中,我们总是按照某种特定的执行顺序来实现业务流程,各个执行步骤之间是相互衔接、相互耦合的。比如某个对象抛出了异常,我们就必须对异常进行处理后才能进行下一步的操作;又比如我们要把一个学生记录插入到教务管理系统的学生表中去,那么我们就必须按照注册驱动程序、连接数据库、创建 一个statement、生成并执行SQL语句、处理结果、关闭JDBC对象等步骤按部就班的编写我们的代码。可以看到上面的步骤种除了执行SQL和处理结果是我们业务流程所必须的外,其它的都是重复的准备和殿后工作,与业务流程毫无关系,另外我们还得要考虑程序执行过程中的异常。天!我们只是需要向一张表中插入数据而已,可是却不得不和这些大量的重复代码纠缠在一起,我们不得不把大量的精力用在这些代码上而无法专心的设计业务流程。
那么什么可以解决这个问题呢?这时候,我们需要AOP,关注系统的“截面”,在适当的时候“拦截”程序的执行流程,把程序的预处理和后处理交给某个拦截器来完成。比如在操作数据库时要记录日志,如果使用AOP的编程思想,那么我们在处理业务流程时不必再考虑日志记录,而是把它交给一个特定的日志记录模块去完成。这样,业务流程就完全的从其它无关的代码中解放出来,各模块之间的分工更加明确,程序维护也变得容易多了。
正如上所说,AOP不是一种技术,而是编程思想。凡是符合AOP思想的技术,都可以看成是AOP的实现。目前的AOP实现有AspectJ、 JBoss4.0、nanning、spring等项目。其中Spring对AOP进行了很好的实现,同时Spring AOP也是Spring的两大核心之一。
下面介绍一些关于AOP的一些概念:
连接点(join point): 它是指应用中执行的某个点,即程序执行流程中的某个点。如执行某个语句或者语句块、执行某个方法、装载某个类、抛出某个异常……,如下:
public static void main(String[] args) throws Exception {
int i = 0;
i++;
CallMyMethod();
throw new Exception( "哈哈,一个异常!" );
}
注意:这里每一个语句都可以被称作一个连接点。
连接点是有“强弱”的,这种强弱可以用“粒度”来表示,Spring AOP支持到方法级的连接点粒度。
切入点(pointcut): 切入点是连接点的集合,它通常和装备联系在一起,是切面和程序流程的交叉点。比如说,定义了一个pointcut,它将抛出异常ClassNotFoundException和某个装备联系起来,那么在程序执行过程中,如果抛出了该异常,那么相应的装备就会被触发执行。
装备(advice): 也可以叫做“通知”,指切面在程序运行到某个连接点所触发的动作。在这个动作中我们可以定义自己的处理逻辑。装备需要利用切入点和连接点联系起来才会被触发。目前AOP定义了五种装备:前置装备(Before advice)、后置装备(After advice)、环绕装备(Around Advice)、异常装备(After throwing advice)、返回后装备(After returning advice)。
目标对象(target object): 被一个或者多个切面装备的对象。所以它有时候也被称为Advised Object。
引入(introduction): 声明额外的成员字段或者成员方法。它可以给一个确定的对象新增某些字段或者方法。
织入(weaving): 将切面和目标对象联系在一起的过程。这个过程可以在编译期完成,也可以在类加载时和运行时完成。Spring AOP是在运行期完成织入的。
切面(aspect): 一个关注点的模块化。它实际上是一段将被织入到程序流程中的代码。
(1)AOP面向方面编程基于IoC,是对OOP的有益补充;
(2)AOP利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其命名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,比如日志记录,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。
(3)AOP代表的是一个横向的关系,将“对象”比作一个空心的圆柱体,其中封装的是对象的属性和行为;则面向方面编程的方法,就是将这个圆柱体以切面形式剖开,选择性的提供业务逻辑。而剖开的切面,也就是所谓的“方面”了。然后它又以巧夺天功的妙手将这些剖开的切面复原,不留痕迹,但完成了效果。
(4)实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
(5)Spring实现AOP:JDK动态代理和CGLIB代理
JDK动态代理:其代理对象必须是某个接口的实现,它是通过在运行期间创建一个接口的实现类来完成对目标对象的代理;其核心的两个类是InvocationHandler和Proxy。
CGLIB代理:实现原理类似于JDK动态代理,只是它在运行期间生成的代理对象是针对目标类扩展的子类。CGLIB是高效的代码生成包,底层是依靠ASM(开源的java字节码编辑类库)操作字节码实现的,性能比JDK强;需要引入包asm.jar和cglib.jar。
使用AspectJ注入式切面和@AspectJ注解驱动的切面实际上底层也是通过动态代理实现的。
(6)AOP使用场景:
Authentication 权限检查
Caching 缓存
Context passing 内容传递
Error handling 错误处理
Lazy loading 延迟加载
Debugging 调试
Logging,tracing,profiling and monitoring 日志记录,跟踪,优化,校准
Performance optimization 性能优化,效率检查
Persistence 持久化
Resource pooling 资源池
Synchronization 同步
Transactions 事务管理
另外Filter的实现和struts2的拦截器的实现都是AOP思想的体现。