yolov3-tiny 完整训练自己的数据集步骤(包含数据准备、模型训练和测试、计算mAP和recall)
最近项目需要要进行yolov3-tiny训练自己的数据,参考了一些网上的方法和自己以前做faster-rcnn和tensoflow yolov3的经验,总结了自己步骤,以供学习,本文基于VOC格式训练。本文前提是已经编译过opencv源码,安装好cuda和cudnn等,我的博客中有编译和安装参考。
Darknet github地址:https://github.com/pjreddie/darknet
本文结构
- 1、源码准备和编译
- 2、准备自己的数据
- (1)建立VOC数据格式
- (2)图片打标签、xml文件和图片重新命名
- (3)得到trainval、train、val、test数据集(名称)
- (4)得到训练、测试、验证集合(路径)和labels文件
- (5)修改cfg/voc.data
- (6)修改cfg/yolov3-tiny.cfg
- (7)修改data/voc.names
- 3、训练模型
- 4、模型测试
- (1)单张图片测试
- (2)批量图片测试
- 5、mAP和recall计算
- (1)为测试图片增加置信度
- (2)计算mAP
- (3)计算recall
- 参考链接
1、源码准备和编译
下载darknet源码,修改Makefile,将opencv、cuda和cudnn的值均改为1
git clone https://github.com/pjreddie/darknet
cd darknet
修改Makefile的前几行如下:
GPU=1
CUDNN=1
OPENCV=1
编译darknet:
make
至此,已经可以利用darknet检测,下载yolov3-tiny的预训练模型可以进行测试
wget https://pjreddie.com/media/files/yolov3-tiny.weights
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
得到的结果如下:

2、准备自己的数据
(1)建立VOC数据格式
为了最小除程度减少代码的改写,在darknet主目录建立文件下如下:
---VOCdevkit
---VOC2007
---Annotations
---ImageSets
---Main
---JPEGImages
其中Annotations存放xml文件,JPEGImages存放对应的图片文件,此外ImageSets中Main函数是为了方便后续步骤中得到训练和测试图片的索引号
(2)图片打标签、xml文件和图片重新命名
(本步骤可不做,重命名为了整洁)
打标签使用LabelImage打标的,其github地址为:https://github.com/tzutalin/labelImg,可以设置自动保存和高级模式,不用手动点击才画框,并且自动保存(打标完成后,一定要检查一篇,我自己做模型训练,有一类目标的AP值怎么调参数cesti结果都比较低,搞了两天,最后发现有测试数据中有100多张此类的标签没有打标,造成准确率低)。重命名的方法是按照自己的命名规则得到,参考我另一篇博客:将训练数据的图片和xml文件重新命名(以jpg格式图片为例,其他格式需要简单修改代码),重命名后得到的xml文件如下:
(3)得到trainval、train、val、test数据集(名称)
将命名好的图片和文件放到/VOCdevkit/VOC2007文件夹下的对应位置,并利用代码提取每个图片的索引号,提取代码位于VOC2007文件下,运行如下代码即可得到:
import os
import random
trainval_percent = 0.9 #可以自己修改
train_percent = 0.9 #可以自己修改
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
上述代码共得到四个数据集trainval、train、test、val,关系(数量)如下:
全部数据 = test + trainval
trainval = train + val
(4)得到训练、测试、验证集合(路径)和labels文件
利用/script/中的voc_label.py生成训练和测试的文件路径,需要修改自己的训练类别(这里以3类为例),这里我只用了一个文件,故代码还去掉了与2012数据集相关的代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["box", "pen", "laptop"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt")
在darknet主目录可以得到:2007_test.txt、2007_train.txt、2007_val.txt、train.txt、 train.all.txt,我们暂时先用到 train.txt和 2007_test.txt,主要是图片的存放路径,txt内容如下:

在/VOCdevkit/VOC2007 中还生成了一个labels文件夹,主要记录每张图片的打标签的bouding box位置,labels文件如下:

(5)修改cfg/voc.data
classes= 3 #类别数改为自己的
train = /home/yasin/darknet/train.txt
valid = /home/yasin/darknet/2007_test.txt
names = data/voc.names
backup = backup
(6)修改cfg/yolov3-tiny.cfg
将如下的Training参数打开,关闭Testing参数
[net]
#Testing
#batch=1
#subdivisions=1
#Training
batch=64
subdivisions=16
找到如下位置(以yolo为关键字),修改filters和classes,整个文本共有2个filters和2个classes需要修改
[convolutional]
size=1
stride=1
pad=1
filters=24 #### 改为3*(classes +5)
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319 ####这个最好也要根据聚类结果修改(见下)
classes=3 #### 改为自己的数目
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
此外,anchors可以尝试根据自己的打标数据修改,可能会达到相比原anchor尺寸 更好的效果(注意是“可能”),因为默认的anchor不一定适合自己的数据,anchor尺寸聚类方法参见:YOLO v3 中关于 anchor 的 k-means 聚类代码
(7)修改data/voc.names
修改为自己的类别
box
pen
laptop
3、训练模型
./darknet partial ./cfg/yolov3-tiny.cfg ./yolov3-tiny.weights ./yolov3-tiny.conv.15 15
sudo ./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.15
可能问题:CUDA Error: out of memory darknet: ./src/cuda.c:36: check_error: Assertio `0’ failed.
解决方法:需要将yolov3-tiny.cfg中的由subdivisions改大。
subdivision:这个参数很有意思的,它会让你的每一个batch不是一下子都丢到网络里。而是分成subdivision对应数字的份数,一份一份的跑完后,在一起打包算作完成一次iteration。这样会降低对显存的占用情况。如果设置这个参数为1的话就是一次性把所有batch的图片都丢到网络里,如果为2的话就是一次丢一半。(windows下训练yolo时出现CUDA Error: out of memory问题的解决:https://blog.csdn.net/qq_33485434/article/details/80432054)
训练过程中的参数含义如下(https://blog.csdn.net/lilai619/article/details/79695109):
Avg IOU: 当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class: 标注物体的分类准确率,越大越好,期望数值为1;
obj: 越大越好,期望数值为1;
No obj: 越小越好;
.5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R: 以IOU=0.75为阈值时候的recall;
count: 正样本数目。
4、模型测试
训练得到的模型文件位于/backup文件中,源码中(examples/detector.c)当迭代小于1000时每隔100次保存一次模型,当大于1000时每10000次迭代保存一次模型,可以自行修改保存规则。
(1)单张图片测试
首先将.cfg文件修改为测试模式(打开Testing的注解,关闭Training的注解),再运行如下命令即可:
./darknet detector test cfg/voc.data cfg/yolov3-tiny.cfg backup/yolov3-tiny_10000.weights VOCdevkit/VOC2007/JPEGImages/000022.jpg
测试结果如下:

(2)批量图片测试
需要修改example/detector.c中的部分内容,然后在主目录执行:
make clean
make
./darknet detector test cfg/voc.data cfg/yolov3-tiny.cfg backup/yolov3-tiny_10000.weights
输入自己的测试文本(图片路径集合)即可,例如: /home/yasin/darknet/2007_test.txt。
修改example/detector.c中,更改如下:
#include "darknet.h"
#include 另外修改test_detector()函数如下:
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, char *outfile, int fullscreen)
{
list *options = read_data_cfg(datacfg);
char *name_list = option_find_str(options, "names", "data/names.list");
char **names = get_labels(name_list);
image **alphabet = load_alphabet();
network *net = load_network(cfgfile, weightfile, 0);
set_batch_network(net, 1);
srand(2222222);
double time;
char buff[256];
char *input = buff;
float nms=.45;
int i=0;
while(1){
if(filename){
strncpy(input, filename, 256);
image im = load_image_color(input,0,0);
image sized = letterbox_image(im, net->w, net->h);
//image sized = resize_image(im, net->w, net->h);
//image sized2 = resize_max(im, net->w);
//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);
//resize_network(net, sized.w, sized.h);
layer l = net->layers[net->n-1];
float *X = sized.data;
time=what_time_is_it_now();
network_predict(net, X);
printf("%s: Predicted in %f seconds.\n", input, what_time_is_it_now()-time);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);
//printf("%d\n", nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);
free_detections(dets, nboxes);
if(outfile)
{
save_image(im, outfile);
}
else{
save_image(im, "predictions");
#ifdef OPENCV
/*cvNamedWindow("predictions", CV_WINDOW_NORMAL);
if(fullscreen){
cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN);
}
show_image(im, "predictions");
cvWaitKey(0);
cvDestroyAllWindows();*/
#endif
}
free_image(im);
free_image(sized);
if (filename) break;
}
else {
printf("Enter Image Path: ");
fflush(stdout);
input = fgets(input, 256, stdin);
if(!input) return;
strtok(input, "\n");
list *plist = get_paths(input);
char **paths = (char **)list_to_array(plist);
printf("Start Testing!\n");
int m = plist->size;
if(access("/home/yasin/darknet/data/out",0)==-1)//"/home/fqlovetb/darknet/data"修改成自己的路径
{
if (mkdir("/home/yasin/darknet/data/out",0777))//"/home/fqlovetb/darknet/data"修改成自己的路径
{
printf("creat file bag failed!!!");
}
}
for(i = 0; i < m; ++i){
char *path = paths[i];
image im = load_image_color(path,0,0);
image sized = letterbox_image(im, net->w, net->h);
//image sized = resize_image(im, net->w, net->h);
//image sized2 = resize_max(im, net->w);
//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);
//resize_network(net, sized.w, sized.h);
layer l = net->layers[net->n-1];
float *X = sized.data;
time=what_time_is_it_now();
network_predict(net, X);
printf("Try Very Hard:");
printf("%s: Predicted in %f seconds.\n", path, what_time_is_it_now()-time);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);
//printf("%d\n", nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);
free_detections(dets, nboxes);
if(outfile){
save_image(im, outfile);
}
else{
char b[2048];
sprintf(b,"/home/yasin/darknet/data/out/%s",GetFilename(path));//"/home/fqlovetb/darknet/data"修改成自己的路径
save_image(im, b);
printf("save %s successfully!\n",GetFilename(path));
#ifdef OPENCV
/*cvNamedWindow("predictions", CV_WINDOW_NORMAL);
if(fullscreen){
cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN);
}
show_image(im, "predictions");
cvWaitKey(0);
cvDestroyAllWindows();*/
#endif
}
free_image(im);
free_image(sized);
if (filename) break;
}
}
}
}
5、mAP和recall计算
此外测试可能用到以下三点,一是为图片增加置信度,二是计算mAP值,三是计算recall值:
(1)为测试图片增加置信度
将/src/image.c中的draw_detections()函数中第一段的for 循环改为如下:
for(i = 0; i < num; ++i){
char labelstr[4096] = {0};
int class = -1;
char possible[10];//存放检测的置信值
for(j = 0; j < classes; ++j){
sprintf(possible,":%.2f",dets[i].prob[j]);//置信值截取小数点后两位赋给possible
if (dets[i].prob[j] > thresh){
if (class < 0) {
strcat(labelstr, names[j]);
strcat(labelstr, possible);//标签中加入置信值
class = j;
} else {
strcat(labelstr, ", ");
strcat(labelstr, names[j]);
strcat(labelstr, possible);//标签中加入置信值
}
printf("%s: %.0f%%\n", names[j], dets[i].prob[j]*100);
}
}
增加后测试如下:

(2)计算mAP
(1)批处理测试图片输出检测结果文本
./darknet detector valid cfg/voc.data cfg/yolov3-tiny.cfg backup/yolov3-tiny_10000.weights -out detect_result
代码处理的是cfg/voc.data中valid路径的图片,给出图片的名称、置信度、预测的边界框信息,每个类对应着一个txt,例如 detect_resultnotebook.txt,位于darknet/results 文件夹中。
(2)使用py-faster-rcnn下的voc_eval.py计算mAP
在darknet根目录新建voc_eval.py文件,内容如下(来源为https://github.com/rbgirshick/py-faster-rcnn/tree/master/lib/datasets:py-faster-rcnn/lib/datasets/voc_eval.py,由于我用的是python3,需要对pickle和print相关内容修改,python2版本则不用):
# --------------------------------------------------------
# Fast/er R-CNN
# Licensed under The MIT License [see LICENSE for details]
# Written by Bharath Hariharan
# --------------------------------------------------------
import xml.etree.ElementTree as ET
import os
import pickle
import numpy as np
def parse_rec(filename):
""" Parse a PASCAL VOC xml file """
tree = ET.parse(filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
obj_struct['pose'] = obj.find('pose').text
obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
def voc_ap(rec, prec, use_07_metric=False):
""" ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.5,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: Path to detections
detpath.format(classname) should produce the detection results file.
annopath: Path to annotations
annopath.format(imagename) should be the xml annotations file.
imagesetfile: Text file containing the list of images, one image per line.
classname: Category name (duh)
cachedir: Directory for caching the annotations
[ovthresh]: Overlap threshold (default = 0.5)
[use_07_metric]: Whether to use VOC07's 11 point AP computation
(default False)
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name
# cachedir caches the annotations in a pickle file
# first load gt
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
cachefile = os.path.join(cachedir, 'annots.pkl')
# read list of images
with open(imagesetfile, 'r') as f:
lines = f.readlines()
imagenames = [x.strip() for x in lines]
if not os.path.isfile(cachefile):
# load annots
recs = {}
for i, imagename in enumerate(imagenames):
recs[imagename] = parse_rec(annopath.format(imagename))
if i % 100 == 0:
print ('Reading annotation for {:d}/{:d}'.format(
i + 1, len(imagenames)))
# save
print ('Saving cached annotations to {:s}'.format(cachefile))
with open(cachefile, 'wb') as f:
pickle.dump(recs, f)
else:
# load
with open(cachefile, 'r') as f:
recs = pickle.load(f)
# extract gt objects for this class
class_recs = {}
npos = 0
for imagename in imagenames:
R = [obj for obj in recs[imagename] if obj['name'] == classname]
bbox = np.array([x['bbox'] for x in R])
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult)
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
splitlines = [x.strip().split(' ') for x in lines]
image_ids = [x[0] for x in splitlines]
confidence = np.array([float(x[1]) for x in splitlines])
BB = np.array([[float(z) for z in x[2:]] for x in splitlines])
# sort by confidence
sorted_ind = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
BB = BB[sorted_ind, :]
image_ids = [image_ids[x] for x in sorted_ind]
# go down dets and mark TPs and FPs
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
# compute precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap
新建compute_mAP.py(其中的路径要改为自己的路径)
from voc_eval import voc_eval
import os
if os.path.exists("annots.pkl"):
os.remove("annots.pkl")
print (voc_eval('/home/yasin/darknet_test/results/detect_result{}.txt', '/home/yasin/darknet/VOCdevkit/VOC2007/Annotations/{}.xml','/home/yasin/darknet/VOCdevkit/VOC2007/ImageSets/Main/test.txt', 'notebook','.'))
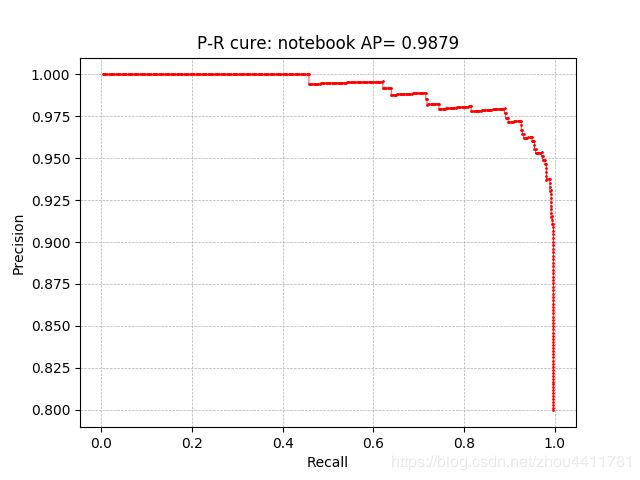
执行python compute_mAP.py,voc_eval.py中返回值的最后一个即AP值,所有类的均值就是mAP,此外还返回了单个类置信度排序下的precision和recall值,根据此可以画出单个类的P-R曲线。
(3)计算recall
修改examples/detector.c下的validate_detector_recall函数,替换list *plist = get_paths(“data/coco_val_5k.list”);为list *plist=get_paths("/home/yasin/darknet/2007_test.txt"),即自己的测试集文本。
此外:recall较低参考链接,因为作者修改了一个bug,不知道为什么没有传上去,我一开始算出来,召回率每次都是80%,改了以后才变高。
++total;
box t = {truth[j].x, truth[j].y, truth[j].w, truth[j].h};
float best_iou = 0;
//for(k = 0; k < l.w*l.h*l.n; ++k){ #这里计算有问题
for(k = 0; k < nboxes; ++k){
float iou = box_iou(dets[k].bbox, t);
if(dets[k].objectness > thresh && iou > best_iou){
best_iou = iou;
./darknet detector recall cfg/voc.data cfg/yolov3-tiny.cfg backup/yolov3-tiny_10000.weights
其中输出的参数含义如下(https://www.jianshu.com/p/7ae10c8f7d77/):
Number Correct Total Rps/Img IOU Recall
Number:表示处理到第几张图片。
Correct:表示正确的识别除了多少bbox。这个值算出来的步骤是这样的,丢进网络一张图片,网络会预测出很多bbox,每个bbox都有其置信概率,概率大于threshold的bbox与实际的bbox,也就是labels中txt的内容计算IOU,如果这个最大值大于预设的IOU的threshold,那么correct加一。
Total:表示实际有多少个bbox。
Rps/img:表示平均每个图片会预测出来多少个bbox。
IOU :这个是预测出的bbox和实际标注的bbox的交集 除以 他们的并集。显然,这个数值越大,说明预测的结果越好。
Recall:召回率, 意思是检测出物体的个数 除以 标注的所有物体个数。通过代码我们也能看出来就是Correct除以Total的值。
注:此处的recall值相当于测试图片中所有被正确识别的物体(不管属于哪个类)占总标注物体的比值,和第(2)小节中区别就是,第(2)小节为单类的recall值。
参考链接
- yolov3配置文件分析
- Darknet YOLO 训练问题集锦
- yolov3训练自己的数据集——第一次实操完整记录
- darknet - Tiny YOLOv3 test and training (测试 and 训练)
- Darknet YOLOv3-tiny ubuntu配置,训练自己数据集(行人检测)及调参总结
- yolov3批量测试并存在自己定义的路径(linux+c版本)
- YOLOV3 测试图像添加置信度与训练bmp图像格式
- YOLOv3使用笔记——计算mAP、recall
- YOLO-V3可视化训练过程中的参数,绘制loss、IOU、avg Recall等的曲线图