从YOLOV1到YOLOV3
YOLOv1
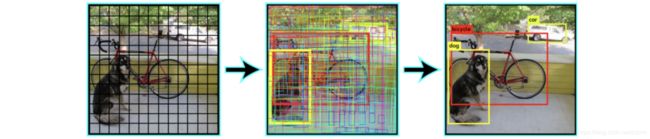
YOLOv1把输入图片切分成s×s个grid cell,每个grid cell只预测一个物体。如图所示:黄色grid cell会预测中心坐标点落入其中的这个person物体。
注意这里的grid cell只是在图像上看起来是一个方格,实际是原图在经过yolo网络之后会变成s×s的feature map,下图中的一个grid cell经过网络变换之后到最后的特征层变成了一个坐标点。比如原图为448×448经过yolo最后抽取得到的feature map为7×7×30。每个grid cell只预测固定数目的bbox。
然而,一个grid cell只预测一个物体的规则限制了YOLO的预测能力。如果几个物体密集紧邻(多个物体的中心坐标可能会落在一个grid cell里面),yolo就会遗漏一些物体。
对于每个grid cell
- 预测B个bbox,并且每个bbox有一个box置信度。
- 即便上面预测了B个box,但实际只会检测一个物体(只保留一个)
- 预测C个条件分类概率(每个目标分类的概率)
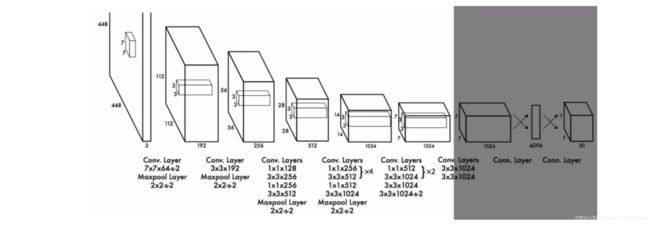
比如,对VOC数据集,YOLO使用了7×77×7(S=7)的grids,每个grid cell预测2(B=2)个bbox,以及20个分类(C=20)。
每个bbox有个5元组(x,y,w,h,conf),分别为bbox的坐标位置和置信度。这个置信度反映的是这个bbox包含目标(物体)的概率,以及此bbox的精确度。我们会对坐标位置进行归一化,变成0-1之间的比率(这一点,在准备yolo的训练数据时得到体现)。
注意,其中的x,y是相对于当前cell的偏移量。每个grid cell有20个条件分类概率,此条件分类概率是检测到的物体属于20个分类里某一分类的概率(每个grid cell为会所有的分类都有一个概率,此处20个分类,会有20个概率)。因此,yolo最终的预测矩阵为
(S,S,B×5+c)=(7,7,2×5+20)=(7,7,30)
这样会产生非常多的bbox(下图中间),但是只保留置信度高于一定阈值(0.25)的bbox作为最终预测(下图右边)。
 每个预测bbox的分类置信度计算公式如下: 分类置信度=box置信度×条件分类概率
每个预测bbox的分类置信度计算公式如下: 分类置信度=box置信度×条件分类概率
它同时在分类和定位上衡量预测的bbox的置信度
![]()
![]()
其中
- Pr(object)是bbox包含物体的概率
- IOU是预测bbox和真实bbox之间的IOU
- Pr(classi)是物体属于分类classi的概率
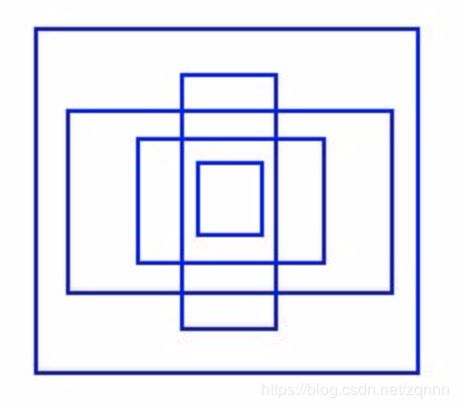
网络架构设计
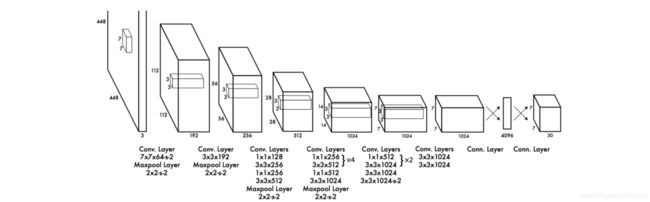
网络使用了24组卷积网络+2个全连接层。一些卷积层使用1×11×1以减小特征图深度。最后一个卷积层输出7×7×1024,再接2个全连接层实现一种线性回归,最终输出(7,7,30)。
损失函数
YOLO的每个grid cell预测多(VOC中是2个)个bbox。为了计算正阳性样本的损失,我们只要求它们之中的一个bbox对物体负责。因此,我们选取与真实标注(ground truth)有最高IOU的一个。这种策略导致bbox的的预测的特殊性,即每个预测在物体尺寸和比率上更准。
YOLO使用预测bbox和真实bbox的二次方差和来作为损失函数。损失函数由以下项组成
- 分类损失
- 定位损失:预测bbox和真实bbox之间的误差
- 置信度损失:box包含物体的置信度

回归损失
回归损失衡量的是,预测bbox的位置和尺寸的误差。YOLOv1只计算负责检测物体那个bbox的误差
![$$ \lambda {coord}\sum _{i=0} ^{S^2}\sum _{j=0} ^B1{ij} ^{obj}[(x_i-\hat x_i)^2+(y_i-\hat y_i)^2] \](http://img.e-com-net.com/image/info8/b138c1fbd4524eb9a915fb326a8af10e.gif)
![\lambda {coord}\sum _{i=0} ^{S^2}\sum _{j=0} ^B1{ij} ^{obj} [(\sqrt{w_i}-\sqrt{\hat w_i})^2+((\sqrt{h_i}-\sqrt{\hat {h_i}}))^2]](http://img.e-com-net.com/image/info8/a4edfa471c184df3ae15881297ec767f.gif)
其中 如果第i个grid cell中的第j个bbox是负责检测物体的,则![]() ,否则
,否则![]() .
.
![]() 增加bbox坐标的损失权重,默认为5
增加bbox坐标的损失权重,默认为5
在YOLO看来大的bbox和小的bbox的2个像素的误差是相等的,为刻意强调这一点,YOLO没有直接预测bbox的宽和高,而是宽的二次方根和高的二次方根。除此之外,对此loss乘以一个权重![]() 以增加bbox的准确率。
以增加bbox的准确率。
置信度损失
如果某个物体在box中被检测到,其置信度损失(衡量的是box中的物体)为

其中
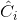 是
是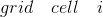 中第j个box的置信度
中第j个box的置信度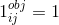 如果第i个grid cell的第j个box负责检测物体,否则为0
如果第i个grid cell的第j个box负责检测物体,否则为0
如果某个物体不在box中,其置信度损失为
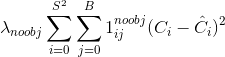
其中
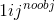 是对一种补充
是对一种补充- 是第i个grid cell的第j个box的置信度
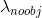 降低背景检测损失的权重(noobj即背景)
降低背景检测损失的权重(noobj即背景)- 由于大部分box不包含任何物体,这会导致分类(正负样本)的不均衡,因此,我们降低了背景检测损失的权重,即
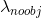 默认值为0.5
默认值为0.5

YOLOv2
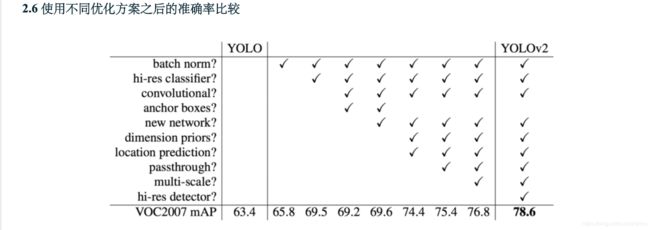
BatchNorm
每个卷积层之后添加一层BN,可以去掉dropout,同时提升2%的map
高分辨率
我们先看看yolov1的训练步骤
- 首先,训练一个类似VGG的分类网络【用的是224×224图片】
- 然后,使用全连接层替换卷积层
- 再端到端地训练目标检测【用的是448×448图片】
YOLOv2的训练步骤
- 训练一个分类器:先用224×224的图片训练,再用448×448图片接着训练(更少的epoch) 后续步骤一致。这使得yolov2的检测器更容易 训练,map也提升了4%。
anchor box
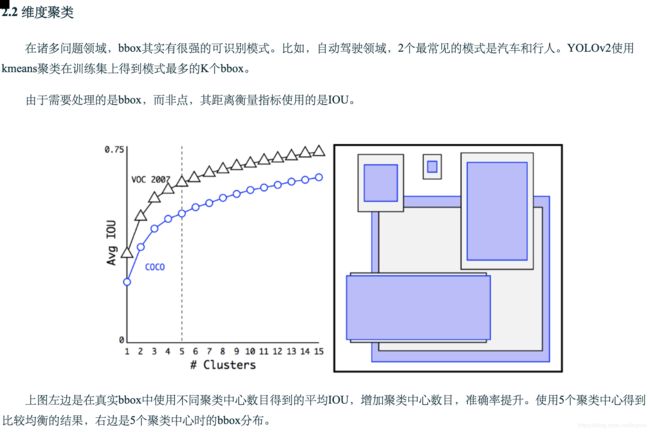
从yolo的论文中,我们得知,训练阶段的早期会出现不稳定的梯度,因为yolo会随意预测物体尺度和位置。而实际中,一些物体的尺寸是有规律的。比如汽车的长宽比一般是0.41
由于我们只需要一个bbox猜测值是对的就可以,因而如果我们按照实际物体比率来初始化这些预测的初始值,训练阶段就会稳定得多。例如,我们可以按照如下步骤构建5个anchor box
YOLOv2不直接预测bbox,而是预测其相对于上面5个bbox的偏移量。如果限制偏移量的值,我们可以保持预测的多样性,并使得每个预测集中于特定尺度,这样一来初始训练阶段就会稳定许多。
以下是对yolov1网络的改动
- 移除了最后两个负责预测bbox的全连接层
将分类预测从cell级转向bbox级。这样一来,每个预测包含了预测bbox的4个位置参数,一个box置信度(是否包含物体)以及20个分类概率。每个grid cell5个bbox,每个bbox25个参数,共125个参数。与yolov1一样,物体预测依旧是预测预测的bbox与真实bbox之间的IOU。
YOLOV1是怎么做预测的?
YOLOV2是怎么做预测的?

直接的位置预测
预测的是位置相对于anchor左上角的偏移量。如果直接,无约束的预测会导致随机结果,YOLO预测的是5个参数tx,ty,tw,th,to并使用sigma函数加以约束其取值范围。下图中蓝色框是预测的bbox,点线矩形框是anchor。左上角的Cx,CyCx,Cy也是anchor的左上角位置,预测的是相对于此处的偏移。


速度提升
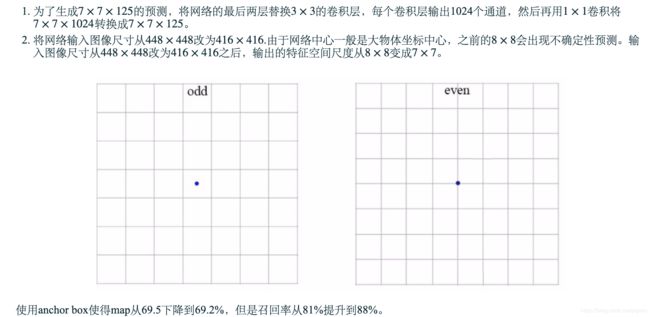
darknet 为了进一步简化CNN结构,设计了一个darknet网络。其在ImageNet上获取了72.9%的top-1准确率和91.2%的top-5准确率。darknet大部分使用的是3×3卷积
在做目标检测时,最后红色框的最后的卷积层使用3×33×3的卷积层替换,然后再使用1×1的卷积将7×7×1024的输出转换成7×7×125
yolov3
1. 类预测
大多数分类器认为目标分类是互斥的,所以yolov2用的是softmax,全部分类的概率之和为1,但是yolov3使用了多标签分类。比如,标签可能既是行人也可能是小孩。yolov3为每个分类使用独立的logistic分类器以计算输入属于特定分类的概率。yolov3给每个分类用的是二分交叉熵,而非MSE。此举同时降低了计算复杂度。
2. bbox预测和损失函数
yolov3使用logistic回归来预测每个bbox的为物体的置信度。yolov3修改计算损失函数的方式,如果bbox与真实标签obj重叠区域大于其他所有的,其对应的obj(物体)置信度为1(即选取一个与ground truth有最多重叠的anchor,其对应的obj score为1)。其他与真实标签obj重叠区域超过阈值(默认为0.5)的anchor,它们不计算损失。每个ground truth obj只分配给一个bbox。如果某个bbox没有被分配ground truth,不计算其分类和定位损失,只计算物体置信度。只使用tx,ty而非bx,by计算损失
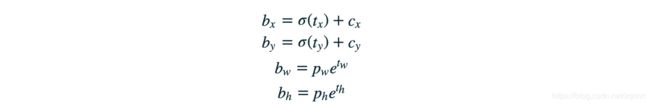

特征抽取器
使用一个新的darknet-53来替换前面的darknet-19,darknet主要由3×33×3和1×11×1卷积组成,以及一些类似ResNet的跳转连接。


