leetcode 二分查找和二叉查找树
文章目录
- 1.二分查找预备知识
- 二分查找
- 思路
- 代码(递归版本)
- 代码(非递归版本)
- 2.搜索插入位置
- 题目 (Leetcode35)
- 思路
- 代码
- 3.区间查找
- 题目 (Leetcode34)
- 思路
- 代码
- 4.旋转数组查找
- 题目 (Leetcode33)
- 思路
- 代码
- 6.二叉搜索树
- 题目 (二叉搜素树基础)
- 二叉搜索树插入
- 二叉搜索树插入
- 5.二叉树的编码和解码
- 题目 (Leetcode199)
- 思路
- 代码
- 6.计算右侧小于当前元素的个数
- 题目 (Leetcode315)
- 思路
- 代码
1.二分查找预备知识
二分查找
给定一个数字target,在有序序列中查找
二分查找的前提就是序列是有序的,使用分治的思想,逐渐缩小查找区间,使得查找时间复杂度为O(logn)
思路
使用begin ,end 两个指针分别指向数组的开始和结尾,mid指向数组中间元素,如果待查找的元素target==arr[mid],查找到元素直接返回,,则target>arr[mid] 则说明target在【mid+1,end】,否则target在【begin,mid-1】之间
通过迭代不断的缩小查找范围,当缩小到begin>end的时候则表示没有查找到
代码(递归版本)
bool binary_search(vector<int>&arr,int &target,int begin,int end)
{
if(begin>end) //查找区间已经不合法了,则表示没有查找到
return false;
int mid = (begin+end)/2;
if(target==arr[mid])
return true;
if(target>arr[mid]) //taget大于中间值,则target应该在【mid+1,end】之间,所以修改begin=mid+1
begin=mid+1;
else
end = mid-1; //taget小于中间值,则target应该在【begin,mid-1】之间,所以修改end = mid-1
//缩小查找范围后递归查找
return binary_search(arr,target,begin,end);
}
//单纯具有分治思想的递归程序适合用while来改写,能够提高效率,但是对于有回溯思想的不适合用while的方式查找
代码(非递归版本)
bool binary_search(vector<int>&arr,int &target)
{
bool found = false;
int mid;
while(begin<end) //当区间合法时则循环查找
{
int mid = (begin+end)/2;
if(target==arr[mid])
{
found = true;
break;
}
if(target>arr[mid]) //taget大于中间值,则target应该在【mid+1,end】之间,所以修改begin=mid+1
{
begin=mid+1;
}
else
{
end = mid-1; //taget小于中间值,则target应该在【begin,mid-1】之间,所以修改end = mid-1
}
}
return found;
}
2.搜索插入位置
题目 (Leetcode35)
给定一个排序数组(无重复元素)和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
示例:
2不在【1,3,5,6】中,返回插入位置1
3在【1,3,5,6】中,返回实际位置1

思路
因为给定数组是一个排序数组—>有序数组,且没有重复元素,正好适合二分查找的应用场景,只不过查找之后返回值不再是true和false,而是查找到位置下标,如果没有查找到则返回要插入的位置:
现在分析没有查找到情况(也就是target位于两个元素之间),分析的时候我们以mid作为参考:
- 如果过target
- 其中细节需要注意的是由于target>arr[mid-1]要比较,如果mid0,可能会越界,例如查找-2时,找到最后mid0了,begin==0,这时候已经说明找不到,而且插入位置,就应该mid等于0的位置,需要特殊考虑
- 总结一下规律如下:

代码
class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
//设定开始搜素区间
int begin=0;
int end = nums.size()-1;
int mid;
int index =-1; //表示还没有确定索引值
while(index==-1)
{
mid = (begin+end)/2;
if(nums[mid]==target)
{
index = mid;
}
else if(target<nums[mid]) //target比mid小,则要往前查找,但是要判断target是否在【mid-1,mid】之间
{
if((mid==0) ||(target>nums[mid-1])) //如果target在[mid-1,mid]之间,则说明不在数组中,修改索引准备返回,mid==0要提前判断,作为边界条件
index =mid; //修改了index下一次循环就退出了
end = mid-1;
}
else //target>nums[mid]
{
if((mid==nums.size()-1)||(target<nums[mid+1])) //target在【mid,mid+1】之间,不在数组中,修改index
index = mid+1;
begin =mid+1;
}
}
return index;
}
};
3.区间查找
题目 (Leetcode34)
给定一个按照升序排列的整数数组 nums(可能存在重复元素),和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。你的算法时间复杂度必须是 O(log n) 级别。如果数组中不存在目标值,返回 [-1, -1]。
例如:

思路
分析:
因为数组中可能存在重复元素,例如查找元素8的时候,通过二分查找,可能查找其他某一个8,确不能确定是第一个8还是第二个8,所有单纯的二分查找不能完成。
- 因为要查找一个去区间,区间包含左右两个端点,那能不能通过限制条件分别求出左右端点呢?
- 以左端点为例:区间左端点具有的性质,首先要查找到这个元素,即target==arr[mid],同时由于是左端点,那么arr[mid-1]应该不等于target才可以,更确切的说arr[mid-1]
- 同样由于要访问arr[mid-1],要提前判断mid是否为0

- 查找左端点条件 :targetarr[mid] 的情况下(mid0 || target>arr[mid-1]),则说明找到左边界,返回,否则按照二分查找的思路缩小查找返回
- 查找右端点同理
- 同样由于要访问arr[mid-1],要提前判断mid是否为0
代码
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
vector<int>bound;
bound.push_back(left_bound(nums,target));
bound.push_back(right_bound(nums,target));
return bound;
}
private:
int left_bound(vector<int>&nums,int target)
{
int begin =0;
int end = nums.size()-1;
int mid;
while(begin<=end)
{
//搜仙判断是否为左边界
mid = (begin+end)/2;
if(target==nums[mid])
{
if(mid==0 || nums[mid-1]<target) //找到左边界,返回
return mid;
//如果mid-1,也等于target,说明不是最左边那个target,还得向左走
end =mid-1; //向左搜素
}
else if(target<nums[mid])
end = mid-1;
else
begin = mid+1;
}
return -1;//未搜素到
}
int right_bound(vector<int>&nums,int target)
{
int begin =0;
int end = nums.size()-1;
int mid;
while(begin<=end)
{
//判断是否为左边界
mid = (begin+end)/2;
if(target==nums[mid])
{
if(mid==(nums.size()-1) || nums[mid+1]>target) //找到右边界,返回
return mid;
//如果mid+1,也等于target,说明不是最右边那个target,还得向右边
begin =mid+1; //向右搜素
}
else if(target<nums[mid])
end = mid-1;
else
begin = mid+1;
}
return -1;//未搜索到
}
};`
4.旋转数组查找
题目 (Leetcode33)
假设按照升序排序的数组(不存在重复的元素)在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。
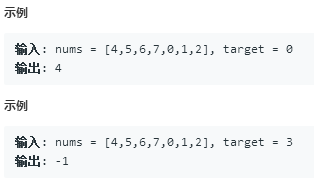
思路
旋转数组的特点:
- 是由一个有序数组循环移动得到,移动之后不再是一个有序数组
- 但却形成了两个有序的数组,如下图中红色线标记部分和未标记部分

如果依然采用二分查找的思路的话,由于数组总体不是有序的,则可能会出现错误

这里查找12的时候二分落到了有序区间【7,15】,循环查找可以找到它
但是这里3的时候二分落到了无序区间【20,6】,循环查找也找不到
考虑到二分查找只能在有序区间中查找,那我们能不能通过某些限定条件,来区分哪一部分是有序的,哪一部分是无序的呢?
-
因为旋转数组是由两个递增数组组成,第二个递增数组所有值都小于第一个递增数组,所以只要mid
-
找到了有序区间中判断我们查找的target ,是否真的在【mid+1,high】区间,如果目标在这个区间,则缩小查找范围lo=mid+1,否则转到无序数组,进行下一轮循环。

- 因为旋转数组是由两个递增数组组成,第二个递增数组所有值都小于第一个递增数组,所以只要mid>=high,那说明[low,mid-1]是递增区间,这个是有序区间
- 找到了有序区间中判断我们查找的target ,是否真的在【low,mid-1】区间,如果目标在这个区间,则缩小查找范围high=mid-1,否则转到无序数组,进行下一轮循环。

代码
class Solution{
public:
int search(vector<int>& nums, int target) {
if(nums.empty())
return -1;
int lo = 0, hi = nums.size() - 1;
int mid;
while(lo <= hi)
{
mid = (lo + hi) / 2;
if(nums[mid] == target)
return mid;
if(nums[mid] < nums[hi]) //mid
{//在这个有序区间中我们去二分查找我们的目标数据
if(nums[mid] < target && target <= nums[hi])//有序序列中查找
lo = mid + 1; //缩小有序序列查找范围
else
hi = mid - 1; //转到剩下的无序数组
}
else //mid>high,则说明mid和high之间是无序序列,所以(low,mid)之间是有序序列
{
//在这个有序区间中我们去二分查找我们的目标数据
if(nums[lo] <= target && target < nums[mid])
hi = mid - 1; //缩小有序数组的查找范围
else
lo = mid + 1; //转到剩下的无序数组
}
}
return -1;
}
};
6.二叉搜索树
题目 (二叉搜素树基础)
二叉搜索树的性质:
- 是一个完全二叉树
- 左子树中的值都比根节点小,右子树的值都比根节点大
- 最小值在左子树的最左节点,最大值在右子树的最右节点
- 二叉树的中序遍历结果是递增的有序序列
二叉搜索树插入
bool BST_Find(TreeNode*root,int val)
{
if(root==nullptr)
return false;
if(val==root->val)
return true;
//根据值的大小递归插入左子树、右子树
if(val<root->val) //小于当前值,在左子树中查找
return BST_Find(root->left,val);
else (val>root->val)) //大于当前值,在右子树中查找
return BST_Find(root->right,val);
}
二叉搜索树插入
void BST_Insert(TreeNode*root,TreeNode*insert_node)
{
if(root==nullptr)
{
root=insert_node; //遇到空节点的时候插入节点,并返回
return;
}
//根据值的大小递归插入左子树、右子树
if(insert_node->val<root->val) //小于当前值,插入左子树
BST_Insert(root->left,insert_node);
else if(insert_node->val > root->val) //大于当前值,插入右子树
BST_Insert(root->right,insert_node);
//else {} 相等则不用插入
}
}
5.二叉树的编码和解码
题目 (Leetcode199)
序列化是将数据结构或对象转换为一系列位的过程,以便它可以存储在文件或内存缓冲区中,或通过网络连接链路传输,以便稍后在同一个或另一个计算机环境中重建。

思路
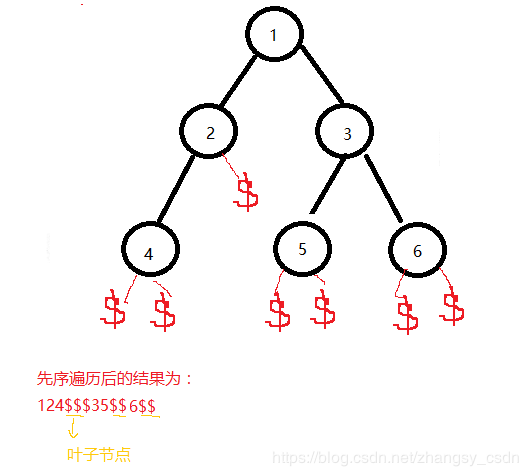
在序列化的时候我们使用先序遍历,在每个空的节点位置用 来 填 充 , 如 下 图 我 们 可 以 得 到 序 列 化 后 的 数 组 为 : 124 来填充,如下图我们可以得到序列化后的数组为:124 来填充,如下图我们可以得到序列化后的数组为:124$ $ 3 5 6 6 6
在反序列化的过程中,
先考虑如果左右子树都已经构建好了,对于当前节点应该怎么处理
:如果该节点为有效数字应该将左右子树连接起来,如果该节点为“$”则说明传入的是叶子节点的空指针,不用处理,作为递归返回的条件
这里的举例是用的个位数表示的节点,实际中节点中的数字可能为多位数,比如最后一个节点数据变成67后,如果不加区分,不知道是一个节点的值为67,还是两个节点,一个为6,一个为7,因此为了容易区分这里加入逗号分隔符号
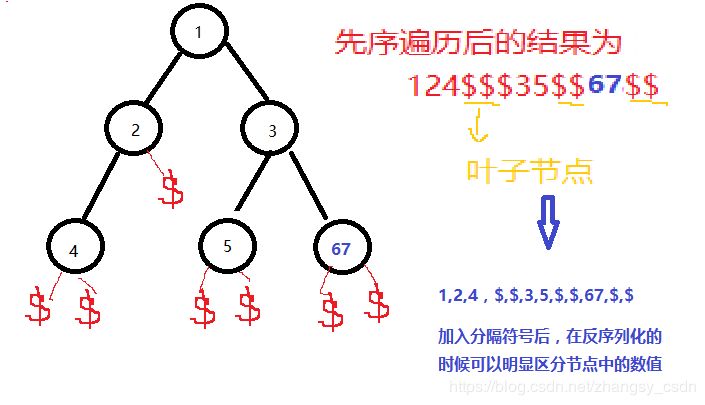
- 辅助代码:需要一个int2string和string2int的代码
- int2string思路就是int数对10取余,得到最后一位,除以10后更新,循环获得每一位变成字符
- string2int思路:从高位开始,没获得一位乘以10之后加上后面的值
代码
//序列化二叉树
class Codec {
string int2string(int val) {
string str;
string str_reverse;
while (val) {
str += val % 10 + '0';
val = val / 10;
}
for (int i = str.length() - 1; i >= 0; i--)
str_reverse += str[i];
return str_reverse;
}
int string2int(string str) {
int val = 0;
for (int i = 0; i<str.length(); i++) {
val = val * 10 + str[i] - '0';
}
return val;
}
void serializeCore(TreeNode* root, string&str) {
//使用先序遍历序列化二叉树
if (root == nullptr) {
str += "$"; //空节点用$符号代替
str += ","; //用逗号作为分割符号
return;
}
//如果有值,则转化为字符串
str += int2string(root->val);
str += ','; //用逗号作为分割符号
//序列化左子树,右子树
serializeCore(root->left, str);
serializeCore(root->right, str);
}
vector<string> split(string& str, string&delim) { //将分割后的子字符串存储在vector中
vector<string> res;
if ("" == str) return res;
string strs = str + delim; //*****扩展字符串以方便检索最后一个分隔出的字符串
size_t pos;
size_t size = strs.size();
for (int i = 0; i < size; ++i) {
pos = strs.find(delim, i); //pos为分隔符第一次出现的位置,从i到pos之前的字符串是分隔出来的字符串
if (pos < size-1) { //如果查找到,如果没有查找到分隔符,pos为string::npos
string s = strs.substr(i, pos - i);//*****从i开始长度为pos-i的子字符串
res.push_back(s);//两个连续空格之间切割出的字符串为空字符串,这里没有判断s是否为空,所以最后的结果中有空字符的输出,
i = pos + delim.size() - 1;
}
}
return res;
}
/*---------------------
来源:CSDN
原文:https://blog.csdn.net/Mary19920410/article/details/77372828
版权声明:本文为博主原创文章,转载请附上博文链接!
*/
void deserializeCore(TreeNode*&root, vector<string> &str, int &index)
{
if (index>str.size() - 1) return;
//从string 里面读取数据
string tmp = str[index];
index += 1;
if (tmp.length() == 1 && tmp[0] == '$')//如果是空节点,则跳过不构造树
{
return;
}
//如果是数组,则转化为数字
int val = string2int(tmp);
root = new TreeNode(val); //创建节点
//继续读取数据创建左子树,右子树
deserializeCore(root->left, str, index);
deserializeCore(root->right, str, index);
}
public:
// Encodes a tree to a single string.
string serialize(TreeNode* root) {
string str;
serializeCore(root, str);
return str;
}
// Decodes your encoded data to tree.
TreeNode* deserialize(string data) {
string del;
TreeNode*root = nullptr;
int index = 0;
del += ',';
vector<string> str = split(data, del);
deserializeCore(root, str, index);
return root;
}
};
6.计算右侧小于当前元素的个数
题目 (Leetcode315)
给定一个整数数组 nums,按要求返回一个新数组 counts。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。

思路
最笨的办法就是,遍历每个元素,统计它后面的元素比它小的元素个数,时间复杂度为O(n^2)
另外这个题目统计的是后面的元素比当前元素小的个数,由于数据是顺序读入的,如果正访问当前元素,后面的元素还没有读入内存,不适合统计
因此可以考虑将数据逆置之后再考虑,逆置之后题目就转化为当前元素前面的元素比它小的个数
要统计A(i)前面的数据比A(i)小的个数,最好在A输入之前的其他元素A(i-1),A(i-2)等元素能够具备该性质,即A(i-1)有一个属性count记录比A(i-1)小的元素个数,A(i-2)有个属性count记录比A(i-2)小的元素个数,这样的话,最好A(i-1),A(i-2)是有序的,当我们新输入A(i)时候我们只用让A(i)与A(i-1)比较,如果比A(i-1)大,则A(i)的count 直接等于A(i-1)的count+1,否则继续和A(i-2)比较
基于以上分析,我们发现使用二叉查找树在构建的时候有一个比较的过程,同时能够保证有序,只不过我们要自己给每个节点定义一个count,如下所示:****

构建完成后树的中信息如下:
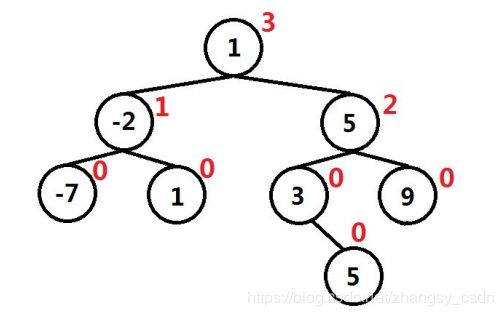
如果要对比它小的元素计数,其中某个状态,如插入第二个5的时候的流程如下
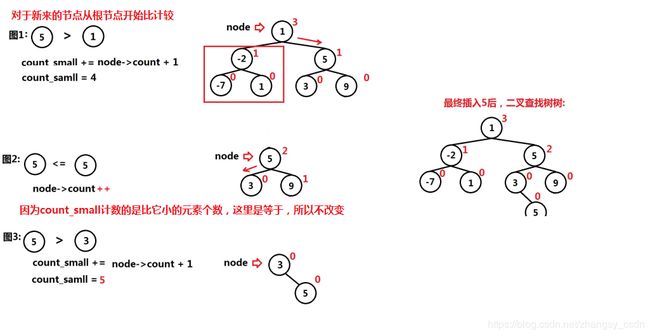
代码
class Solution
{
struct BSTNode
{
int val;
int cnt; //记录比当前元素小的元素个数
BSTNode* left;
BSTNode* right;
BSTNode(int x):val(x),cnt(0),left(NULL),right(NULL){}
};
public:
vector<int> countSmaller(vector<int> &nums)
{
vector<int>result;
vector<BSTNode*> node_vec; //为了构建二叉树,分配节点内存,节点池
if(nums.size()==0) return result;
//new出新的节点放在节点池中
for(int i=nums.size()-1;i>=0;i--) //同时逆序
{
node_vec.push_back(new BSTNode(nums[i]));
}
vector<int>count; //存储比当前节点小的元素个数,count反转一下就是result
count.push_back(0); //第一个插入的节点的count_small=0
//将每个元素依次插入到二叉搜索树中,每次插入都计算插入节点时,比当前节点小的元素个数
for(int i=1;i<node_vec.size();i++)
{
int cnt =0; //每次插入都计算插入节点时,比当前节点小的元素个数
BST_Insert(node_vec[0],node_vec[i],cnt);
count.push_back(cnt);
}
//回收内存
for(int i=0;i<node_vec.size();i++)
delete node_vec[i];
for(int i=count.size()-1;i>=0;i--)
{
result.push_back(count[i]); //因为逆置了,这里再反回去
}
return result;
}
void BST_Insert(BSTNode*&root,BSTNode* insert,int &count_small) //count_small表示比插入节点小的元素个数,这里的root要传引用,里面要修改他
{
if(root==NULL)
{
root =insert; return;
}
//如果节点不为空,则按照二叉查找树的规则插入树
if(insert->val <= root->val) //插入左子树
{
root->cnt ++; //有元素比当前节点小,则记录
BST_Insert(root->left,insert,count_small);
}
else
{
count_small += (root->cnt+1); //如果插入的元素大于当前节点,则比插入元素小的元素个数在当前节点个数基础上加1
BST_Insert(root->right,insert,count_small);
}
}
};