机器学习:基于决策树和朴素贝叶斯算法对Adult数据集分类
1、数据集介绍
机器学习算法需要作用于数据,数据的属性和特征决定了机器学习算法是否适用,同时,数据质量的好坏也直接决定算法表现的好坏。这篇博客选择在Adult数据集上进行实验。
Adult数据集
该数据从美国1994年人口普查数据库中抽取而来,因此也称作“人口普查收入”数据集,共包含48842条记录,年收入大于50k$的占比23.93%,年收入小于50k$的占比76.07%,数据集已经划分为训练数据32561条和测试数据16281条。该数据集类变量为年收入是否超过50k$,属性变量包括年龄、工种、学历、职业等14类重要信息,其中有8类属于类别离散型变量,另外6类属于数值连续型变量。该数据集是一个分类数据集,用来预测年收入是否超过50k$。

14个属性变量具体介绍如下:

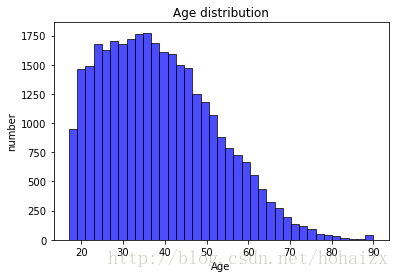
训练集中属性age的最小值为17,最大值为90,平均年龄为38.6,具体分布直方图如下:
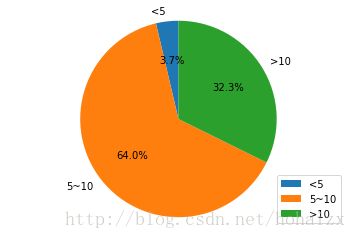
训练集中属性education-num最小值为1,最大值为16,平均值为10,将其划分为“<5”、“5-10”和“>10”三个区间,分布饼图如下:
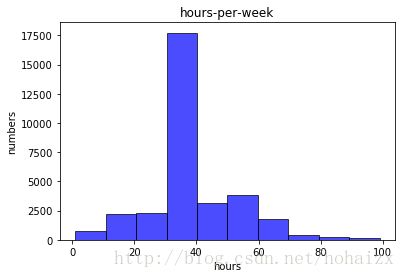
训练集中属性hours-per-week取值虽然分布在1到99之间,但基本集中在40附近,具体分布直方图如下:
8个离散型属性变量中,workclass有“Private”等8个取值;
education有“Bachelors”等16个取值;
marital-status有“Married-civ-spouse”等7个取值;
occupation有“Tech-support”等14个取值;
relationship有“Wife”等6个取值;
race有“White”等5个取值;
sex取“Female”和“Male”;
native-country有“United-States”等41个取值。
因为adult数据集是一个分类数据集,并且属性变量的取值既有连续型又有离散型,因此本实验决定采用决策树和贝叶斯算法。决策树算法计算比较简单,解释性强,比较适合处理有缺失属性值的数据样本。贝叶斯算法源于古典数学理论,有着坚实的数学基础,分类效率稳定,同样算法比较简单,对缺失数据不太敏感。
2、实验方案
2.1、决策树算法
决策树算法和人类在进行决策时的处理机制类似,依据对一系列属性取值的判定得出最终决策。决策树是一棵树结构,其每个非叶子节点表示一个特征属性上的测试,每个分支表示这个特征属性在某个值域上的输出,而每个叶子节点对应于最终决策结果。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点对应的类别作为决策结果。
决策树学习的目的是产生一棵泛化性能强,即处理未见示例能力强的决策树。其基本流程遵循“分而治之”的策略,算法伪代码如下图所示:
输入:训练集D={(x_1,y_1),(x_2,y_2),⋯,(x_m,y_m)};
属性集A={a_1,a_2,⋯,a_d}.
过程:函数TreeGenerate(D,A)
1: 生成节点node
2: if D中样本全属于同一类别C then
3: 将node标记为C类叶节点;return
4: end if
5: if A=∅ or D中样本在A上取值相同 then
6: 将node标记为叶节点,其类别标记为D中样本数最多的类;return
7: end if
8: 从A中选择最优 划分属性a_*;
9: for a_*的每一个取值a_*^v do
10: 为node生成一个分支;令D_v表示D中在a_*上取值为a_*^v的样本子集;
11: if D_v=∅ then
12: 将分支节点标记为叶节点,其类别标记为D中样本最多的类;return
13: else
14: 以TreeGenerate(D_v,A\{a_*})为分支节点
15: end if
16: end for
输出:以node为根节点的一棵决策树
上述算法最关键的是第8行,即如何选择最优划分,选择的标准是什么。一般而言,随着划分的不断进行,决策树每个分支包含的样本会越来越属于同一类,即节点的“纯度”越来越高。但是为了得到一棵泛化性能强的决策树,根据“奥卡姆剃刀”原则:越是小型的决策树越优于大型的决策树,我们希望最终得到的决策树规模越小越好。因此我们选择划分后能够将样本“纯度提升”最大的那个属性作为最优划分。
为了度量样本“纯度提升”,我们需要引入一些概念。
2.1.1、信息熵
信息熵是信息论之父香浓从热力学概念“熵”中借鉴过来的,在热力学中熵表示分子的混乱程度,香浓用信息熵来描述信息的不确定度。信息熵的计算公式定义如下:

其中,pkpk代表样本集合D中第k类样本所占的比例,|y|为样本集合D的类别数目。Ent(D)越小,则信息的不确定性越小,信息的纯度越高。
2.1.2、信息增益
当我们选择一个属性进行划分后,信息的纯度将增加,信息的不确定性将随之减少。我们用信息增益来度量样本纯度的提升。假设离散属性a有V个可能的取值{a1,a2,⋯,aV}{a1,a2,⋯,aV},若使用a来对样本集D进行划分,则会产生V个分支节点,其中第v个分支节点包含了D中所有在属性a上取值为avav的样本,记为DvDv。因此我们可以将信息增益的公式记为如下:
因此,信息增益越大,则意味着使用属性a进行划分获得的“纯度提升”越大。著名的ID3决策树算法就是以信息增益为准则来选择划分属性。
2.1.3、连续值处理
由于连续属性的可取值数目不再有限,因此,不能直接根据连续属性的可取值来对节点进行划分。此时,需要对连续属性离散化,最简单的策略是采用二分法将连续属性值一分为二。在本实验中,通过对连续数据的取值观察,最终确定将age、education-num、captional-gain、captional-loss和hours-per-week划分为10、8、12、12、12个区间。
2.2、朴素贝叶斯算法
贝叶斯分类是一类分类算法的总称,这类算法以贝叶斯定理为基础,故统称贝叶斯分类。贝叶斯分类与常用的决策树、支持向量机(SVM)等判别型分类器不同,贝叶斯分类属于生成型模型,生成型模型最大的特点是先对联合概率分布p(x,c)p(x,c)建模,然后再由此获得 p(c|x)p(c|x)。根据条件概率公式有:![]()
基于贝叶斯定理,p(c|x)可写为:

其中,p(c)p(c)是类先验概率; p(x|c)p(x|c)是样本x相对于类标记c的类条件概率;p(x)p(x)是用于归一化的“证据”因子。对于给定的x,“证据”因子p(x)p(x)与类标记无关,因此估计p(c│x)p(c│x)的问题转化为如何基于训练数集D来估计类先验概率p(c)和类条件概率p(x|c)p(x|c)。
类先验概率p(c)p(c)表达了样本空间中各类样本所占的比例,根据大数定律,当训练集包含充足的独立同分布样本时,p(c)p(c)可以通过各类样本出现的频率进行估计。但是对类条件概率 p(x|c)p(x|c)来说,由于它涉及关于x的所有属性的联合概率,直接根据样本出现的频率来估计将会遇到严重困难。即使是每个属性取值均为二值,d个属性构成的样本空间也将达到2d,这个数字远远超过了训练数据样本数m。一方面,依靠计算机扫面统计将变得几乎不太可能;另一方面,由于数据稀疏性,很多样本取值在训练集中根本没有出现,直接使用频率估计概率显然不可行。常用的策略是先假定类条件概率服从某种形式的概率分布,再基于训练样本对概率分布的参数进行估计。
朴素贝叶斯分类是贝叶斯分类中最简单,也是最常见的一种分类方法,广泛用于新闻分类、病人分类等任务中。
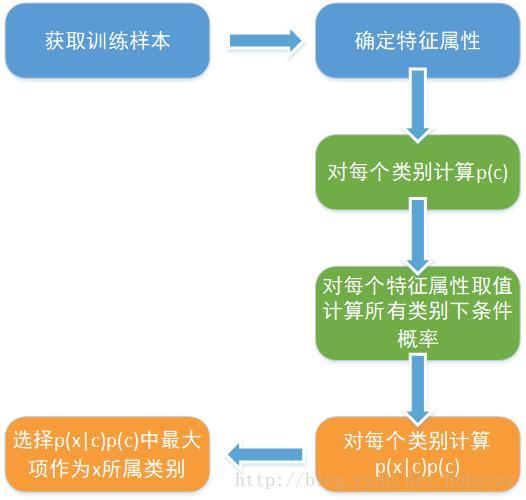
朴素贝叶斯分类的流程如下图所示:
2.2.1、连续值处理
同样对于取值为无限的连续型属性变量,在利用朴素贝叶斯算法进行分类时,也需要进行连续值平滑处理。在本实验中,将age、captional-gain、captional-loss和hours-per-week划分为10、3、3、20个区间。因为education-num和education表达的是相同的意思,所以将其去除。另外,在本实验中,也对部分离散型属性进行了重新归类,将相似的取值归为一类,既减少了属性取值数,也提高了模型泛化能力。
2.2.2、平滑处理
因为训练样本的数量有限,在训练数据集中,可能出现某个属性的某个取值为零的情况,那么这个条件概率值为0,导致整个后验概率值为0,为了避免其他属性携带的信息被训练集中未出现的属性值“抹去”,在进行概率估计时通常要加上平滑项,常用拉普拉斯平滑,这时条件概率公式可以修正为:
其中NiNi第i个属性可能的取值数。
3、实践代码
trees.py部分代码如下:
# -*- coding: utf-8 -*-
from math import log
import operator
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
#change to discrete values
return dataSet, labels
def calcShannonEnt(dataSet): #计算给定数据集的香农熵
numEntries = len(dataSet) #实例总数
labelCounts = {}
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
def splitDataSet(dataSet, axis, value): #划分数据集
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #chop out axis used for splitting 降维,除去所选的划分属性的一维
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet): #选择最好的数据集划分方式
numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
baseEntropy = calcShannonEnt(dataSet) #原始香农熵
bestInfoGain = 0.0; bestFeature = 0
for i in range(numFeatures): #iterate over all the features
featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
uniqueVals = set(featList) #get a set of unique values 从列表中创建一个集合(包含不同的元素)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy计算信息增益
if (infoGain >= bestInfoGain): #compare this to the best gain so far
bestInfoGain = infoGain #if better than current best, set to best
bestFeature = i
return bestFeature #returns an integer
def majorityCnt(classList): #多数表决法
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels): #创建决策树
labelnum = {'age':4,'workclass':7,'education':3,'marital-status':2,'occupation':3,'relationship':3,'race':2,'sex':2,'capital-gain':2,'capital-loss':2,'hours-per-week':3,'native-country':2}
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#stop splitting when all of the classes are equal
if len(dataSet[0]) == 1: #stop splitting when there are no more features in dataSet
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) #选择最好的划分属性的index
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
if len(uniqueVals) == 1:
return majorityCnt(classList)
elif len(uniqueVals) < labelnum[bestFeatLabel]:
myTree[bestFeatLabel]["default"] = majorityCnt(classList)
for value in uniqueVals:
subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
def classify(inputTree,featLabels,testVec): #使用决策树的分类函数
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
key = testVec[featIndex]
if key not in secondDict:
classLabel = secondDict["default"]
return classLabel
valueOfFeat = secondDict[key]
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else: classLabel = valueOfFeat
return classLabel
def storeTree(inputTree,filename): #保存决策树
import pickle
fw = open(filename,'w')
pickle.dump(inputTree,fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)
treePlotter.py部分代码如下:
# -*- coding: utf-8 -*-
'''
Created on Oct 14, 2010
@author: Peter Harrington
'''
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle="sawtooth", fc="0.8") #文本框的格式,决策点
leafNode = dict(boxstyle="round4", fc="0.8") #文本框的格式,叶子节点
arrow_args = dict(arrowstyle="<-") #箭头的格式
def getNumLeafs(myTree): #获取叶子结点的数目
numLeafs = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
def getTreeDepth(myTree): #获取树的深度
maxDepth = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType): #文字,坐标,父结点坐标,结点类型
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args )
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
depth = getTreeDepth(myTree)
firstStr = myTree.keys()[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#if you do get a dictonary you know it's a tree, and the first element will be another dict
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
#createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.show()
#def createPlot():
# fig = plt.figure(1, facecolor='white')
# fig.clf()
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
# plotNode('a decision node', (0.5, 0.1), (0.1, 0.5), decisionNode)
# plotNode('a leaf node', (0.8, 0.1), (0.3, 0.8), leafNode)
# plt.show()
def retrieveTree(i): #预先存储树信息
listOfTrees =[{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
]
return listOfTrees[i]
#createPlot(thisTree)项目运行代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 13 10:27:08 2017
@author: ChenYing
"""
import trees
import treePlotter
import csv
from sklearn import tree
import numpy as np
import matplotlib.pyplot as plt
def translate(filename):
age = {'0-25':0,'25-50':1,'50-75':2,'75-100':3}
csvfile = file(filename, 'rb')
reader = csv.reader(csvfile)
data = []
for line in reader:
data.append(line)
csvfile.close()
new_data = []
mark = 0
for dataline in data:
x = [0,0,0,0,0,0,0,0,0,0,0,0,0]
if mark ==0:
new_data.append(dataline)
mark += 1
else:
agenum = int(dataline[0])
if agenum>=0 and agenum<25:
x[0] = age['0-25']
elif agenum>=25 and agenum<50:
x[0] = age['25-50']
elif agenum>=50 and agenum<75:
x[0] = age['50-75']
elif agenum>=75:
x[0] = age['75-100']
x[1] = dataline[1]
x[2] = dataline[2]
x[3] = dataline[3]
x[4] = dataline[4]
x[5] = dataline[5]
x[6] = dataline[6]
x[7] = dataline[7]
gain = int(dataline[8])
if gain>0:
x[8] = '>0'
else:
x[8] = '=0'
loss = int(dataline[9])
if loss>0:
x[9] = '>0'
else:
x[9] = '=0'
hour = int(dataline[10])
if hour == 40:
x[10] = '=40'
elif hour > 40:
x[10] = '>40'
elif hour < 40:
x[10] = '<40'
if dataline[11] == 'United-States' :
x[11] = 'USA'
else:
x[11] = 'not USA'
if dataline[12] == '<=50K':
x[12] = '<=50K'
else:
x[12] = '>50K'
new_data.append(x)
return new_data
def translateToValue(filename): #把数据集转换成数值型的
age = {'0-25':0,'25-50':1,'50-75':2,'75-100':3}
capital_gain = {'=0':0, '>0':1} #10
capital_loss = {'=0':0, '>0':1} #11
hours_per_week = {'=40':0, '>40':1, '<40':2} #12
native_country = {'USA':0, 'not USA':1} #13
workclass= {'Freelance': 1, 'Other': 3, 'Proprietor': 4, 'Private': 2, 'Government': 0}
education= {'Primary': 2, 'Tertiary': 0, 'Secondary': 1}
maritial_status= {'1': 1, '0': 0}
occupation= {'High': 1, 'Med': 2, 'Low': 0}
relationship= {'Other': 0, 'Husband': 1, 'Wife': 2}
race= {'1': 0, '0': 1}
sex= {'Male': 0, 'Female': 1}
income = {'<=50K':0, '>50K':1}
csvfile = file(filename, 'rb')
reader = csv.reader(csvfile)
data = []
for line in reader:
data.append(line)
csvfile.close()
new_data = []
mark = 0
for dataline in data:
x = [0,0,0,0,0,0,0,0,0,0,0,0,0]
if mark ==0:
new_data.append(dataline)
mark += 1
else:
agenum = int(dataline[0])
if agenum>=0 and agenum<25:
x[0] = age['0-25']
elif agenum>=25 and agenum<50:
x[0] = age['25-50']
elif agenum>=50 and agenum<75:
x[0] = age['50-75']
elif agenum>=75:
x[0] = age['75-100']
x[1] = workclass[dataline[1]]
x[2] = education[dataline[2]]
x[3] = maritial_status[dataline[3]]
x[4] = occupation[dataline[4]]
x[5] = relationship[dataline[5]]
x[6] = race[dataline[6]]
x[7] = sex[dataline[7]]
gain = int(dataline[8])
if gain>0:
x[8] = capital_gain['>0']
else:
x[8] = capital_gain['=0']
loss = int(dataline[9])
if loss>0:
x[9] = capital_loss['>0']
else:
x[9] = capital_loss['=0']
hour = int(dataline[10])
if hour == 40:
x[10] = hours_per_week['=40']
elif hour > 40:
x[10] = hours_per_week['>40']
elif hour < 40:
x[10] = hours_per_week['<40']
if dataline[11] == 'United-States' :
x[11] = native_country['USA']
else:
x[11] = native_country['not USA']
if dataline[12] == '<=50K':
x[12] = income['<=50K']
else:
x[12] = income['>50K']
new_data.append(x)
return new_data
def write_new_data():
#adult_data_all在原始数据的基础上对某些属性做了一定的合并、修改等
new_data_value = translateToValue('adult_data_all.csv')
with open( './new_data_value.csv', 'wb') as f:
writer = csv.writer(f)
writer.writerows(new_data_value)
f.close()
new_data_value_test = translateToValue('adult_test_all.csv')
with open( './new_data_value_test.csv', 'wb') as f:
writer = csv.writer(f)
writer.writerows(new_data_value_test)
f.close()
new_data = translate('adult_data_all.csv')
with open( './new_data.csv', 'wb') as f:
writer = csv.writer(f)
writer.writerows(new_data)
f.close()
new_data_test = translate('adult_test_all.csv')
with open( './new_data_test.csv', 'wb') as f:
writer = csv.writer(f)
writer.writerows(new_data_test)
f.close()
def readData(filename):
csvfile = file(filename, 'rb')
reader = csv.reader(csvfile)
data_all = [] #训练数据集
data_feature = [] #特征列
data_label = [] #标签列
mark = 0
featurnlen = 0
for line in reader:
if mark ==0:
featurnlen = len(line) - 1
mark += 1
else:
data_all.append(line)
data_feature.append(line[0:featurnlen])
data_label.append(line[-1])
csvfile.close()
return data_all,data_feature,data_label
#调用sklearn的决策树函数
def use_sklearn_tree():
train_data,trainX,trainY = readData('new_data_value.csv')
test_data,testX,testY = readData('new_data_value_test.csv')
model = tree.DecisionTreeClassifier()
model.max_depth = 8
model.min_samples_split = 9
model.fit(trainX, trainY)
predict = model.predict(testX)
accuratyNum = 0
total = 0
for index in range(len(predict)):
if predict[index] == testY[index]:
accuratyNum += 1
total += 1
print "when use the sklearn............"
importances = model.feature_importances_
# print "the accuratyNum is",accuratyNum
# print "the total num is",total
print "the accuraty is"
accuracy = float(accuratyNum)/total
print 'accuracy: %.2f%%' % (100 * accuracy)
return model.tree_
def use_myTree():
adultLabels = ['age','workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country']
adultLabels_test = ['age','workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country']
adult = readData('new_data.csv')[0]
adult_test = readData('new_data_test.csv')[1]
adult_test_label = readData('new_data_test.csv')[2]
adultTree = trees.createTree(adult,adultLabels) #生成决策树
treePlotter.createPlot(adultTree) #画出决策树
predict = [] #预测的标签
for i in range(len(adult_test)):
predict.append(trees.classify(adultTree,adultLabels_test,adult_test[i]))
accuratyNum = 0
total = 0
for index in range(len(predict)):
if predict[index] == adult_test_label[index]:
accuratyNum += 1
total += 1
print "when use my tree..............."
# print "the accuratyNum is",accuratyNum
# print "the total num is",total
print "the accuraty is"
accuracy = float(accuratyNum)/total
print 'accuracy: %.2f%%' % (100 * accuracy)
print " "
return adultTree
#write_new_data()
myTree = use_myTree()
sklearnTree = use_sklearn_tree()
#accuracy,importance = use_sklearn_tree(8,9)
#accuracy = np.zeros(18)
#print accuracy
#for i in range(18):
# if i>=2:
# accuracy[i] = use_sklearn_tree(8,i)*100
#x = np.arange(0, 18, 1)
#y = accuracy
#plt.figure(1)
#plt.subplot(211)
#plt.axis([0, 18, 84, 84.25])
#plt.plot(x,y,marker='o',mec='r', mfc='w')