Keras 实现卷积神经网络识别手写数字、迁移学习以及tf.keras.applications使用
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
4.4 案例:CNN进行分类
4.4.1 卷积神经网络构建识别手写数字
卷积神经网络包含一个或多个卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully-connected Layer)。
4.4.1.1 使用 Keras 实现卷积神经网络
卷积神经网络的一个实现现如下所示,新加入了一些卷积层和池化层。当然这个网络可以增加、删除或调整 CNN 的网络结构和参数,以达到更好效果。
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 卷积核大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs) # [batch_size, 28, 28, 32]
x = self.pool1(x) # [batch_size, 14, 14, 32]
x = self.conv2(x) # [batch_size, 14, 14, 64]
x = self.pool2(x) # [batch_size, 7, 7, 64]
x = self.flatten(x) # [batch_size, 7 * 7 * 64]
x = self.dense1(x) # [batch_size, 1024]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
将前节的 model = MLP() 更换成 model = CNN() ,训练结束以及预测输出:
批次 4682: 损失 0.010545
批次 4683: 损失 0.003783
批次 4684: 损失 0.000980
测试准确率: 0.990600
可以发现准确率相较于之前的多层感知机有非常显著的提高。
我们来看一个个问题如果我们要做一个具体场景的计算机视觉任务,那么从头开始训练一个网络是合适的选择吗?怎么样才能避免浪费过多的计算时间?
keras_mlp.py
import tensorflow as tf
import numpy as np
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
num_epochs = 5
batch_size = 64
learning_rate = 0.001
class MnistLoader(object):
"""数据加载处理类
"""
def __init__(self):
# 1、获取数据
(self.train_data, self.train_label), (self.test_data, self.test_label) = \
tf.keras.datasets.mnist.load_data()
# 2、处理数据, 归一化,维度拓展,类型
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1)
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1)
self.train_label = self.train_label.astype(np.int32)
self.test_label = self.test_label.astype(np.int32)
# 获取一个变量接收数据量
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
"""按照训练获取指定大小数据的批次数据
:param batch_size: 每批次数据的大小
:return:
"""
# 获取随机生成的batch_size大小的下标
index = np.random.randint(0, self.train_data.shape[0], batch_size)
return self.train_data[index, :], self.train_label[index]
class MLP(tf.keras.Model):
"""自定义MLP类
"""
def __init__(self):
super().__init__()
# 卷积到全连接层的数据形状处理
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
"""
:param inputs: 模型的输入
:return:
"""
# 此例子中输入[batch_size, 28 ,28, 1]
x = self.flatten(inputs)
x = self.dense1(x)
x = self.dense2(x)
# 经过softmax计算[batch_size, 10]
output = tf.nn.softmax(x)
return output
class CNN(tf.keras.Model):
"""自定义CNN类,两层卷积池化+两个全连接层
"""
def __init__(self):
super().__init__()
# 两层卷积池化+两个全连接层
# [batch_size, 28 ,28, 1]--->[batch_size, 14, 14, 32]
# 第一层:32个filter, 5 * 5, padding=same
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积核数量
kernel_size=[5, 5], # 卷积核大小
padding='same', # 领填充方式
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
# 第二层:64个filter, 5 * 5, padding=same
# [batch_size, 14 ,14, 32]--->[batch_size, 7, 7, 64]
self.conv2 = tf.keras.layers.Conv2D(
filters=64, # 卷积核数量
kernel_size=[5, 5], # 卷积核大小
padding='same', # 领填充方式
activation=tf.nn.relu # 激活函数
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
# 经过一个形状变化在输入到全连接层网络
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
"""模型输入输出构建
:param inputs: 输入[batch_size, 28 ,28, 1]
:return:
"""
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
def train():
"""模型训练逻辑
:return:
"""
# 1、从 DataLoader 中随机取一批训练数据,并且初始化模型
mnist = MnistLoader()
# model = MLP()
model = CNN()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
# 2、将这批数据送入模型,计算出模型的预测值;
# 总共样本len(train_data), 迭代次数epoches表示所有数据过几遍,batch_size:每批次训练的样本32, 64
# 一共需要多少批次 len(train_data)/ batch_size * epoches举例 1000/10 = 10批次才训练完成,10 * 5
num_batches = int(mnist.num_train_data // batch_size * num_epochs)
for batch_index in range(num_batches):
X, y = mnist.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
# 3、将模型预测值与真实值进行比较,计算损失函数(loss)。这里使用
# tf.keras.losses 中的交叉熵函数作为损失函数;
loss = tf.reduce_mean(tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred))
print("批次 %d: 损失 %f" % (batch_index, loss.numpy()))
# 4、计算损失函数关于模型变量的导数;
grads = tape.gradient(loss, model.variables)
# 5、将求出的导数值传入优化器,使用优化器的 apply_gradients 方法更新模型参数以最小化损失函数(优化器的详细使用方法见 前章 )。
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
# 3、对测试数据及进行评估
y_pred = model.predict(mnist.test_data)
# 初始化一个metrics
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
sparse_categorical_accuracy.update_state(y_true=mnist.test_label, y_pred=y_pred)
print("测试准确率:%f" % (sparse_categorical_accuracy.result()))
return None
if __name__ == '__main__':
# mnist = MnistLoader()
# train_data, train_label = mnist.get_batch(64)
# print(train_data, train_label)
train()
4.4.2 迁移学习(Transfer Learning)-Keras 中预定义的经典卷积神经网络结构
4.4.2.1 介绍
- 定义
- 迁移学习就是利用数据、任务或模型之间的相似性,将在旧的领域学习过或训练好的模型,应用于新的领域这样的一个过程。
- 两个任务的输入属于同一性质:要么同是图像、要么同是语音或其他
迁移学习到底在什么情况下使用呢?有两个方面需要我们考虑的
- 1、当我们有海量的数据资源时,可以不需要迁移学习,机器学习系统很容易从海量数据中学习到一个鲁棒性很强的模型。但通常情况下,我们需要研究的领域可获得的数据极为有限,在少量的训练样本上精度极高,但是泛化效果极差。
- 2、训练成本,很少去从头开始训练一整个深度卷积网络,从头开始训练一个卷积网络通常需要较长时间且依赖于强大的 GPU 计算资源。
4.4.2.2 方法
- 最常见的称呼叫做fine tuning,即微调
- 已训练好的模型,称之为Pre-trained model
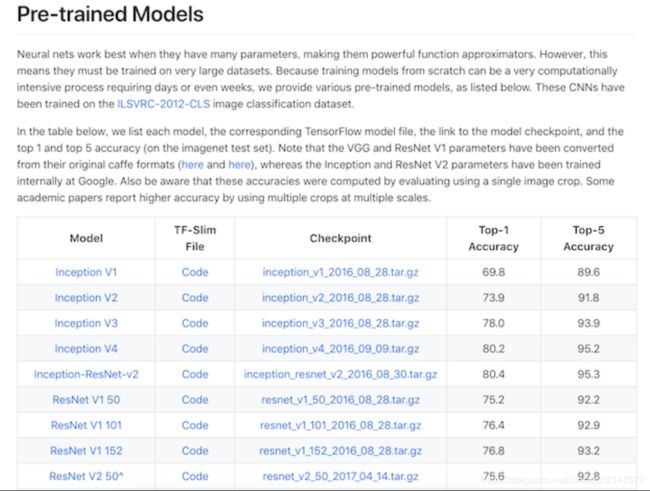
通常我们需要加载以训练好的模型,这些可以是一些机构或者公司在ImageNet等类似比赛上进行训练过的模型。TensorFlow同样也提供了相关模型地址以及API:https://www.tensorflow.org/api_docs/python/tf/keras/applications
下图是其中包含的一些模型:
2.5.1.3 过程
这里我们举一个例子,假设有两个任务A和B,任务 A 拥有海量的数据资源且已训练好,但并不是我们的目标任务,任务 B 是我们的目标任务。下面的网络模型假设是已训练好的1000个类别模型

而B任务假设是某个具体场景如250个类别的食物识别,那么该怎么去做
- 1、建立自己的网络,在A的基础上,修改最后输出结构,并加载A的模型参数
- 2、根据数据大小调整
- 如果B任务数据量小,那么我们可以选择将A模型的所有的层进行freeze(可以通过Tensorflow的trainable=False参数实现),而剩下的输出层部分可以选择调整参数训练
- 如果B任务的数据量大,那么我们可以将A中一半或者大部分的层进行freeze,而剩下部分的layer可以进行新任务数据基础上的微调
4.4.2 使用
tf.keras.applications 中有一些预定义好的经典卷积神经网络结构,如 VGG16 、 VGG19 、 ResNet 、 MobileNet 等。我们可以直接调用这些经典的卷积神经网络结构(甚至载入预训练的参数),而无需手动定义网络结构。
-
支持以下结构:
- densenet module: DenseNet models for Keras.
- imagenet_utils module: Utilities for ImageNet data preprocessing & prediction decoding.
- inception_resnet_v2 module: Inception-ResNet V2 model for Keras.
- inception_v3 module: Inception V3 model for Keras.
- mobilenet module: MobileNet v1 models for Keras.
- mobilenet_v2 module: MobileNet v2 models for Keras.
- nasnet module: NASNet-A models for Keras.
- resnet module: ResNet models for Keras.
- resnet50 module: Public API for tf.keras.applications.resnet50 namespace.
- resnet_v2 module: ResNet v2 models for Keras.
- vgg16 module: VGG16 model for Keras.
- vgg19 module: VGG19 model for Keras.
- xception module: Xception V1 model for Keras.
-
我们可以使用以下代码来实例化一个 MobileNetV2 网络结构:
- model = tf.keras.applications.MobileNetV2()
- input_shape :输入张量的形状(不含第一维的 Batch),大多默认为 224 × 224 × 3 。一般而言,模型对输入张量的大小有下限,长和宽至少为 32 × 32 或 75 × 75 ;
-
include_top :在网络的最后是否包含全连接层,默认为 True ;
-
weights :预训练权值,默认为 'imagenet' ,即为当前模型载入在 ImageNet 数据集上预训练的权值。如需随机初始化变量可设为 None ;
-
classes :分类数,默认为 1000。修改该参数需要 include_top 参数为 True 且 weights 参数为 None 。
当执行以上代码时,TensorFlow 会自动从网络上下载 MobileNetV2 网络结构,因此在第一次执行代码时需要具备网络连接。
可以使用 MobileNetV2 网络对相关数据集进行训练看看效果
model = tf.keras.applications.MobileNetV2(weights=None, classes=5)
4.4.3 总结
- 掌握keras卷积网络相关API
- 卷机网络的构建
- 迁移学习以及tf.keras.applications使用
transfer_learning.py
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input
import numpy as np
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
class TransferModel(object):
"""VGG迁移学习做5个类别图片识别
"""
def __init__(self):
# 初始化训练集和测试集的迭代器
self.train_generator = ImageDataGenerator(rescale=1.0 / 255.0,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
self.test_generator = ImageDataGenerator(rescale=1.0 / 255.0)
# 数据目录
self.train_dir = "./data/train"
self.test_dir = "./data/test"
# 定义输入数据的大小和批次大小
self.image_size = (224, 224)
self.batch_size = 32
# 初始化VGG基础模型,
self.base_model = VGG16(weights='imagenet', include_top=False)
self.label_dict = {
'0': 'bus',
'1': 'dinosaurs',
'2': 'elephants',
'3': 'flowers',
'4': 'horse'
}
def get_local_data(self):
"""读取本地的图片数据以及类别标签
:return:
"""
# 1、datagen.flow_from_directory
train_gen = self.train_generator.flow_from_directory(self.train_dir,
target_size=self.image_size,
batch_size=self.batch_size,
class_mode='binary',
shuffle=True)
test_gen = self.train_generator.flow_from_directory(self.test_dir,
target_size=self.image_size,
batch_size=self.batch_size,
class_mode='binary',
shuffle=True)
return train_gen, test_gen
def refine_base_model(self):
"""
修改VGG的模型,在VGG的5个block,[None, ?, ?, 512]--->全局平均池化-->两个全连接层1024, 5
:return: 新的迁移学习模型
"""
# 1、获取VGG模型的输出,不包含原有模型的top结构
x = self.base_model.outputs[0]
# 2、在VGG的输出之后定义自己的模型
x = tf.keras.layers.GlobalAveragePooling2D()(x)
# 两个全连接层
x = tf.keras.layers.Dense(1024, activation=tf.nn.relu)(x)
y_predict = tf.keras.layers.Dense(5, activation=tf.nn.softmax)(x)
# 3、使用Model封装新的模型返回
transfer_model = tf.keras.models.Model(inputs=self.base_model.inputs, outputs=y_predict)
return transfer_model
def freeze_vgg_model(self):
"""
冻结VGG的前面卷积结构,不参与训练
:return:
"""
# 循环获取base_model当中的层
for layer in self.base_model.layers:
layer.trainable = False
return None
def compile(self, model):
"""
编译模型,指定优化器损失计算方式,准确率衡量
:return:
"""
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
return None
def fit_generator(self, model, train_gen, test_gen):
"""进行模型训练,注意使用fit_generator,不是fit
:param model:
:param train_gen:
:param test_gen:
:return:
"""
modelckpt = tf.keras.callbacks.ModelCheckpoint('./ckpt/transfer_{epoch:02d}-{val_accuracy:.2f}.h5',
monitor='val_accuracy',
save_best_only=True,
save_weights_only=False,
mode='auto',
period=1)
model.fit_generator(train_gen, epochs=3, validation_data=test_gen, callbacks=[modelckpt])
return None
def predict(self, model):
"""预测输入图片的类别
:return:
"""
# 1、加载模型训练好的权重
model.load_weights("./ckpt/transfer_01-0.84.h5")
# 2、读取图片处理图片数据,形状,数据归一化
image = tf.io.read_file("./data/test/dinosaurs/402.jpg")
image_decoded = tf.image.decode_jpeg(image)
image_resized = tf.image.resize(image_decoded, [224, 224]) / 255.0
# 3维-->4维的形状改变
img = tf.reshape(image_resized, (1, image_resized.shape[0], image_resized.shape[1], image_resized.shape[2]))
print("修改之后的形状:", img.shape)
# 3、输入数据做预测
y_predict = model.predict(img)
index = np.argmax(y_predict, axis=1)
print(self.label_dict[str(index[0])])
return None
if __name__ == '__main__':
tm = TransferModel()
# # 训练模型步骤
# # 1、读取数据
# train_gen, test_gen = tm.get_local_data()
# # print(train_gen, test_gen)
# # 2、定义模型去微调模型和冻结模型
# # 3、模型的compile和训练
# model = tm.refine_base_model()
# print(model.summary())
# tm.freeze_vgg_model()
# tm.compile(model)
# tm.fit_generator(model, train_gen, test_gen)
# 测试数据
transfer_model = tm.refine_base_model()
tm.predict(transfer_model)
fashion_mnist.py
import tensorflow as tf
import numpy as np
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
num_epochs = 10
batch_size = 64
learning_rate = 0.001
class MnistLoader(object):
"""数据加载处理类
"""
def __init__(self):
# 1、获取数据
(self.train_data, self.train_label), (self.test_data, self.test_label) = \
tf.keras.datasets.fashion_mnist.load_data()
# 2、处理数据, 归一化,维度拓展,类型
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1)
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1)
self.train_label = self.train_label.astype(np.int32)
self.test_label = self.test_label.astype(np.int32)
# 获取一个变量接收数据量
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
"""按照训练获取指定大小数据的批次数据
:param batch_size: 每批次数据的大小
:return:
"""
# 获取随机生成的batch_size大小的下标
index = np.random.randint(0, self.train_data.shape[0], batch_size)
return self.train_data[index, :], self.train_label[index]
class MLP(tf.keras.Model):
"""自定义MLP类
"""
def __init__(self):
super().__init__()
# 卷积到全连接层的数据形状处理
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=128, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
"""
:param inputs: 模型的输入
:return:
"""
# 此例子中输入[batch_size, 28 ,28, 1]
x = self.flatten(inputs)
x = self.dense1(x)
x = self.dense2(x)
# 经过softmax计算[batch_size, 10]
output = tf.nn.softmax(x)
return output
class CNN(tf.keras.Model):
"""自定义CNN类,两层卷积池化+两个全连接层
"""
def __init__(self):
super().__init__()
# 两层卷积池化+两个全连接层
# [batch_size, 28 ,28, 1]--->[batch_size, 14, 14, 32]
# 第一层:32个filter, 5 * 5, padding=same
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积核数量
kernel_size=[3, 3], # 卷积核大小
padding='same', # 领填充方式
activation=tf.nn.relu, # 激活函数
kernel_regularizer=tf.keras.regularizers.l2(0.0001)
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
# 第二层:64个filter, 5 * 5, padding=same
# [batch_size, 14 ,14, 32]--->[batch_size, 7, 7, 64]
self.conv2 = tf.keras.layers.Conv2D(
filters=64, # 卷积核数量
kernel_size=[3, 3], # 卷积核大小
padding='same', # 领填充方式
activation=tf.nn.relu, # 激活函数
kernel_regularizer=tf.keras.regularizers.l2(0.0001)
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
# 经过一个形状变化在输入到全连接层网络
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu, kernel_regularizer=tf.keras.regularizers.l2(0.0001))
self.dropout = tf.keras.layers.Dropout(rate=0.4)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
"""模型输入输出构建
:param inputs: 输入[batch_size, 28 ,28, 1]
:return:
"""
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.flatten(x)
x = self.dense1(x)
# x = self.dropout(x, training=True)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
def train():
"""模型训练逻辑
:return:
"""
# 1、从 DataLoader 中随机取一批训练数据,并且初始化模型
mnist = MnistLoader()
# model = MLP()
model = CNN()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
# 2、将这批数据送入模型,计算出模型的预测值;
# 总共样本len(train_data), 迭代次数epoches表示所有数据过几遍,batch_size:每批次训练的样本32, 64
# 一共需要多少批次 len(train_data)/ batch_size * epoches举例 1000/10 = 10批次才训练完成,10 * 5
num_batches = int(mnist.num_train_data // batch_size * num_epochs)
for batch_index in range(num_batches):
X, y = mnist.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
# 3、将模型预测值与真实值进行比较,计算损失函数(loss)。这里使用
# tf.keras.losses 中的交叉熵函数作为损失函数;
loss = tf.reduce_mean(tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred))
print("批次 %d: 损失 %f" % (batch_index, loss.numpy()))
# 4、计算损失函数关于模型变量的导数;
grads = tape.gradient(loss, model.variables)
# 5、将求出的导数值传入优化器,使用优化器的 apply_gradients 方法更新模型参数以最小化损失函数(优化器的详细使用方法见 前章 )。
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
# 3、对测试数据及进行评估
y_pred = model.predict(mnist.test_data)
# 初始化一个metrics
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
sparse_categorical_accuracy.update_state(y_true=mnist.test_label, y_pred=y_pred)
print("测试准确率:%f" % (sparse_categorical_accuracy.result()))
return None
if __name__ == '__main__':
# mnist = MnistLoader()
# train_data, train_label = mnist.get_batch(64)
# print(train_data, train_label)
train()
