Hive-On-Spark
1 HiveOnSpark简介
Hive On Spark (跟hive没太大的关系,就是使用了hive的标准(HQL, 元数据库、UDF、序列化、反序列化机制))
Hive原来的计算模型是MR,有点慢(将中间结果写入到HDFS中)
Hive On Spark 使用RDD(DataFrame),然后运行在spark 集群上
真正要计算的数据是保存在HDFS中,mysql这个元数据库,保存的是hive表的描述信息,描述了有哪些database、table、以及表有多少列,每一列是什么类型,还要描述表的数据保存在hdfs的什么位置?
hive跟mysql的区别?
hive是一个数据仓库(存储数据并分析数据,分析数据仓库中的数据量很大,一般要分析很长的时间)
mysql是一个关系型数据库(关系型数据的增删改查(低延迟))
hive的元数据库中保存要计算的数据吗?
不保存,保存hive仓库的表、字段、等描述信息
真正要计算的数据保存在哪里了?
保存在HDFS中了
hive的元数据库的功能
建立了一种映射关系,执行HQL时,先到MySQL元数据库中查找描述信息,然后根据描述信息生成任务,然后将任务下发到spark集群中执行
hive on spark 使用的仅仅是hive的标准,规范,不需要有hive数据库一样可行。
hive : 元数据,是存放在mysql中,然后真正的数据是存放在hdfs中。
2 安装mysql
mysql数据库作为hive使用的元数据
3 配置HiveOnSpark
生成hive的元数据库表,根据hive的配置文件,生成对应的元数据库表。
spark-sql 是spark专门用于编写sql的交互式命令行。
当直接启动spark-sql以local模式运行时,如果报错:

是因为配置了Hadoop的配置参数导致的:
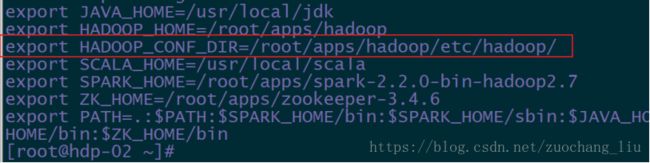
执行测试命令:
create table test (name string);
insert into test values(“xxtest”);
![]()
local模式下,默认使用derby数据库,数据存储于本地位置。
要想使用hive的标准,需要把hive的配置文件放到spark的conf目录下
cd /root/apps/spark-2.2.0-bin-hadoop2.7/conf/
vi hive-site.xml
hive-site.xml文件:
javax.jdo.option.ConnectionURL
jdbc:mysql://hdp-01:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
123456
password to use against metastore database
把该配置文件,发送给集群中的其他节点:
cd /root/apps/spark-2.2.0-bin-hadoop2.7/conf/
for i in 2 3 ;do scp hive-site.xml hdp-0$i:`pwd` ;done
重新停止并重启spark: start-all.sh
启动spark-sql时,
出现如下错误是因为操作mysql时缺少mysql的驱动jar包,
解决方案1:--jars 或者 --driver-class-path 引入msyql的jar包
解决方案2: 把mysql的jar包添加到$spark_home/jars目录下

启动时指定集群:(如果不指定master,默认就是local模式)
spark-sql --master spark://hdp-01:7077 --jars /root/mysql-connector-java-5.1.38.jar
sparkSQL会在mysql上创建一个database,需要手动改一下DBS表中的DB_LOCATION_UIR改成hdfs的地址
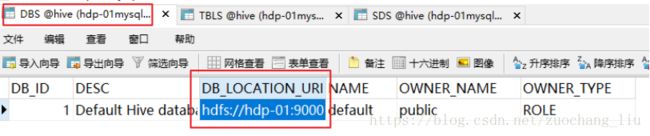
hdfs://hdp-01:9000/user/hive/spark-warehouse
也需要查看一下,自己创建的数据库表的存储路径是否是hdfs的目录。

执行spark-sql任务之后:可以在集群的监控界面查看

同样 ,会有SparkSubmit进程存在。
4 IDEA编程
要先开启spark对hive的支持
//如果想让hive运行在spark上,一定要开启spark对hive的支持
val session = SparkSession.builder()
.master("local")
.appName("xx")
.enableHiveSupport() // 启动对hive的支持, 还需添加支持jar包
.getOrCreate()要添加spark对hive的兼容jar包
org.apache.spark
spark-hive_2.11
${spark.version}
在本地运行,还需把hive-site.xml文件拷贝到resource目录下。
resources目录,存放着当前项目的配置文件
编写代码,local模式下测试:
// 执行查询
val query = session.sql("select * from t_access_times")
query.show()
// 释放资源
session.close()创建表的时候,需要伪装客户端身份
System.setProperty("HADOOP_USER_NAME", "root") // 伪装客户端的用户身份为root
// 或者添加运行参数 –DHADOOP_USER_NAME=root
基本操作
// 求每个用户的每月总金额
// session.sql("select username,month,sum(salary) as salary from t_access_times group by username,month")
// 创建表
// session.sql("create table t_access1(username string,month string,salary int) row format delimited fields terminated by ','")
// 删除表
// session.sql("drop table t_access1")
// 插入数据
// session.sql("insert into t_access1 select * from t_access_times")
// .show()
// 覆盖写数据
// session.sql("insert overwrite table t_access1 select * from t_access_times where username='A'")
// 覆盖load新数据
// C,2015-01,10
// C,2015-01,20
// session.sql("load data local inpath 't_access_time_log' overwrite into table t_access1")
// 清空数据
// session.sql("truncate table t_access1")
// .show()
// 写入自定义数据
val access: Dataset[String] = session.createDataset(List("b,2015-01,10", "c,2015-02,20"))
val accessdf = access.map({
t =>
val lines = t.split(",")
(lines(0), lines(1), lines(2).toInt)
}).toDF("username", "month", "salary")
// .show()
accessdf.createTempView("t_ac")
// session.sql("insert into t_access1 select * from t_ac")
// overwrite模式会重新创建新的表 根据指定schema信息 SaveMode.Overwrite
// 本地模式只支持 overwrite,必须在sparksession上添加配置参数:
// .config("spark.sql.warehouse.dir", "hdfs://hdp-01:9000/user/hive/warehouse")
accessdf
.write.mode("overwrite").saveAsTable("t_access1")
集群运行:
需要把hive-site.xml配置文件,添加到$SPARK_HOME/conf目录中去,重启spark
上传一个mysql连接驱动(sparkSubmit也要连接MySQL,获取元数据信息)
spark-sql --master spark://hdp-01:7077 --driver-class-path /root/mysql-connector-java-5.1.38.jar
--class xx.jar
然后执行代码的编写:
// 执行查询 hive的数据表
// session.sql("select * from t_access_times")
// .show()
// 创建表
// session.sql("create table t_access1(username string,month string,salary int) row format delimited fields terminated by ','")
// session.sql("insert into t_access1 select * from t_access_times")
// .show()
// 写数据
val access: Dataset[String] = session.createDataset(List("b,2015-01,10", "c,2015-02,20"))
val accessdf = access.map({
t =>
val lines = t.split(",")
(lines(0), lines(1), lines(2).toInt)
}).toDF("username", "month", "salary")
accessdf.createTempView("v_tmp")
// 插入数据
// session.sql("insert overwrite table t_access1 select * from v_tmp")
session.sql("insert into t_access1 select * from v_tmp")
// .show()
// insertInto的api 入库
accessdf.write.insertInto("databaseName.tableName")
session.close()5 sparksql连接方式
5.1 交互式的命令行
![]()
spark-sql 本地模式运行
spark-sql --master spark://hdp-01:7077 集群模式运行
如果没有hive-site.xml文件,spark-sql 默认使用的是derby数据库,数据写在执行命令的当前目录(spark-warehouse)。

如果有hive-site.xml ,才能实现,元数据用mysql管理,数据存储在HDFS中
5.2 jdbc的连接方式
在服务端修改配置文件hive-site.xml
hive.server2.thrift.bind.host
hdp-03
Bind host on which to run the HiveServer2 Thrift service.
hive.server2.thrift.port
10000
Port number of HiveServer2 Thrift interface when hive.server2.transport.mo de is 'binary'.
启动服务端
![]()
服务端的进程是SparkSubmit:

启动客户端:
