软件测试总结——常见的面试问题(三)
自动化测试软件作用(重点):
一:jmeter: 纯java编写负载功能测试和性能测试开源工具, 支持接口自动化测试,录制、抓包、可进行压力测试(增加线程,考验服务器最大支持访问数)、弱网测试、添加请求、添加断言,查看断言、结果树,聚合报告,分析测试报告等
聚合报告参数详解:
1. Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
2. Samples:请求数——表示这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
3. Average:平均响应时间——默认情况下是单个 Request 的平均响应时间
4. Median:中位数,也就是 50% 用户的响应时间
5. 90% Line:90% 用户的响应时间
6. Min:最小响应时间
7. Max:最大响应时间
8. Error%:错误率——错误请求数/请求总数
9. Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second)
10. KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
二:ant: 将软件编译、测试、部署等步骤联系在一起加以自动化的一个工具,并生成测试报告并发送
三:jenkins: Jenkins是一个开源CI服务器,基于Web访问,jenkins是基于Java开发的一种持续集成工具,用于监控持续重复的工作,能实时监控集成中存在的错误,提供详细的日志文件和提醒功能,还能用图表的形式形象地展示项目构建的趋势和稳定性,拥有大量的插件:这些插件极大的扩展了Jenkins的功能,持续集成工具,所有工作都是自动完成的,无需太多的人工干预,有利于减少重复过程以节省时间和工作量;
四:monkey:它是Android SDK系统自带一个命令行工具,可以运行在模拟器里或者真是设备中运行。向系统发送伪随机的用户事件流,实现对正在开发的应用程序进行稳定性测试。
五:charles: 1.抓包(http、https):设置手机HTTP代理、https charles也需要证书
2.弱网测试:通过Throttle Settings(网络控制)、Enable Throttling(启用设置)、Throttle preset(通过预设网络值来拟定网络)、设置网络带宽值等
3.网络请求的截取并动态修改:
4.压力测试:通过右键点击链接,Repeat Advanced(重复),选择Iterations(重复次数)Concurrency(并发数)
5.数据替换:通过链接右键点击Map Local(本地位置)进入设置,选择替换数据文件,替换即可
六:selenium :web自动化测试框架(测试浏览器兼容性的自动化)selenium不支持桌面软件自动化测试。软件测试报告,和用例管理只能依赖第三方插件unittest优点:兼容更多的平台( Windows、Linux 、 Macintosh等)以及浏览器(火狐,IE,谷歌等)
定位元素方式:id、name、class_name、tagname、link_text、partial_link_text、xpath、css_selector
强制等待:sleep()强制等待,不管你浏览器是否加载完,程序都得等待
显示等待:WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了.它主要的意思就是:程序每隔多久查看一次,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException
隐式等待:implicitly_wait(),整个driver周期有效,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止
七:appium:开源测试自动化框架,可用于原生,混合和移动Web应用程序测试
两大组件:
一:Appium Server就是Appium的服务端——一个web接口服务,使用Node.js实现。
二:Appium Desktop是一款适用于Mac,Windows和Linux的开源应用程序,提供Appium自动化服务器的强大功能。
Appium GUI是Appium desktop的前身。 也就是把Appium server封装成了一个图形界面,降低了使用门槛。
因为Appium是一个C/S结构,有了服务端的肯定还有客户端,Appium Clients就是客户端,它会给服务端Appium Server发送请求会话来执行自动化任务。
Appium-desktop主界面包含三个菜单:
Simple
- host:设置Appium server的ip地址,本地调试可以将ip地址修改为127.0.0.1
- port:设置端口号,默认是4723不用修改
-
start server:启动 Appium server
Advanced:高级参数配置修改,主要是Android和iOS设备,log路径等相关信息的配置。
Presets:将Advanced中的一些配置信息作为预设配置。
八:pytest:pytest是一个全功能的Python测试框架,
优点:
- 1、简单灵活,容易上手,文档丰富;
- 2、支持参数化,可以细粒度地控制要测试的测试用例;
- 3、能够支持简单的单元测试和复杂的功能测试,还可以用来做selenium/appnium等自动化测试、接口自动化测试(pytest+requests);
- 4、pytest具有很多第三方插件,并且可以自定义扩展,比较好用的如pytest-selenium(集成selenium)、pytest-html(完美html测试报告生成)、pytest-rerunfailures(失败case重复执行)、pytest-xdist(多CPU分发)等;
- 5、测试用例的skip和xfail处理;
- 6、可以很好的和CI工具结合,例如jenkins
编写规则:
- 测试文件以test_开头(以_test结尾也可以)
- 测试类以Test开头,并且不能带有 init 方法
- 测试函数以test_开头
- 断言使用基本的assert即可
# -*- coding:utf-8 -*-
import pytest
@pytest.fixture(scope='function')
def setup_function(request):
def teardown_function():
print("teardown_function called.")
request.addfinalizer(teardown_function) # 此内嵌函数做teardown工作
print('setup_function called.')
@pytest.fixture(scope='module')
def setup_module(request):
def teardown_module():
print("teardown_module called.")
request.addfinalizer(teardown_module)
print('setup_module called.')
@pytest.mark.website
def test_1(setup_function):
print('Test_1 called.')
def test_2(setup_module):
print('Test_2 called.')
def test_3(setup_module):
print('Test_3 called.')
assert 2==1+1 # 通过assert断言确认测试结果是否符合预期fixture的scope参数
scope参数有四种,分别是'function','module','class','session',默认为function。
- function:每个test都运行,默认是function的scope
- class:每个class的所有test只运行一次
- module:每个module的所有test只运行一次
- session:每个session只运行一次
setup和teardown操作
- setup,在测试函数或类之前执行,完成准备工作,例如数据库链接、测试数据、打开文件等
- teardown,在测试函数或类之后执行,完成收尾工作,例如断开数据库链接、回收内存资源等
- 备注:也可以通过在fixture函数中通过yield实现setup和teardown功能
九:unitest: unittest单元测试框架不仅可以适用于单元测试,还可以适用WEB自动化测试用例的开发与执行,该测试框架可组织执行测试用例,并且提供了丰富的断言方法,判断测试用例是否通过,最终生成测试结果
unittest.TestCase:TestCase类,所有测试用例类继承的基本类: class BaiduTest(unittest.TestCase)
unittest.main():将一个单元测试模块变为可直接运行的测试脚本,main()方法使用TestLoader类来搜索所有包含在该模块中以“test”命名开头的测试方法并自动执行他们。
unittest.TestSuite():unittest框架的TestSuite()类是用来创建测试套件的。
unittest.TextTextRunner():unittest框架的TextTextRunner()类,通过该类下面的run()方法来运行suite所组装的测试用例。
unittest.defaultTestLoader(): defaultTestLoader()类,通过该类下面的discover()方法可自动更具测试目录start_dir匹配查找测试用例文件(test*.py),并将查找到的测试用例组装到测试套件,因此可以直接通过run()方法执行discover。用法如下:discover=unittest.defaultTestLoader.discover(test_dir, pattern='test_*.py')
unittest.skip():装饰器,当运行用例时,有些用例可能不想执行等,可用装饰器暂时屏蔽该条测试用例。一种常见的用法就是比如说想调试某一个测试用例,想先屏蔽其他用例就可以用装饰器屏蔽。
TestCase类的属性:
setUp():setUp()方法用于测试用例执行前的初始化工作。如测试用例中需要访问数据库,可以在setUp中建立数据库连接并进行初始化。如测试用例需要登录web,可以先实例化浏览器。
tearDown():tearDown()方法用于测试用例执行之后的善后工作。如关闭数据库连接。关闭浏览器。
assert*():一些断言方法:在执行测试用例的过程中,最终用例是否执行通过,是通过判断测试得到的实际结果和预期结果是否相等决定的。
TestSuite类的属性:
addTest(): addTest()方法是将测试用例添加到测试套件中,是将test_baidu模块下的BaiduTest类下的test_baidu测试用例添加到测试套件。 suite = unittest.TestSuite() suite.addTest(test_baidu.BaiduTest('test_baidu'))
TextTextRunner的属性:
run(): run()方法是运行测试套件的测试用例,入参为suite测试套件: runner = unittest.TextTestRunner() runner.run(suite)
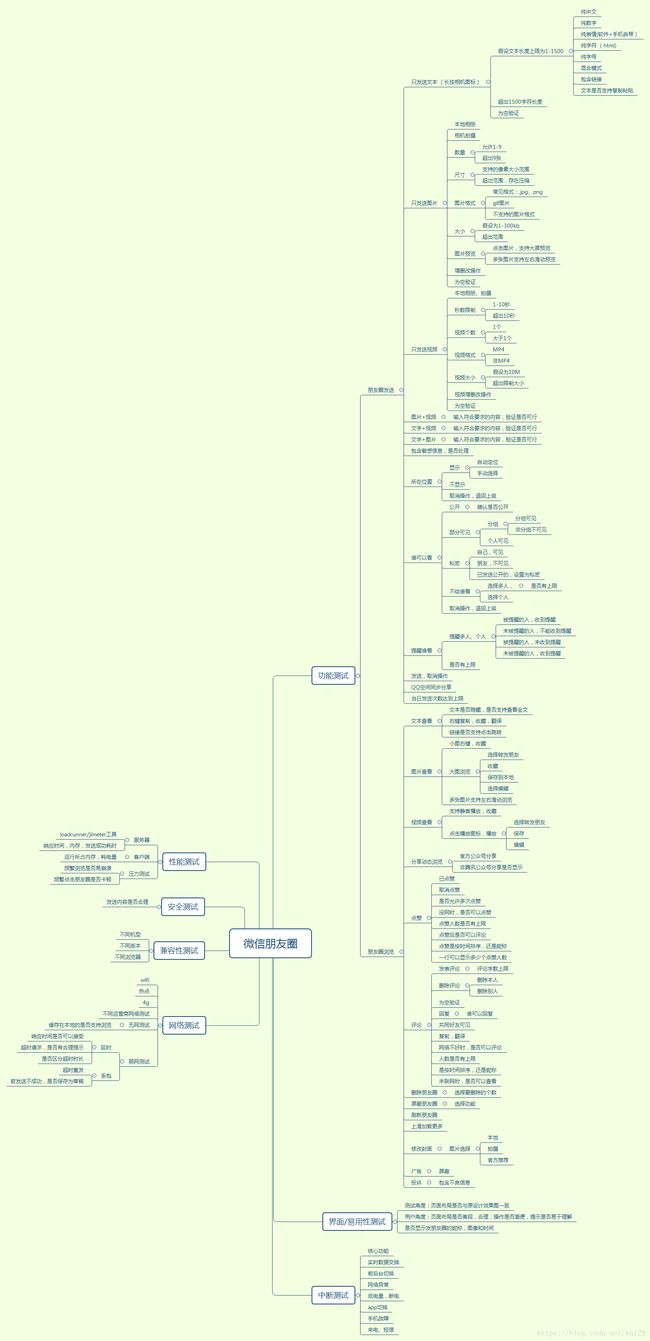
微信朋友圈测试用例:
关系型数据库:
- 关系型数据库是依据关系模型来创建的数据库。
- 所谓关系模型就是“一对一、一对多、多对多”等关系模型,关系模型就是指二维表格模型,因而一个关系型数据库就是由二维表及其之间的联系组成的一个数据组织。
- 关系型数据可以很好地存储一些关系模型的数据,比如一个老师对应多个学生的数据(“多对多”),一本书对应多个作者(“一对多”),一本书对应一个出版日期(“一对一”)
- 关系模型是我们生活中能经常遇见的模型,存储这类数据一般用关系型数据库
- 关系模型包括数据结构(数据存储的问题,二维表)、操作指令集合(SQL语句)、完整性约束(表内数据约束、表与表之间的约束)。
- 常见的关系型数据库:Oracle、MySQL、DB2、PostgreSQL、Microsoft SQL Server、Microsoft Access
- 关系型数据库的特点:安全(因为存储在磁盘中,不会说突然断电数据就没有了)、容易理解(建立在关系模型上)、
但不节省空间(因为建立在关系模型上,就要遵循某些规则,好比数据中某字段值即使为空仍要分配空间)
非关系型数据库:
非关系型数据库主要是基于“非关系模型”的数据库(由于关系型太大,所以一般用“非关系型”来表示其他类型的数据库)
列模型:存储的数据是一列列的。关系型数据库以一行作为一个记录,列模型数据库以一列为一个记录。(这种模型,数据即索引,IO很快,主要是一些分布式数据库)
键值对模型:存储的数据是一个个“键值对”,比如name:liming,那么name这个键里面存的值就是liming
常见非关系模型数据库:列模型:Hbase、键值对模型:redis,MemcacheDB、文档类模型:mongoDB
非关系型数据库的特点:效率高(因为存储在内存中)、但不安全(断电丢失数据,但其中redis可以同步数据到磁盘中),现在很多非关系型数据库都开始支持转存到磁盘中。
MySQL外连接、内连接的区别?
left join (左连接):返回包括左表中的所有记录和右表中连接字段相等的记录。
right join (右连接):返回包括右表中的所有记录和左表中连接字段相等的记录。
inner join (等值连接或者叫内连接):只返回两个表中连接字段相等的行。内连接是交集
full join (全外连接):返回左右表中所有的记录和左右表中连接字段相等的记录。外连接是并集(union)
多表联查-- 2.查询科目为java的最高成绩的学生名字和编号
SELECT stu1.sname,stu1.sid,i.subname,MAX(i.cj) FROM (SELECT stu3.subname,stu2.sid,stu2.cj FROM stu3 INNER JOIN stu2 ON stu3.subid = stu2.subid WHERE subname LIKE "java") i INNER JOIN stu1 ON i.sid = stu1.sid
+-----+------+------+-------+------------+--------------+--------+-------+
多表联查-- 3.查询名字为李四的所有科目总成绩
SELECT stu1.sname,SUM(stu2.cj) FROM stu1 INNER JOIN stu2 ON stu1.sid = stu2.sid where sname LIKE "李四"
数据库常用方法:
增:Insert into 表名 value 值
删:Delect from 表名 where 值
改:Update 表名 set 字段=字段 where 字段;
查:Select * from 表名
自增 auto_increment
主键 primary key
非空 not null
唯一 unique
默认值 default
外键 foreign key
查看所有的表 SHOW TABLES ;
创建一个表 CREATE TABLE n(id INT, name VARCHAR(10));
# 添加字段: Alter table 表名 add 字段名 数据类型Alter table n ADD age VARCHAR(2) ;
# 删除字段: Alter table 表名 drop 字段名
# 更改字段属性和属性:Alter table n CHANGE age a INT;
# 只更改字段属性:Alter table n MODIFY age VARCHAR(7) ;
增加数据 INSERT INTO n VALUES (1, 'tom', '23'), (2, 'john', '22');
删除数据:DELETE FROM n WHERE id = 2;
更改数据:UPDATE n SET name = 'tom' WHERE id = 2;
数据查找 : SELECT * FROM n WHERE name LIKE '%h%';
数据排序(order by)(反序) :Select * from 表名 order by stu_age asc/desc
分组查询(group by):Select * from 表名 group by sex =‘男’
总 数(count) SELECT count(id) AS total FROM n;
总 和(sum) SELECT sum(age) AS all_age FROM n;
平均值(avg) SELECT avg(age) AS all_age FROM n;
最大值(max) SELECT max(age) AS all_age FROM n;
最小值(min) SELECT min(age) AS all_age FROM n;
Linux:
如何杀死一个进程:1.先查找进程号:ps -ef | grep 进程(例如:tomcat) 2.杀死进程:kill -9 进程号
查看进程和端口号的使用情况:netstat -tunlp|grep
查看端口号被占用:netstat -anp | grep 端口号 查看是start状态还是stop状态
查看内存:cat /proc/meminfo
查看cpu:cat /proc/cpuinfo
进入根目录:cd/
返回上层:cd..
更新:source
显示工作路径:pwd
查看目录中的文件 :ls
编辑:vi
编辑保存:wq
删除目录:rmdir
创建目录:mkdir
查找文件:find
解压:tar -vxzf
显示当前进程:ps
如何通过子元素定位父元素:1.可以使用..代表的是父节点 2.可以使用parent来定位父类元素
Android手机和IOS手机,系统有什么区别?
1、两者运行机制不同:IOS采用的是沙盒运行机制,安卓采用的是虚拟机运行机制。
2、两者后台制度不同:IOS中任何第三方程序都不能在后台运行;安卓中任何程序都能在后台运行,直到没有内存才会关闭。
3、IOS中用于UI指令权限最高,安卓中数据处理指令权限最高。
Android:一:兼容性测试,Android 从4.0版本的手机测试到9.0版本手机。二:各大品牌的手机都的进行测试,比如:小米小米9 小米8 小米7 小米6 note 红米系列 7红米5,华为: 华为mate20 华为mate10,华为荣耀: 荣耀10,9,8 ,vivo: x21,27,23,oppo: R7,R9,R11,三星手机: note9, 8,7 S9,8。三:稳定性测试: 使用monkey命令进行稳定性测试
ios:兼容性测试:ios版本测试从9-12,手机型号从4S测试到xmax
web端测试:兼容性测试:IE浏览器7-12,火狐浏览器 35-最新的,谷歌浏览器,(http、https)
不可逆操作如何处理:如删除订单:
1.假删除(修改删除标识即可)
2.真删除就真的删除了,为不可恢复状态,除非再新建订单重新执行流程
在测试中,上下游接口有数据依赖如何处理(下个接口用到上个接口的数据):
1.使用静态值,给定一个符合条件的死数据
2.或者从数据库中直接获取数据
软件的生命周期:1.产品收集市场需求,2.需求分析,3.产品设计需求,4.UI界面设计,5.前后台开发,设计数据库表、框架,编码,6.版本测试,7.产品上线,8.产品运营