生成对抗网络GAN(二)基于Tensorflow2.0的二次元动漫头像生成
基于Tensorflow2.0的二次元动漫头像生成
1.生成预览

2.DCGAN框架及WGAN优化
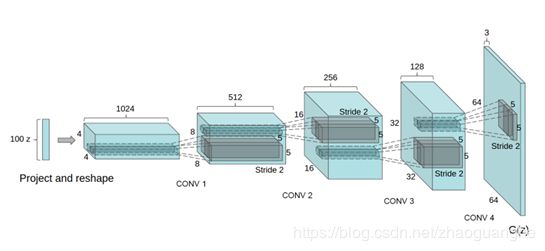
DCGAN,全称为Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks(http://arxiv.org/pdf/1511.06434),主要创新为将100维均匀分布的Z映射到小空间范围的卷积表示法中得到多个特征向量。通过一系列小数步长卷积four fractionally-strided (在最近的一些论文中,这些被错误地称为反卷积),将这个高维表示转换成一个64 x 64像素的图像。没有使用全连接层和池化层。除输出层使用Tanh函数外,生成器还使用ReLU激活函数(Nair & Hinton, 2010)。我们观察到,使用有界激活使模型能够更快地学习,以饱和和覆盖训练分布的颜色空间。在鉴别器中,我们发现漏整流激活(Maas et al., 2013) (Xu et al., 2015)工作良好,特别是对于高分辨率建模。这与最初使用maxout激活的GAN论文形成了对比(Goodfellow et al. 2013)。
WGAN,全称为Wasserstein Generative Adversarial Networks(https://arxiv.org/abs/1701.07875),主要创新为介绍了一种新的算法WGAN,它是传统GAN训练的一种替代。在这个新的模型中,证明了可以提高学习的稳定性,摆脱像模式崩溃这样的问题,并且提供了对调试和超参数搜索有用的有意义的学习曲线,供了大量的理论工作,强调了分布之间的深度联系。

WGAN介绍可参考(https://zhuanlan.zhihu.com/p/44169714)
3.代码
- 构建生成器G
def generator_model_64():
model = tf.keras.Sequential()
model.add(layers.Dense(1*1*100, use_bias=False, input_shape=(100,)))
model.add(layers.Reshape((1, 1, 100))) # [batch,100]
assert model.output_shape == (None, 1, 1, 100) # Note: None is the batch size
model.add(layers.ReLU())
model.add(layers.Conv2DTranspose(512, 4, 1, padding='valid', use_bias=False))
assert model.output_shape == (None, 4, 4, 512)
model.add(layers.BatchNormalization())
model.add(layers.ReLU())
model.add(layers.Conv2DTranspose(256, 4, 2, padding='same', use_bias=False))
assert model.output_shape == (None, 8, 8, 256)
model.add(layers.BatchNormalization())
model.add(layers.ReLU())
model.add(layers.Conv2DTranspose(128, 4, 2, padding='same', use_bias=False))
assert model.output_shape == (None, 16, 16, 128)
model.add(layers.BatchNormalization())
model.add(layers.ReLU())
model.add(layers.Conv2DTranspose(64, 4, 2, padding='same', use_bias=False))
assert model.output_shape == (None, 32, 32, 64)
model.add(layers.BatchNormalization())
model.add(layers.ReLU())
model.add(layers.Conv2DTranspose(3, 4, 2, padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 64, 64, 3)
return model
import matplotlib.pyplot as plt
generator = generator_model_64()
noise = tf.random.uniform([1,100],minval=-1,maxval=1,dtype=tf.float32)
plt.imshow(generated_image[0, :, :, :])- 构建判别器D
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, 4, 2, padding='valid', use_bias=False,input_shape=[32, 32, 3]))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
#model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, 4, 2, padding='valid',use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
#model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(256, 3, 1, padding='valid',use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
#model.add(layers.Dropout(0.3))
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print(decision)tf.Tensor([[-0.00048578]], shape=(1, 1), dtype=float32)- 构建损失函数
def gradient_penalty(discriminator, batch_x, fake_image):
batchsz = batch_x.shape[0] #[b, h, w, c]
t = tf.random.uniform([batchsz, 1, 1, 1])
t = tf.broadcast_to(t, batch_x.shape)
interplate = t * batch_x + (1-t) * fake_image
with tf.GradientTape() as tape:
tape.watch([interplate])
d_interplote_logits = discriminator(interplate)
grads = tape.gradient(d_interplote_logits, interplate)
# grads:[b, h, w, c] => [b, -1]
grads = tf.reshape(grads, [grads.shape[0], -1])
gp = tf.norm(grads, axis=1) #[b]
gp = tf.reduce_mean((gp-1.)**2)
return gp
def discriminator_loss(discriminator,fake_image,real_output, fake_output,batch_size):
gp = gradient_penalty(discriminator, batch_size, fake_image)
loss = tf.reduce_mean(fake_output) - tf.reduce_mean(real_output) + 5. * gp
return loss, gp
def generator_loss(fake_output):
return -tf.reduce_mean(fake_output)
generator_optimizer = tf.keras.optimizers.Adam(1e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4, beta_1=0.5)
BATCH_SIZE = 64
noise_dim =100
@tf.function
def train_step(images):
noise = tf.random.uniform([BATCH_SIZE, noise_dim],minval=-1,maxval=1,dtype=tf.float32)
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss,gp = discriminator_loss(discriminator,generated_images,real_output,fake_output,images)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
return gen_loss, disc_loss, gp
num_examples_to_generate = 16
seed = tf.random.uniform([num_examples_to_generate, noise_dim],minval=-1,maxval=1,dtype=tf.float32)- 加载数据
def generate_and_save_images(model, epoch, test_input):
# 注意 training` 设定为 False
# 因此,所有层都在推理模式下运行(batchnorm)
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, :])
plt.axis('off')
plt.savefig('./output/WGANM/image64_epoch_{:04d}.png'.format(epoch))
# 获得动漫头像数据集
import os
tfrecord_file = './train.tfrecords' # 下载地址:https://download.csdn.net/download/zhaoguanghe/12520615
raw_dataset = tf.data.TFRecordDataset(tfrecord_file) # 读取 TFRecord 文件
feature_description = { # 定义Feature结构,告诉解码器每个Feature的类型是什么
'image': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.int64),
}
def _parse_example(example_string): # 将 TFRecord 文件中的每一个序列化的 tf.train.Example 解码
feature_dict = tf.io.parse_single_example(example_string, feature_description)
feature_dict['image'] = tf.io.decode_jpeg(feature_dict['image']) # 解码JPEG图片
return feature_dict['image'], feature_dict['label']
dataset = raw_dataset.map(_parse_example)- Train
def train(dataset, epochs):
for epoch in range(epochs):
for i,image_batch in enumerate(dataset.shuffle(60000).batch(64)):
if i < 794: #弥补最后一批数据对齐
image = tf.cast(image_batch[0], tf.float32) / 127.5 - 1 # img的分布为[-1,1]
g,d,gp = train_step(image)
print("batch %d, gen_loss %f,disc_loss %f,gp %f" % (i, g.numpy(),d.numpy(),gp.numpy()))
else:
break
if (i+1) % 100 == 0:
# 保存模型
generator.save('./save/WGAN_cartoon_64_{:04d}.h5'.format(epoch))
# 生成图像
generate_and_save_images(generator,epoch+i, seed)
EPOCHS = 50
train(dataset, EPOCHS)- Test
import tensorflow as tf
import matplotlib.pyplot as plt
def generate_and_save_images(model, test_input):
# 注意 training` 设定为 False
# 因此,所有层都在推理模式下运行(batchnorm)
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4,4))
mengceng = tf.ones([64,64,3])
plt.imshow((predictions[0, :, :, :] +mengceng)/2.0)
plt.show()
test_input = tf.random.uniform([1, 100],minval=-1,maxval=1,dtype=tf.float32)
model = tf.keras.models.load_model('./save/wgan_cartoon.h5')
generate_and_save_images(model, test_input)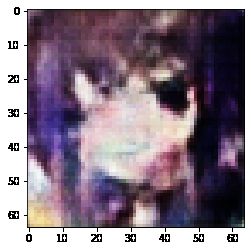
4.注意事项
- GPU训练更佳:1h,CPU训练速度:未实验
- tensorflow2版本
- train.tfrecords数据下载地址:https://download.csdn.net/download/zhaoguanghe/12520615
- 跳过训练直接使用wgan_cartoon.h5模型生成,模型下载地址:https://download.csdn.net/download/zhaoguanghe/12520620
了解更多,关注公众号:AI预见未来
