分布式SQL查询引擎技术选型presto及部署文档
分布式SQL查询引擎技术选型presto及部署文档
简介
Presto是一个facebook开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。
- Presto是Facebook开发的数据查询引擎,可对250PB以上的数据进行快速地交互式分析。
- 该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Facebook 雇员中使用,运行超过 30000 个查询,每日数据在 1PB 级别。Facebook 称 Presto 的性能比Hive要好上 10 倍有多。2013年Facebook正式宣布开源 Presto。领先的互联网公司包括Airbnb和Dropbox都在使用Presto。
presto的架构由关系型数据库的架构演化而来。presto之所以能在各个内存计算型数据库中脱颖而出,在于以下几点:
- 清晰的架构,是一个能够独立运行的系统,不依赖于任何其他外部系统。例如调度,presto自身提供了对集群的监控,可以根据监控信息完成调度。
- 简单的数据结构,列式存储,逻辑行,大部分数据都可以轻易的转化成presto所需要的这种数据结构。
场景
Presto 支持 SQL 并提供了一个标准数据库的语法特性,但其不是一个通常意义上的关系数据库,他不是关系数据库,如 MySQL、PostgreSQL 或者 Oracle 的替代品。Presto 不是设计用来解决在线事物处理(OLTP);
Presto 是一个工具,被用来通过分布式查询来有效的查询大量的数据。Presto 是一个可选的工具,可以用来查询 HDFS,通过使用 MapReduce 的作业的流水线,例如 hive,pig,但是又不限于查询 HDFS 数据,它还能查询其他的不同数据源的数据,包括关系数据库以及其他的数据源,比如 cassandra;
Presto 被设计为处理数据仓库和分析:分析数据,聚合大量的数据并产生报表,这些场景通常被定义为 OLAP。
优势
-
多数据源,支持SQL,自定义扩展Connector
-
混合计算(同一种数据源的不同库 or表;将多个数据源的数据进行合并)
-
低延迟,高并发,纯内存计算引擎,高性能
Presto是一个低延迟高并发的内存计算引擎,相比Hive,执行效率要高很多。
举例:
SELECT id,
name,
source_type,
created_at
FROM dw_dwb.dwb_user_day
WHERE dt='2018-06-03'
AND created_at>’2018-05-20’;
上述SQL在Presto运行时间不到1秒钟,在Hive里要几十秒钟。
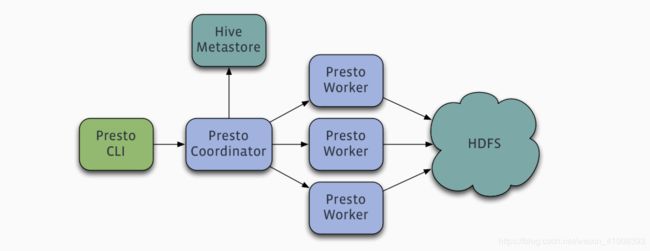
架构
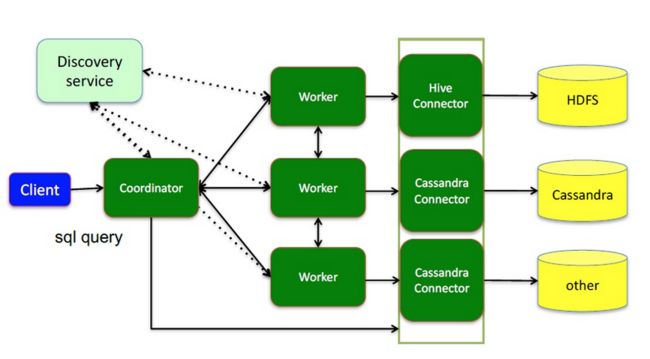
presto提供插件化的connector来支持外部数据查询,原生支持hive、cassandra、elasticsearch、kafka、kudu、mongodb、mysql、redis等众多外部数据源;
- coordinator(master):负责meta管理,worker管理;接收查询请求,解析SQL生成执行计划
- worker:执行任务的节点,负责计算和读写
- connector:连接器(Hadoop相关组件的连接器,RDBMS连接器)
- discovery service:内嵌在coordinator节点中,也可以单独部署,用于节点心跳;worker节点启动后向discovery service服务注册,coordinator通过discovery service获取注册的worker节点
执行过程

- coordinator接到SQL后,通过SQL语法解析器把SQL语法解析变成一个抽象的语法树AST(描述最原始的用户需求),只是进行语法解析如果有错误此环节暴露
- 语法符合SQL语法,会经过一个逻辑查询计划器组件,通过connector 查询metadata中schema 列名 列类型等,将之与抽象语法数对应起来,生成一个物理的语法树节点 如果有类型错误会在此步报错
- 如果通过,会得到一个逻辑的查询计划,将其分发到分布式的逻辑计划器里,进行分布式解析,最后转化为一个个task
- 在每个task里面,会将位置信息解析出来,交给执行的plan,由plan将task分给worker执行
数据模型
Presto使用Catalog、Schema和Table这3层结构来管理数据。
- Catalog:就是数据源。Hive是数据源,Mysql也是数据源,Hive 和Mysql都是数据源类型,可以连接多个Hive和多个Mysql,每个连接都有一个名字。一个Catalog可以包含多个Schema,大家可以通过show catalogs 命令看到Presto连接的所有数据源。
- Schema:相当于一个数据库实例,一个Schema包含多张数据表。show schemas from 'catalog_name’可列出catalog_name下的所有schema。
- Table:数据表,与一般意义上的数据库表相同。show tables from 'catalog_name.schema_name’可查看’catalog_name.schema_name’下的所有表。
在Presto中定位一张表,一般是catalog为根,例如:一张表的全称为 hive.test_data.test,标识 hive(catalog)下的 test_data(schema)中test表。
可以简理解为:数据源的大类.数据库.数据表。
支持的数据源类型

单机版 presto部署
安装
http://10.139.8.12
路径 /opt/software/presto
server: presto-server-0.233.1.tar.gz
clicent: presto-cli-0.219-executable.jar
1.server解压
tar -zxvf /opt/software/presto/presto-server-0.233.1.tar.gz -C /opt/module/presto-0.233.1/
2.文件 cp
cp /opt/software/presto/presto-cli-0.223.1.jar /opt/module/presto-0.233.1/presto-server-0.233.1/bin
cp /opt/software/presto/presto-cli-0.219-executable.jar /opt/module/presto-0.233.1/presto-server-0.233.1/bin
3.重命名
mv /opt/module/presto-0.233.1/presto-server-0.233.1/bin/presto-cli-0.219-executable.jar /opt/module/presto-0.233.1/presto-server-0.233.1/bin/presto-cli
4.增加 presto 的执行权限
chmod +x /opt/module/presto-0.233.1/presto-server-0.233.1/bin/presto-cli
配置 Presto
- 节点属性(node.properties):每个节点的环境配置信息
- JVM 配置(jvm.config):JVM的命令行选项
- 配置属性(config.properties):Presto server的配置信息
- 日志属性(log.properties):日志的配置信息
- Catalog属性(catalog目录):数据源的配置信息
- 配置数据目录
#最好安装在 presto server 安装目录外
mkdir /opt/module/presto-0.233.1/data - 创建配置文件
-
在 presto server 安装目录 /opt/module/presto-0.233.1/presto-server-0.233.1 创建 etc 文件夹
mkdir /opt/module/presto-0.233.1/presto-server-0.233.1/etc -
在 /opt/module/presto-0.233.1/presto-server-0.233.1/etc 下创建 config.properties,jvm.properties,node.properties,log.properties 文件
vim config.properties
config.properties内容
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8888
query.max-memory=1GB
query.max-memory-per-node=512MB
query.max-total-memory-per-node=512MB
discovery-server.enabled=true
discovery.uri=http://10.139.8.12:8888
部分配置信息解释
- “coordinator=true” // Presto 实例是否以 coordinator 对外提供服务。work节点需要填写false
- “node-scheduler.include-coordinator=true” // 是否允许在coordinator上调度节点只负责调度时node-scheduler.include-coordinator设置为false,调度节点也作为worker时node-scheduler.include-coordinator设置为true
- “http-server.http.port” // 服务端口号
- “task.max-memory=1GB” // 每一个任务(对应一个节点上的一个查询计划)所能使用的最大内存
- “discovery-server.enabled=true” // Presto 通过Discovery 服务来找到集群中所有的节点,每一个Presto实例都会在启动的时候将自己注册到discovery服务; 注意:worker 节点不需要配 discovery-server.enabled
- “discovery-server.enabled” // 是否使用 Discovery service 发现集群中的每一个节点。
- “discovery.uri=http://10.139.8.12:8888” // Discovery server的URI。由于启用了Presto coordinator内嵌的Discovery 服务,因此这个uri就是Presto coordinator的uri
jvm.config内容
vim jvm.config (Presto集群coordinator和worker的JVM配置是一致的)
-server
-Xmx2G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
node.properties内容
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/opt/module/presto-0.233.1/data
log.properties内容(INFO、DEBUG)
com.facebook.presto=DEBUG
- 配置 connector
-
在 /opt/module/presto-0.233.1/presto-server-0.233.1/etc 创建 catalog 目录
mkdir /opt/module/presto-0.233.1/presto-server-0.233.1/etc/catalog -
在 catalog 目录下 创建 hive connector
vim hive.properties
connector.name=hive-hadoop2 #注意 connector.name 只能是 hive-hadoop2
hive.metastore.uri=thrift://hadoop101:9083
hive.config.resources=/etc/hadoop/core-site.xml,/etc/hadoop/hdfs-site.xml
- 在 catalog 目录下 创建 mysql connector
vim mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://hadoop101:3306
connection-user=root
connection-password=123456
- 在 catalog 目录下 创建 postgresql connector
vim postgresql.properties
connector.name=postgresql
connection-url=jdbc:postgresql://10.139.8.12:5432/quartz
connection-user=postgres
connection-password=idqc_pg@12!
- 在 catalog 目录下 创建 kafka connector
vim kafka.properties
connector.name=kafka
kafka.table-names=table1,table2
kafka.nodes=host1:port,host2:port
启动 presto
服务路径 /opt/module/presto-0.233.1/presto-server-0.233.1/bin/
-
以后台方式启动
launcher start -
以调试方式启动,输出并打印日志(日志在 数据目录 /opt/module/presto-0.233.1/data/var/log)
/opt/module/presto-0.233.1/presto-server-0.233.1/bin/launcher --verbose run -
帮助语法
launcher --help -
停止服务
launcher --stop
前端页面地址
- http://10.139.8.12:8888/ui/

进入presto终端界面
以连接12postgresql数据源为例,./bin/presto-cli --server http://10.139.8.12:8888 --catalog postgresql
各参数的含义:
- server 是presto服务地址;
- catalog 是默认使用哪个数据源,后面也可以切换,如果想连接mysql数据源,使用mysql数据源名称即可;
- user 是用户名;
- source 是代表查询来源,source设置格式为key=value形式(英文分号分割); 例如个人从command line查询应设置为pf=adhoc;client=cli。
进入终端后:
查看连接的数据源: show catalogs;
查看数据库实例:show schemas;



常用链接
Presto使用手册:https://prestodb.io/docs/current/
阿里云开源组件 presto 介绍:https://help.aliyun.com/document_detail/64035.html?spm=a2c4g.11186623.6.819.7433ab6aQBJ8F5
presto 官方地址(英文) https://prestodb.io/
presto 京东官方地址 http://prestodb.jd.com/
Presto 在有赞的实践之路 https://cloud.tencent.com/developer/news/606849