CNN:RCNN、SPPNet、Fast RCNN、Faster RCNN、YOLO V1 V2 V3、SSD、FCN、SegNet、U-Net、DeepLab V1 V2 V3、Mask RCNN
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
- CNN:
- 目标检测:
- RCNN
- SPPNet
- Fast RCNN
- Faster RCNN
- YOLO V1
- YOLO V2
- YOLO V3
- SSD
- 目标分割:
- FCN
- SegNet
- U-Net
- DeepLab V1
- DeepLab V2
- DeepLab V3
- DeepLab V3+
- Mask RCNN
- 单目标跟踪:
- FCNT
- GOTURN
- Siamese系列网络:
- SiamFC
- SiamRPN
- DaSiamRPN
- SiamRPN++
- SiamMask
- 目标检测:
目标检测
目标检测:R-CNN
目标检测:SPPNet
目标检测:Fast R-CNN
目标检测:Faster R-CNN、Faster RCNN接口
目标检测:YOLO V1、YOLO V2、YOLO V3 算法
目标检测:SSD 算法
目标分割
目标分割:FCN全卷积网络、上采样upsample、反卷积/转置卷积Conv2DTranspose、跳跃连接skip layers实现融合预测fusion prediction
目标分割:SegNet、U-Net
目标分割:DeepLab V1、DeepLab V2、DeepLab V3、DeepLab V3+、ASPP/ASPP+、Encoder-Decoder、CRF
计算IoU:计算交并比
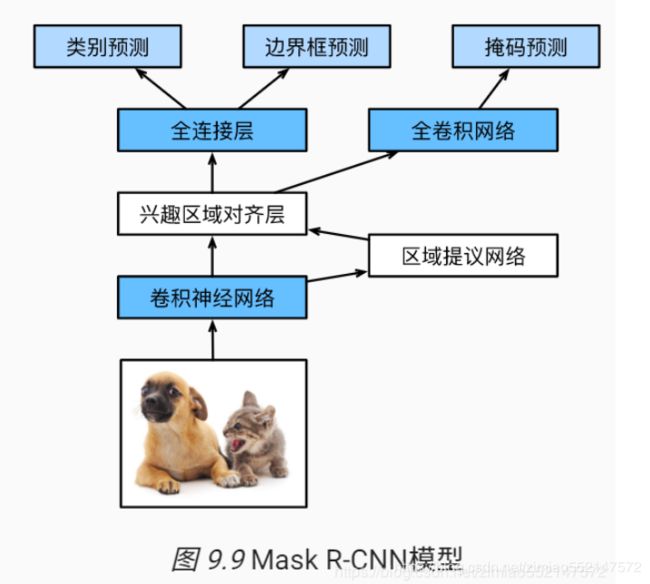
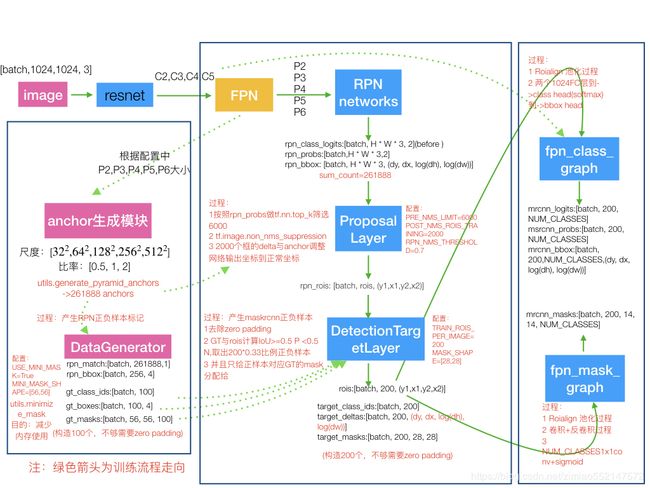
目标分割:Mask RCNN
目标分割:Mask RCNN 气球分割案例 part1
目标分割:Mask RCNN 气球分割案例 part2
目标追踪:FCNT、GOTURN、SiamFC
单目标跟踪 Siamese系列网络:SiamFC、SiamRPN、one-shot跟踪、one-shotting单样本学习、DaSiamRPN、SiamRPN++、SiamMask
单目标跟踪SiamMask:特定目标车辆追踪 part1
单目标跟踪SiamMask:特定目标车辆追踪 part2
单目标跟踪:跟踪效果
单目标跟踪:数据集处理
单目标跟踪:模型搭建
单目标跟踪:模型训练
单目标跟踪:模型测试


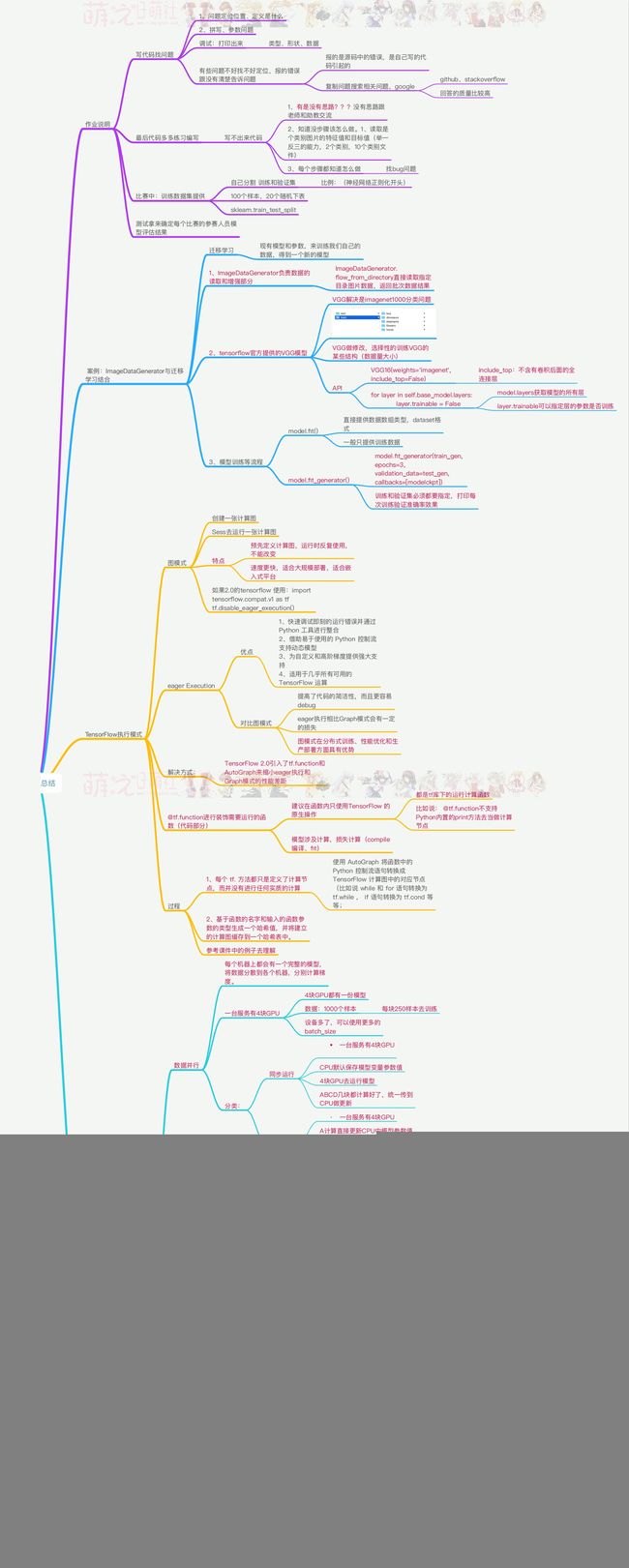














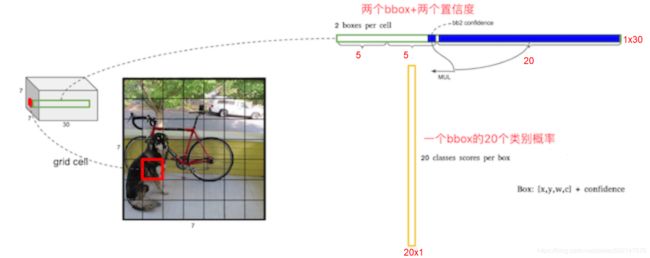
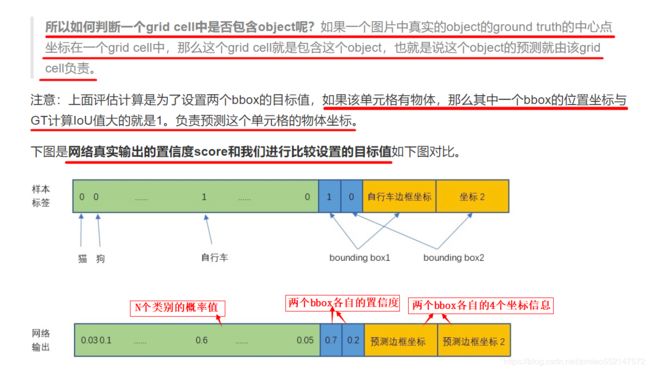





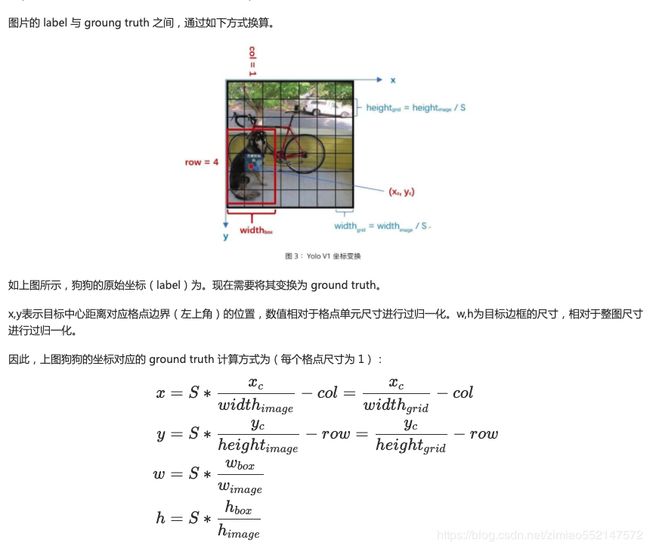
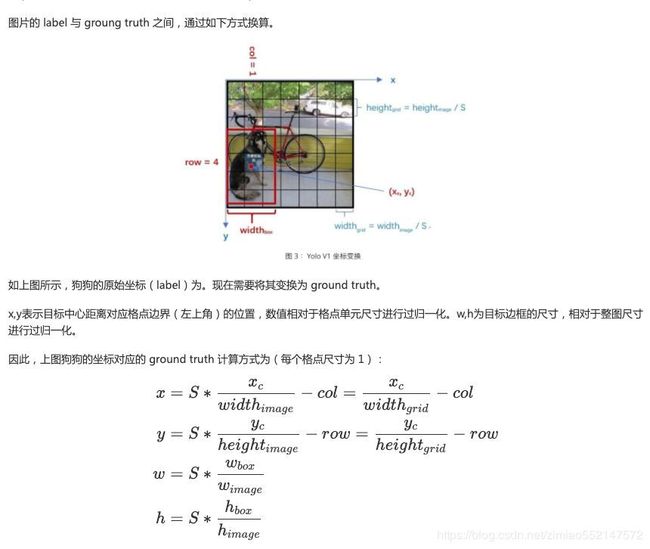
1.原始图片resize到448x448,经过前面卷积网络之后,将图片输出成了一个7 x 7 x 30的特征图。
根据7x7的特征图大小在输入原图上分成7x7=49个网格,如果目标的中心落入到某个网格单元cell中,那么该网格单元cell就负责检测该目标。
7x7的特征图大小:7x7=49个像素值,理解成49个单元格,每个单元格可以代表原图的一个方块。
2.每个网格单元cell都会预测N个边界框bounding boxes和每个bbox框的1个置信度分数confidence scores,
这些置信度分数反映了该模型对那个框内是否包含目标的信心,以及它对自己的预测的准确度的估量。
3.yolo V1、yolo V2、yolo V3 的bbox(边界框bounding boxes)数目变化
1.yolo V1:
1.每个网格单元cell预测2个(默认)bbox(边界框bounding boxes):输入图像一共有 7x7x2=98个bbox(边界框bounding boxes)
2.每个bbox(边界框bounding boxes)包含4个预测位置(x、y、w、h),1个bbox置信度分数confidence scores
3.一个网格单元预测cell的2个(默认)bbox(边界框bounding boxes)一共的预测数据量:2x(4+1)+20=30
4个预测位置(x、y、w、h)和1个bbox置信度分数confidence scores代表一个bbox的预测数据量。
20代表1个bbox的20个类别的预测概率值,每个单元格选出20个类别的预测概率中的最大概率值的一个类别,那么一个单元格就只能代表一个类别,
这也是yolo V1的缺点,yolo V1就只会1个单元格cell预测1个目标物体,对于检测效果并不好,因此并不建议使用yolo V1。
4.输入图像一共预测的数据量:7x7x(2x(4+1)+20)=1470
7x7的特征图大小即输入图像中的网格数。
2x(4+1)即每个网格都预测2个边界框bounding boxes的4个预测位置(x、y、w、h),1个bbox置信度分数confidence scores。
加20即是因为在yolo V1中一个网格中的2个bbox中最终只会有1个bbox用于预测目标物体,因此如果多个目标物体都在一个单元格cell中出现的话,
如果使用了yolo V1就只会1个单元格cell预测1个目标物体,对于检测效果并不好,因此并不建议使用yolo V1。
2.yolo V2:
1.每个网格单元cell都使用5种(默认)不同尺寸的锚框Anchor boxes来预测bbox(边界框bounding boxes),
一个网格单元cell中每种不同尺寸的锚框Anchor boxes各预测一个bbox(边界框bounding boxes),一共预测5个(默认)bbox(边界框bounding boxes)。
输入图像一共预测有 13x13x5=845个bbox(边界框bounding boxes)。
注意:5个(默认)的锚框Anchor boxes的尺寸大小都是不一样的。
2.每种不同尺寸的锚框Anchor boxes所预测的bbox(边界框bounding boxes)包含:4个预测位置(x、y、w、h),1个bbox置信度分数confidence scores,
N个分类类别的预测概率值。
3.一个网格单元cell中5种(默认)不同尺寸的锚框Anchor boxes所预测的5个(默认)bbox(边界框bounding boxes)一共预测的数据量(假如预测20个类别):
5x(4+1+20)=125
5代表5个(默认)bbox(边界框bounding boxes)。
每个bbox(边界框bounding boxes)都分别有4个预测位置(x、y、w、h),1个bbox置信度分数confidence scores,20个类别的预测概率值。
4.输入图像一共预测的数据量(假如预测20个类别和在13x13特征图上做预测):13x13x(5x(4+1+20))=169*125=21125
5.YOLO V2基于卷积的Anchor机制(Convolutional With Anchor Boxes):从YOLOV1中移除全连接层,
并使用5个(默认)不同尺寸的锚框Anchor boxes来预测bbox(边界框bounding boxes)。
YOLO V2通过缩减网络,使用416x416的输入,模型下采样的总步长为32,最后得到13x13的特征图,13x13的特征图对应在输入原图分割13x13个单元格cell。
每个单元格cell预测5个不同尺寸锚框anchor boxes对应的bbox(边界框bounding boxes),每个锚框anchor box所预测的bbox(边界框bounding boxes)
包含4个位置信息、1个置信度、N个分类类别的概率值。
YOLO V2采用的5种不同尺寸锚框Anchor boxes可以预测13x13x5=845个bbox(边界框bounding boxes)。
YOLO V2引⼊faster rcnn中anchor机制,anchor尺度就是用来预测网络预测值和目标GT做尺度变换的。
6.维度聚类
Faster-RCNN中anchor boxes的个数和宽高维度往往是手动精选的先验框(hand-picked priors),
设想能否一开始就选择了更好的、更有代表性的先验boxes维度,那么网络就应该更容易学到准确的预测位置,
YOLOv2使用k-means聚类算法对训练集中的边界框做了聚类分析,尝试通过维度聚类找到合适尺寸的锚框Anchor boxes。
YOLOV2没有使用FasterRCNN预测偏移和尺度变换。而是遵循YOLOV1的方法,预测相对于网格单元位置的位置坐标。
这使得真实值的界限在0到1之间。
3.yolo V3:
1.特征金字塔(FPN网络)
yolo V3使用了特征金字塔(FPN网络),yolov3在3个不同尺度的特征图上做预测。
比如:13x13,26x26,52x52三个不同尺度特征图上的每个单元格cell分别使用3种(默认)不同尺寸的锚框Anchor boxes来预测bbox(边界框bounding boxes)。
每种不同尺寸的锚框Anchor boxes所预测的bbox(边界框bounding boxes)包含:4个预测位置(x、y、w、h),1个bbox置信度分数confidence scores,
N个分类类别的概率值。
那么一个NxN的特征图大小就有NxN个网格单元cell,那么每个网格单元cell预测数据量为3x(4+1+N个分类类别的概率值),
一整个特征图一共预测数据量为NxNx(3x(4+1+N个分类类别的概率值))。
yolo V3在13x13,26x26,52x52大小的三个特征图做预测计算,特征图比例大小分别是13x13为NxN,26x26为2x(NxN),52x52为4x(NxN),
那么3个不同尺度特征图一共预测数据量为(NxN + 2x(NxN) + 4x(NxN)) x (3x(4+1+N个分类类别的概率值))
2.每种不同尺度特征图上所设置的先验框(bbox边界框bounding boxes)大小,
会从下面的array数组yolo_anchors中选出对应合适的组合作为先验框(bbox边界框bounding boxes)的大小。
yolo_anchors = np.array([(10, 13), (16, 30), (33, 23), (30, 61), (62, 45), (59, 119), (116, 90), (156, 198), (373, 326)],
np.float32) / 416
1.yolo V2、yolo V3中的每个bbox(边界框bounding boxes)的预测值:4个预测位置(x、y、w、h)、1个bbox置信度分数confidence scores、N个类别的预测概率值。
2.(x, y) 表示bbox的中心点相对于单元格(grid cell)原点的偏移值,单元格(grid cell)的原点即为当前单元格的左上角的顶点(top-left),
yolo将左上角的顶点(原点)设置为(0, 0),右下角的顶点设置为(1, 1),所以x和y的取值范围都分别是在0到1之间。
x和y将始终介于0到1之间,因为中心点始终位于单元格(grid cell)内。
之所以把(x, y)预测为相对于网格单元cell的位置坐标,使得真实值的界限在0到1之间,因此参数化更容易学习,从而使网络更加稳定。
3.(w, h) 表示为相对于整张图片的宽和高, 即使用图片的宽和高标准化自己。
如果边界框bbox的尺寸小于单元格(grid cell)的尺寸的话,w和h的取值范围都分别是在0到1之间。
如果边界框bbox的尺寸大于单元格(grid cell)的尺寸的话,w和h的取值范围都可以大于1。
4.yolo V2、yolo V3都基于卷积的Anchor机制(Convolutional With Anchor Boxes)
yolo V2使用5种不同尺寸的锚框Anchor boxes预测边界框的4个位置信息、1个置信度、N个分类类别的概率值。
yolo V3使用3种不同尺寸的锚框Anchor boxes预测边界框的4个位置信息、1个置信度、N个分类类别的概率值。
5.比如在yolo V2中,13*13特征图上的每个单元格(grid cell)中预测5个不同尺寸的锚框Anchor boxes。
anchor尺寸就是用来预测网络预测值和目标GT之间做尺度变换的。
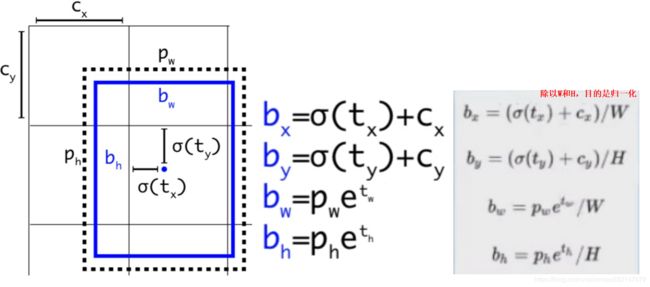
比如下面的蓝色框是预测的bbox(边界框bounding boxes),黑色点的矩形框是锚框Anchor boxes。
每一个bbox(边界框bounding boxes)都预测:tx、ty、tw、th、to(置信度)。
如果这个单元格(grid cell)距离输入原图的左上角原点的边距离为(cx,cy),该单元格(grid cell)对应的边界框bbox维度(边界框优先bounding box prior)的长和宽分别为(pw,ph),
那么对应的边界框bbox计算结果实际为:
1.yolo V2中不同尺寸的锚框Anchor boxes所预测的bbox(边界框bounding boxes)的4个位置信息为(tx, ty, tw, th),
那么tx和ty分别为相对于单元格(grid cell)原点的0到1之间取值的值,tw和th则根据所预测的bbox(边界框bounding boxes)是大于还是小于单元格(grid cell)的尺寸来决定
tw和th的取值范围是在0到1之间还是在大于1。
2.pw和ph分别为手动设定的锚框Anchor boxes宽和高,而网络最终计算的预测结果为(bx, by, bw, bh),因此需要把(tx, ty, tw, th)转换为(bx, by, bw, bh)。
3.把(tx, ty, tw, th)转换为(bx, by, bw, bh)作为yolo输出层的最终输出:
σ读作sigma。Cx和Cy分别为当前单元格(grid cell)距离输入原图的左上角原点的边距离。W和H为输入原图像的宽和高。分别除以W和H,目的是归一化。
tx->bx:bx = (σ(tx) + Cx) / W
ty->by:by = (σ(ty) + Cy) / H
tw->bw:bw = (pw * e^tw) / W
th->bh:bh = (ph * e^th) / H
4.σ(tx) + Cx:边界框的中心点在输入原图像中的x坐标,也即边界框的中心点离输入原图像原点的x方向长度
σ(ty) + Cy:边界框的中心点在输入原图像中的y坐标,也即边界框的中心点离输入原图像原点的y方向长度
pw * e^tw:边界框在输入原图像中的宽度
ph * e^th:边界框在输入原图像中的高度