python中用xpath解析网页的基本方法
1. 背景
- 目前爬虫解析网页的技术有:Json, 正则表达式,BeautifulSoup,PyQuery,XPath
- XPath 教程 官方文档:
http://www.w3school.com.cn/xpath/index.asp
2. XPath简述
2.1. 什么是XPath?
- XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
2.2. XPath 开发工具
1.开源的XPath表达式编辑工具: XMLQuire(XML格式文件可用)
2.Chrome插件 XPath Helper
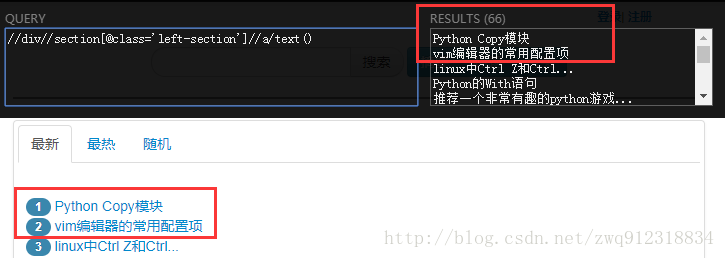
3.Firefox插件 XPath Checker
2.3. XPath语法的解析库 —— lxml库
- lxml 是一个HTML/XML的解析器,主要的功能是解析和提取 HTML/XML 数据,我们可以利用XPath语法,来快速的定位特定元素以及节点信息。
- lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器。
- lxml python 官方文档: http://lxml.de/index.html
- 安装lxml库:需要安装C语言库,可使用 pip 安装:pip install lxml (或通过wheel方式安装)
3. 什么是XML?
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 的标签需要我们自行定义。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
- XML 官方文档:http://www.w3school.com.cn/xml/index.asp
3.1. XML 和 HTML 的区别
| 数据格式 | 描述 | 设计目标 |
|---|---|---|
| XML | Extensible Markup Language (可扩展标记语言) | 被设计为传输和存储数据,其焦点是数据的内容。 |
| HTML | HyperText Markup Language (超文本标记语言) | 显示数据以及如何更好显示数据。 |
| HTML DOM | Document Object Model for HTML (文档对象模型) | 通过 HTML DOM,可以访问所有的 HTML 元素,连同它们所包含的文本和属性。可以对其中的内容进行修改和删除,同时也可以创建新的元素。 |
3.2. XML文档示例
- 可以在 http://www.w3school.com.cn/example/xmle_examples.asp 找到很多XML文档示例。
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italiantitle>
<author>Giada De Laurentiisauthor>
<year>2005year>
<price>30.00price>
book>
<book category="children">
<title lang="en">Harry Pottertitle>
<author>J K. Rowlingauthor>
<year>2005year>
<price>29.99price>
book>
<book category="web">
<title lang="en">XQuery Kick Starttitle>
<author>James McGovernauthor>
<author>Per Bothnerauthor>
<author>Kurt Cagleauthor>
<author>James Linnauthor>
<author>Vaidyanathan Nagarajanauthor>
<year>2003year>
<price>49.99price>
book>
<book category="web" cover="paperback">
<title lang="en">Learning XMLtitle>
<author>Erik T. Rayauthor>
<year>2003year>
<price>39.95price>
book>
bookstore>3.3. HTML DOM 结构
- HTML DOM 定义了访问和操作 HTML 文档的标准方法。DOM 将 HTML 文档表达为树结构。
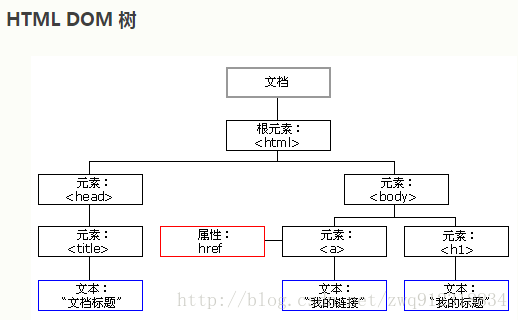
3.4. XML的节点关系
3.4.1. 约定

3.4.2. 关系
父(Parent):
- 每个元素以及属性都有一个父。
- 上图中book元素 是 title,author(多个),year , price 元素的父辈。
子(Children):
- 元素节点可有零个、一个或多个孩子元素。
- 上图中,title,author,year,price元素都是 book元素的子:
兄弟(Sibling):
- 上图中,title,author,year,price元素都是兄弟。
祖先(Ancestor):
- 某节点的父辈、父辈的父辈,往上递推。
- 上图中,title元素的祖先是 book元素。
后代(Descendant):
- 某节点的子,子的子,往后递推。
- 上图中,book元素的后代是title元素。
4. XPath基本语法
# http://blog.csdn.net/zheng12tian/article/details/40617303
# XPath 基础表达式:
/node 表示在xml文档的根目录查找结点名称为node的结点
./node 表示在当前结点下查找结点名称为node的结点
//node 表示在xml文档中递归查找结点名称为node的节点
//* 表示在xml文档中查询所有的结点,但是排除文本节点
//node() 表示在xml文档中查询所有结点,包含文本节点
//text() 表示在xml文档中递归查找所有的文本节点
//*/text()[contains(., 'test')] 表示在xml文档中递归查找所有结点,条件为该结点的文本节点包含"test"
//node[@id] 表示在xml文档中递归查找结点名称为node的结点,条件为该结点必须含有id属性
//node[id] 表示在xml文档中递归查找结点名称为node的结点,条件为该结点必须含有结点名称为id的结点
//nodes[node/id] 表示递归查找nodes结点,条件为nodes结点下必须有node结点,且node结点下必须有id结点
//nodes[@id]/node[id] 表示递归查找含有id属性的nodes结点下的node结点,条件为node结点下必须含有id结点
//nodes[@id]/node[0] 表示递归查找含有id属性的nodes结点下的第一个node结点
//nodes[@id]/node[last()] 表示递归查找含有id属性的nodes结点下的最后一个node结点
//nodes/node[position() < 4] 表示递归查找nodes结点下索引小于4的node结点
//nodes[@id]/node[position() < last()] 递归查找含有id属性的nodes结点下除最后一个结点外的node结点
/nodes/child::node()[name()='node'] 表示查找nodes结点下结点名称为node的子结点
/nodes/child::node 等同于/nodes/node表示查找nodes下的node子结点
/nodes/node/attribute::id 等同于/nodes/node/@id表示查找nodes结点下的node结点的id属性
//nodes[@id='1001']/node[starts-with(@id, '1')] 表示查找id属性为1001的nodes结点下的id属性以1开头的node结点
//@*[ends-with(., '1')] 表示查找以1结尾所有属性
(//* | //@*)[substring(name(), 1, 5) = 'class'] 查找所有结点名称或属性名称的1到5之间的字符等于'class'的结点
//node[@attr!='-2' and @attr!='2'] 查找所有node节点,其attr属性不等于2和-2
# XPath 文档轴用途:
self 选择当前节点
parent 选择当前节点的父节点
child 选择当前节点的所有子节点
attribute 选择当前节点的所有属性
ancestor 选择当前节点的所有祖先,包括父节点、父节点的父节点等等
ancestor-or-self 选择当前节点的祖先以及当前节点本身
descendant 选择当前节点的所有后代,包括子节点、子节点的子节点等等
descendant-or-self 选择当前节点的后代以及当前节点本身
preceding 选择整个文档中出现在当前节点前面的所有节点
preceding-sibling 选择文档中出现在当前节点前面的所有同胞节点(即与当前节点同级的节点)
following 选择整个文档中出现在当前节点后面的所有节点
following-sibling 选择文档中出现在当前节点后面的所有同胞节点(即与当前节点同级的节点)
namespace 选择当前节点的所有名称空间节点5. 一些实际案例
5.1. 寻找页面通用地址,进行翻页
![]()
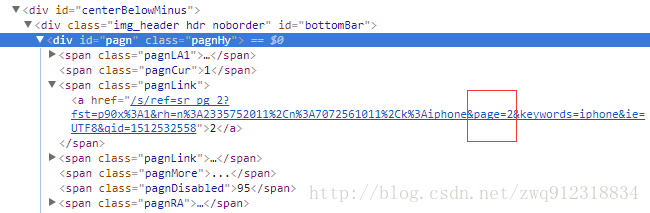
def parseResponse(self, response):
pageUrl = response.xpath('//*[@id="pagn"]//a/@href').extract_first(default = '')
# 去掉不必要的内容,以便达到更好的去重效果
followUrl = re.sub(r'&qid=.+&spIA=.+', '', pageUrl, count=1)
# numberRes = ['1', '2', '3', '95']
numberRes = response.xpath('string(//*[@id="pagn"])').re(r'\d+') # numberRes 重要,所以要确保正确得到总页数
for page in range(1, int(numberRes [-1]) + 1):
yield response.follow(
# 按照page值构造其他页链接
url = re.sub(r'page=\d+', f'page={page}', followUrl, count = 1),
meta = {'dont_redirect': True},
callback = self.parseNextPage,
errback = self.error
)5.2. 结合re使用


# 获取搜索结果数
countRes = response.xpath('//*[@id="s-result-count"]/text()').re_first(r'[0-9,]+ of ([0-9,]+)', '0').replace(',', '')
count = int(countRes)
# count = 16995.3. 寻找相似性,利用starts-with用法全部提取
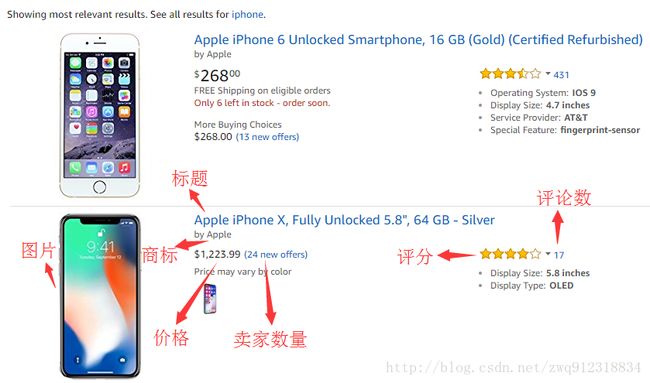
- 所有商品列表
# 全部以相同的字符result_开始
# 解决方法: 用starts-with(@属性名称, 属性相同的部分)
liRes = response.xpath('//li[starts-with(@id,"result_")]')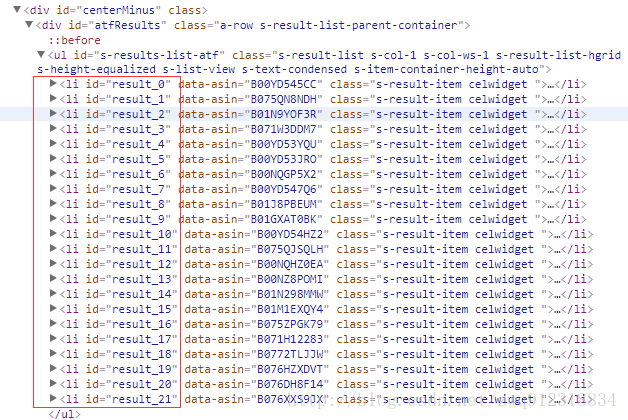
- 标题
title = listElem.xpath('.//a[@title]/@title').extract_first()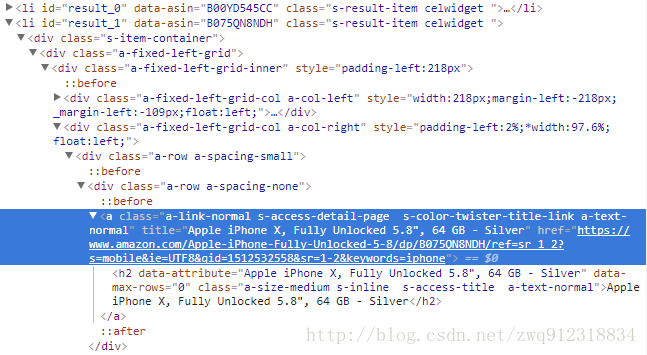
- 评分
avgStar = listElem.xpath('string(//*[@name=$val])', val = asin).extract_first(default='0')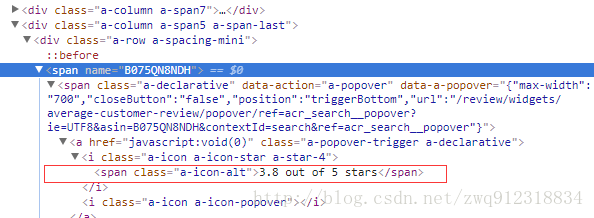
- 评论数
totalReviews = listElem.xpath('//*[@name=$val]/following-sibling::a/text()', val = asin).extract_first(default='0')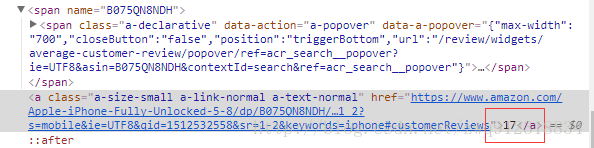
- 价格
price = listElem.xpath('.//span[@aria-label]/@aria-label | .//span[contains(.,"$")]/text()').extract_first(default='0')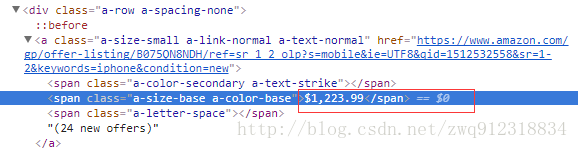
- 商标:brand,直接通过chrome工具解析出来
brand = listElem.xpath('string(div/div/div/div[2]/div[last()-1]/div[2])').extract_first(default='')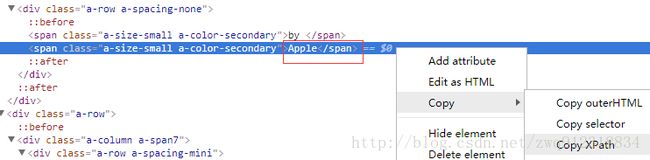
- 搜索结果序号
resultID = int(listElem.xpath('@id').re_first(r'result_(\d+)'))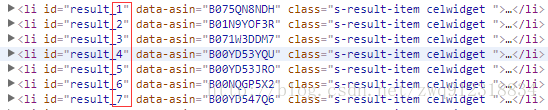
- 图片链接
image_url = listElem.xpath('.//img/@src').extract_first()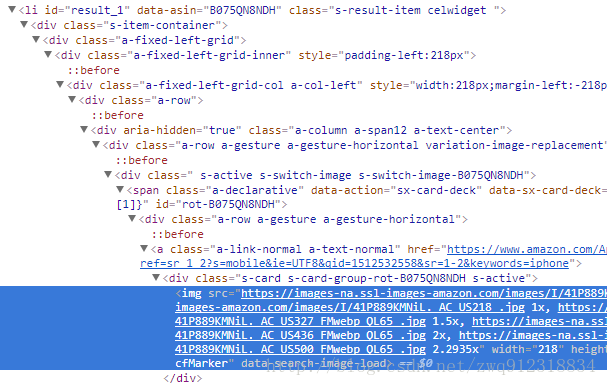
- 卖家总数
listElem.xpath('.//*[contains(.,"offer")]//text()').extract()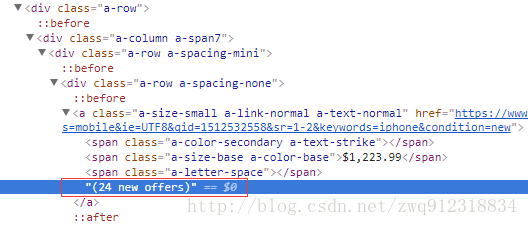
# 获取搜索列表下,每个商品的唯一标识号,标题
liRes = response.xpath('//li[starts-with(@id,"result_")]')
if liRes:
for listElem in liRes:
# 商品唯一标识号
# It returns None if no element was found
asin = listElem.xpath('@data-asin').extract_first()
# 标题
title = listElem.xpath('.//a[@title]/@title').extract_first()
# 评分
avgStar = listElem.xpath('string(//*[@name=$val])', val = asin).extract_first(default='0')
# 评论数
totalReviews = listElem.xpath('//*[@name=$val]/following-sibling::a/text()', val = asin).extract_first(default='0')
# 价格, contains(.,"$")中的.代表text
price = listElem.xpath('.//span[@aria-label]/@aria-label | .//span[contains(.,"$")]/text()').extract_first(default='0')
# 商标,chrome工具的结果是://*[@id="result_1"]/div/div/div/div[2]/div[1]/div[2]/span[2]
# 然后进行改造
brand = listElem.xpath('string(div/div/div/div[2]/div[last()-1]/div[2])').extract_first(default='')
# 搜索结果序号
resultID = int(listElem.xpath('@id').re_first(r'result_(\d+)'))
# 图片链接
image_url = listElem.xpath('.//img/@src').extract_first()
# 卖家总数
sellerNum = 0
for eachOfferText in listElem.xpath('.//*[contains(.,"offer")]//text()').extract():
result = re.findall(r'(\d+)\s.*?offer', eachOfferText)
if result:
sellerNum = sum(int(num) for num in result)5.4. 利用string(.)获取某个标签下连续的一句话
# 标签套标签,一句话分散在几个标签中,如何提取成一句完整的话?
# 解决方法: string(.)
from lxml import etree
html = '''
我左青龙,
右白虎,
上朱雀,
- 下玄武.
老牛在当中,
龙头在胸口.
'''
selector = etree.HTML(html)
data = selector.xpath('//div[@id="class3"]')[0]
allText = data.xpath('string(.)') # 实际上是去除了div中间的其他标签
print(f"allText = {allText}")
textRes = allText.replace('\n', '').replace(' ', '')
print(f"textRes = {textRes}")
# 输出结果:
allText =
我左青龙,
右白虎,
上朱雀,
下玄武.
老牛在当中,
龙头在胸口.
textRes = 我左青龙,右白虎,上朱雀,下玄武.老牛在当中,龙头在胸口.5.5. 价格:文本模糊匹配,并利用上下文关系获取信息
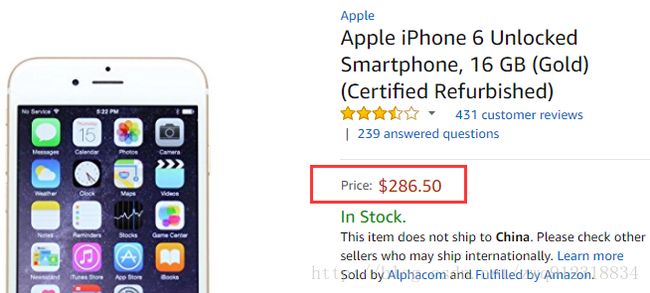
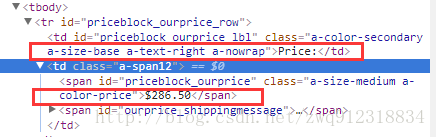
# --- 价格 price1 : with deal or sale or price
# 发现价格的数据紧跟在这几个字串后面
priceInfoRes = response.xpath("//div[@id='price']//text()").extract()
priceInfoResLst = []
for priceInfo in priceInfoRes:
priceInfoStripLower = priceInfo.strip().lower()
if priceInfoStripLower != '':
priceInfoResLst.append(priceInfoStripLower)
priceIdx = 0
# elemIdx = 0
for elemIdx in range(0, len(priceInfoResLst)):
elem = priceInfoResLst[elemIdx].strip().lower()
if (elem == 'sale:') or (elem == 'with deal:') or (elem == 'price:'):
priceIdx = elemIdx + 1
break
if (priceIdx != 0) and (priceIdx < len(priceInfoResLst)):
price1 = priceInfoResLst[priceIdx].strip()
else:
price1 = ''
if price1 != '':
# 处理价格:price = $64.32'
priceRe = re.search(r'([\d\.]+)', price1)
priceFloat = float(priceRe.group(1)) if priceRe else 0.0
detailParseResults['price1'] = priceFloat
else:
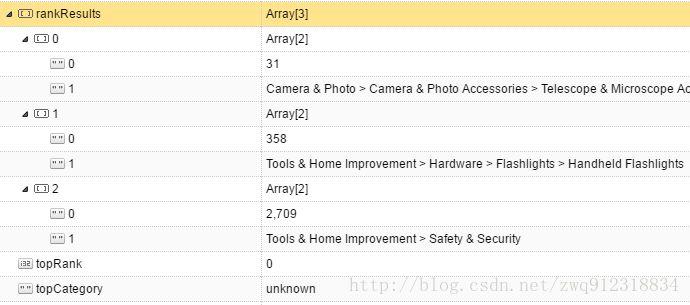
detailParseResults['price1'] = 0.05.6. 模糊匹配,以及特征提取
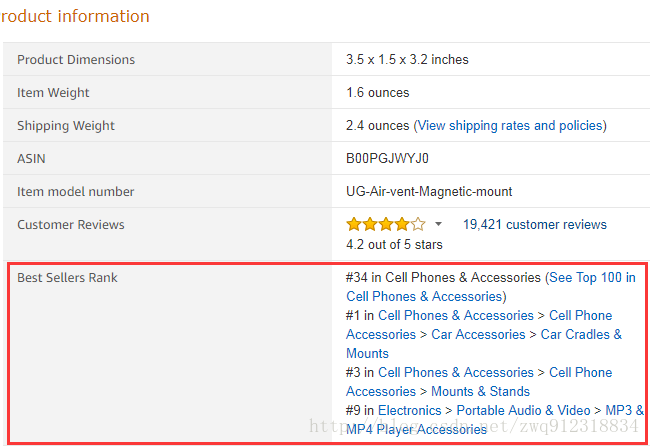

item = {}
#--- 解析小品类信息category:
unicorn = response.xpath('string(//*[contains(.,"Best Sellers Rank")])').extract_first(default='')
rankResults = re.findall(r'#([0-9,]+)\s+in\s+(.+)[^\.#]\s', unicorn)
isHasRank = False
# 解析topRank和 topCategory信息
topRank = 0
topCategory = 'unknown'
if len(rankResults) > 0:
# 说明是大品类信息
if rankResults[0][1].find(' > ') == -1:
topRank = int(rankResults[0][0].replace(',', '').strip())
categoryLst = rankResults[0][1].split('>')
topCategory = reCategory = ''
if len(categoryLst) > 0:
reCategory = re.search(r"(.*?)\(", categoryLst[-1])
if not reCategory:
reCategory = categoryLst[-1]
else:
reCategory = reCategory.group(1)
topCategory = reCategory.strip()
if isHasRank == True:
startIndex = 1
else:
startIndex = 0
item['topRank'] = topRank
item['topCategory'] = topCategory
smallCategoryIndex = 1
for i in range(startIndex, len(rankResults)):
item[f"rank{smallCategoryIndex}"] = int(rankResults[i][0].replace(',', '').strip())
smallCategoryLst = rankResults[i][1].split('>')
smallCategory = reSmallCategory = ''
if len(smallCategoryLst) > 0:
reSmallCategory = re.search(r"(.*?)\(", smallCategoryLst[-1])
if not reSmallCategory:
reSmallCategory = smallCategoryLst[-1]
else:
reSmallCategory = reSmallCategory.group(1)
smallCategory = reSmallCategory.strip()
item[f"category{smallCategoryIndex}"] = smallCategory
smallCategoryIndex += 1- 解析结果

5.7. 筛选属性的组合操作
# 属性的联合操作
price = response.xpath('//*[@id="priceblock_ourprice" or @id="priceblock_saleprice"]/text()').extract_first(default = '0')
title = response.xpath('string(//*[@id="productTitle" or contains(@class,"product-title")])').extract_first()