HashMap在多线程下访问下导致死循环问题
本文部分内容摘自http://www.cnblogs.com/RGogoing/p/5285361.html
HashMap的扩容方法resize方法的关键问题是transfer函数的调用过程..我们来看一下transfer的源码..
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) { //这里才是问题出现的关键..
while(null != e) {
Entry next = e.next; //寻找到下一个节点..
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity); //重新获取hashcode
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
} transfer函数其实是在并发情况下导致死循环的因素..因为这里涉及到了指针的移动的过程..transfer的源码一开始我并有完全的看懂,主要还是newTable[i]=e的这个过程有点让人难理解..其实这个过程是一个非常简单的过程..我们来看一下下面这张图片..
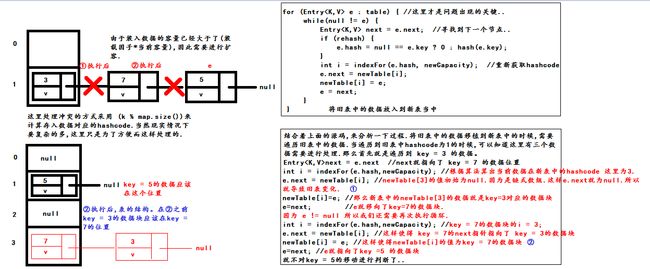
这是在单线程的正常情况下,当HashMap
这样在单线程的情况下就完成了扩容的操作.其中不会出现其他的问题..但是如果是在并发的情况下就不一样了.并发的情况出现问题会有很多种情况.这里我简单的说明俩种情况.我们来看图。

这张图说明了两种死循环的情况.第一种相对而严还是很容易理解的.第二种可能有点费劲..但是有一点我们需要记住,图中t1和t2拿到的是同一个内存单元对应的数据块.而不是t1拿到了一个独立的数据块,t2拿到了一个独立的数据块..这是不对的..之所以发生系循环的原因就是因为拿到的数据块是同一个内存单元对应的数据块.这点我们需要注意..正是因为在高并发的情况下线程的工作方式是不确定的,我们无法预知线程的工作情况.因此在高并发的情况下,我们不要使用多线程对HashMap
可能看起来很复杂,但是只要去思考,还是感觉蛮简单的,我这只是针对两个线程来分析了一下死循环的情况,当然发生死循环的问题不仅仅只是这两种方式,方式可能会有很多,我这里只是针对了两个类型进行了分析,目的是方便大家理解.发生死循环的方式绝不仅仅只是这两种情况.至于其他的情况,大家如果愿意去了解,可以自己再去研磨研磨其他的方式.按照这种思路分析,还是能研磨出来的.并且这还是两个线程,如果数据量非常大,线程的使用还比较多,那么就更容易发生死循环的现象.因此这就是导致HashMap