前几天在公司电脑上装了几台服务器,好多想尝试的东西,今天,参照崔庆才老师的爬虫实战课程,实践了一下分布式爬虫,并没有之前想象的那么神秘,其实非常的简单,相信你看过这篇文章后,不出一小时,便可以动手完成一个分布式爬虫!
1、分布式爬虫原理
首先我们来看一下scrapy的单机架构:
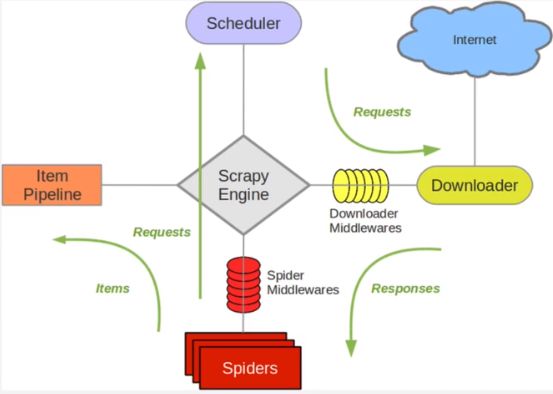
可以看到,scrapy单机模式,通过一个scrapy引擎通过一个调度器,将Requests队列中的request请求发给下载器,进行页面的爬取。
那么多台主机协作的关键是共享一个爬取队列。
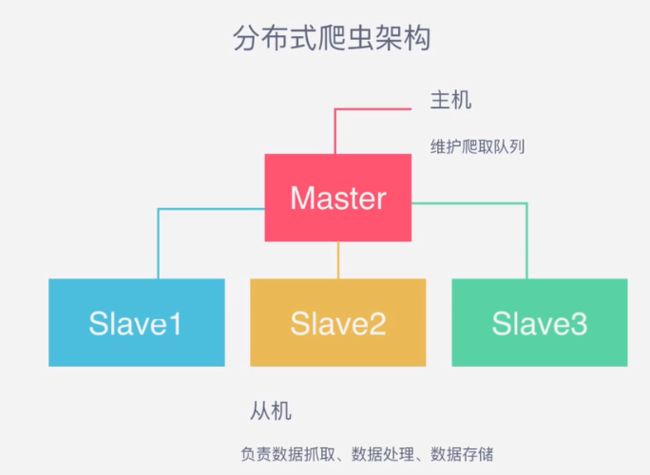
所以,单主机的爬虫架构如下图所示:

前文提到,分布式爬虫的关键是共享一个requests队列,维护该队列的主机称为master,而从机则负责数据的抓取,数据处理和数据存储,所以分布式爬虫架构如下图所示:
那么队列用什么维护呢,这里我们选用Redis队列进行存储,
Redis是一种高效的非关系型数据库,以key-value的形式存储,结构灵活,它是内存中的数据结构存储系统,处理速度快,性能好,同时,提供了队列,集合等多种存储结构,方便队列维护。
另外一个问题,如何去重?这个的意思就是如何避免多台主机访问的request都不同,即让Reques队列中的请求都是不同的,那么就需要用到Redis提供的队列结构。Redis提供集合数据结构,在Redis集合中存储每个Request的指纹,在向Request队列中加入Request时首先验证指纹是否存在。如果存在,则不加入,如果不存在,则加入。
2、环境配置
目前已经有专门的python库实现了分布式架构。Scrapy-Redis库改写了Scrapy的调度器,队列等组件,可以方便的实现Scrapy分布式架构。
Scrapy-Redis链接:https://github.com/rolando/scrapy-redis
不过,想要运用这个库,我们需要安装Redis数据库
(1)windows安装redis
下载地址:https://github.com/MSOpenTech/redis/releases
下载完成后,安装即可,非常简单(其实这里没有用到windows的redis,不过装一装也不麻烦),安装完成后,windows的本地redis服务是默认启动的。
接下来可以继续安装一个redis可视化工具,Redis Desktop Manager
下载地址:https://github.com/uglide/RedisDesktopManager/releases
我们选择一个比较稳定的版本进行下载:
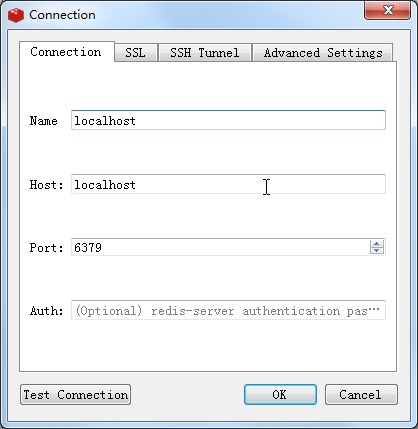
安装完成,我们可以测试一下本地的redis环境,输入我们的连接信息:
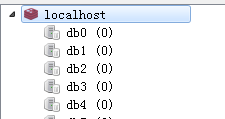
(2)linux下安装redis
linux下使用命令 sudo apt-get install redis即可完成安装,redis-server也是默认启动的,接下来,我们需要修改配置文件,使得我们主机可以访问虚拟机的redis数据库:
使用命令:sudo vim /etc/redis/redis.conf 进行修改:
1、将保护模式设置为no:
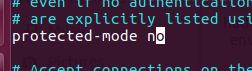
如果不设置此处的话,windows下访问redis直接崩溃。
2、bind ip注释掉:
如果不注释掉,只有本地可以访问redis,windows是不能访问的。
接下来重启我们的redis服务,使用命令sudo service redis restart
(3)windows下访问虚拟机redis
我们选择使用虚拟机上的redis数据库来维护爬取队列,所以接下来,我们使用windows下的可视化客户端访问虚拟机下的redis:
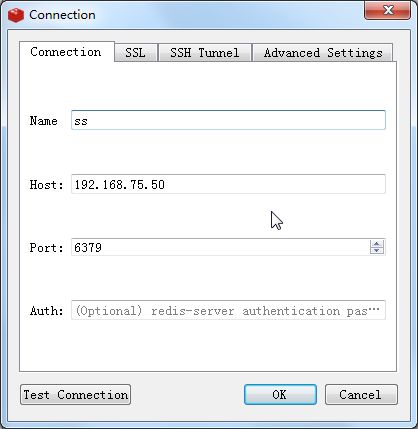
可以看到,成功访问:

3、代码实现
使用Scrapy-Redis实现分布式爬虫,需要在scrapy的setting.py中添加如下的配置,当然还有很多其他可用配置,这里只需添加如下的几个就可以实现分布是爬取:

SCHEDULER的意思就是使用Scrapy-Redis提供的调度器,DUPEFILTER_CLASS设置了去重机制,而后两个参数设置了下载队列的存储位置,即Redis数据库的位置。
实现的爬虫是百度贴吧的爬虫,这里就不详细说明了
具体代码参见:https://github.com/princewen/python3_crawl (使用python3.5编写)
使用winscp将代码上传到三台虚拟机上,并确保三台虚拟机有python的运行环境.
假设虚拟机上安装了python3,那么使用命令安装如下的依赖库:
sudo apt install python-pip
sudo pip install scrapy
sudo pip install scrapy_redis
sudo pip install pymongo
sudo pip install redis
4、代码运行及效果展示
我们在三台虚拟机上分别运行我们的爬虫代码抓取百度贴吧聊天吧的前100页信息,使用命令
scrapy crawl tieba
可以看到,三台虚拟机同时开始爬取:
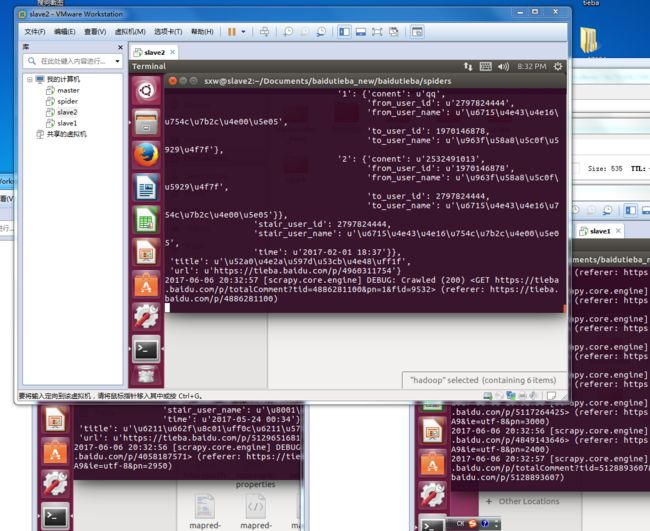
而redis中,则维护了一个爬取队列:

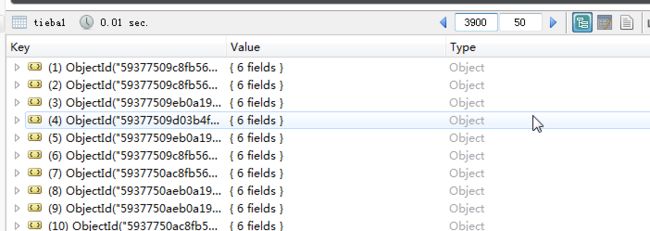
短短几分钟,我们就抓取了百度贴吧聊天吧的100页帖子3900+条,存入了本地的mongodb数据库:
至此,分布式爬虫练手完毕!
如果想要学习python爬虫的话,欢迎大家学习崔大神的爬虫课程。
地址:https://edu.hellobi.com/course/157