[深度学习] 分布式模式介绍(一)
[深度学习] 分布式模式介绍(一)
[深度学习] 分布式Tensorflow介绍(二)
[深度学习] 分布式Pytorch 1.0介绍(三)
[深度学习] 分布式Horovod介绍(四)
一 分布式训练策略
数据较多或者模型较大时,为提高机器学习模型训练效率,一般采用多GPU的分布式训练。
按照并行方式,分布式训练一般分为数据并行和模型并行两种, 模型并行:分布式系统中的不同GPU负责网络模型的不同部分。例如,神经网络模型的不同网络层被分配到不同的GPU,或者同一层内部的不同参数被分配到不同GPU;
数据并行:不同的GPU有同一个模型的多个副本,每个GPU分配到不同的数据,然后将所有GPU的计算结果按照某种方式合并。
注意,上述中的不用GPU可以是同一台机上的多个GPU,也可以是不用机上的GPU。
![[深度学习] 分布式模式介绍(一)_第1张图片](http://img.e-com-net.com/image/info8/3dd6e54b892f49cc85a949471a8c8fd6.jpg)
当然也有数据并行和模型并行的混合模式
![[深度学习] 分布式模式介绍(一)_第2张图片](http://img.e-com-net.com/image/info8/9098d62976514c529ffd24f6b3ef580c.jpg)
因为模型并行各个部分存在一定的依赖,规模伸缩性差(意思是不能随意增加GPU的数量),在实际训练中用的不多。而数据并行,则各部分独立,规模伸缩性好,实际训练中更为常用,提速效果也更好。
数据并行会涉及到各个GPU之间同步模型参数,一般分为同步更新和异步更新。同步更新要等到所有GPU的梯度计算完成,再统一计算新权值,然后所有GPU同步新值后,才进行下一轮计算。异步更新,每个GPU梯度计算完后,无需等待其他GPU的梯度计算(有时可以设置需要等待的梯度个数),可立即更新整体权值,然后同步此权值,即可进行下一轮计算。同步更新有等待,异步更新基本没有等待,但异步更新涉及到梯度过时等更复杂问题。
1.模型并行
所谓模型并行指的是将模型部署到很多设备上(设备可能分布在不同机器上,下同)运行,比如多个机器的GPUs。当神经网络模型很大时,由于显存限制,它是难以在跑在单个GPU上,这个时候就需要模型并行。比如Google的神经机器翻译系统,其可能采用深度LSTM模型,如下图所示,此时模型的不同部分需要分散到许多设备上进行并行训练。深度学习模型一般包含很多层,如果要采用模型并行策略,一般需要将不同的层运行在不同的设备上,但是实际上层与层之间的运行是存在约束的:前向运算时,后面的层需要等待前面层的输出作为输入,而在反向传播时,前面的层又要受限于后面层的计算结果。所以除非模型本身很大,一般不会采用模型并行,因为模型层与层之间存在串行逻辑。但是如果模型本身存在一些可以并行的单元,那么也是可以利用模型并行来提升训练速度,比如GoogLeNet的Inception模块。
![[深度学习] 分布式模式介绍(一)_第3张图片](http://img.e-com-net.com/image/info8/625244d6c21c404e9b47ac9c240e387e.jpg)
2.数据并行
深度学习模型最常采用的分布式训练策略是数据并行,因为训练费时的一个重要原因是训练数据量很大。数据并行就是在很多设备上放置相同的模型,并且各个设备采用不同的训练样本对模型训练。训练深度学习模型常采用的是batch SGD方法,采用数据并行,可以每个设备都训练不同的batch,然后收集这些梯度用于模型参数更新。前面所说的Facebook训练Resnet50就是采用数据并行策略,使用256个GPUs,每个GPU读取32个图片进行训练,如下图所示,这样相当于采用非常大的batch(256 × 32 = 8192)来训练模型。
![[深度学习] 分布式模式介绍(一)_第4张图片](http://img.e-com-net.com/image/info8/3d8a63ff12d34ef5ac9db2ad0d12eb9c.jpg)
数据并行可以是同步的(synchronous),也可以是异步的(asynchronous)。所谓同步指的是所有的设备都是采用相同的模型参数来训练,等待所有设备的mini-batch训练完成后,收集它们的梯度然后取均值,然后执行模型的一次参数更新。这相当于通过聚合很多设备上的mini-batch形成一个很大的batch来训练模型,Facebook就是这样做的,但是他们发现当batch大小增加时,同时线性增加学习速率会取得不错的效果。同步训练看起来很不错,但是实际上需要各个设备的计算能力要均衡,而且要求集群的通信也要均衡,类似于木桶效应,一个拖油瓶会严重拖慢训练进度,所以同步训练方式相对来说训练速度会慢一些。异步训练中,各个设备完成一个mini-batch训练之后,不需要等待其它节点,直接去更新模型的参数,这样总体会训练速度会快很多。但是异步训练的一个很严重的问题是梯度失效问题(stale gradients),刚开始所有设备采用相同的参数来训练,但是异步情况下,某个设备完成一步训练后,可能发现模型参数其实已经被其它设备更新过了,此时这个梯度就过期了,因为现在的模型参数和训练前采用的参数是不一样的。由于梯度失效问题,异步训练虽然速度快,但是可能陷入次优解(sub-optimal training performance)。
异步训练和同步训练在TensorFlow中不同点如下图所示:
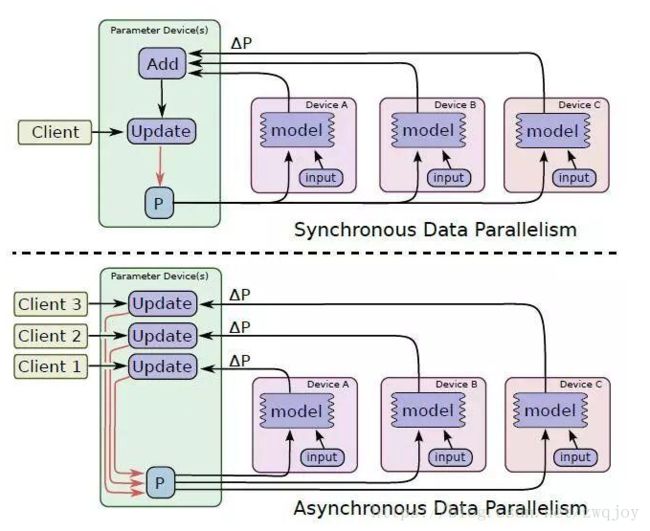
为了解决异步训练出现的梯度失效问题,微软提出了一种Asynchronous Stochastic Gradient Descent方法,主要是通过梯度补偿来提升训练效果。应该还有其他类似的研究,感兴趣的可以深入了解一下。
二 分布式训练系统架构
系统架构层包括两种架构:
Parameter Server Architecture(就是常见的PS架构,参数服务器)
Ring-allreduce Architecture
1.Parameter server架构
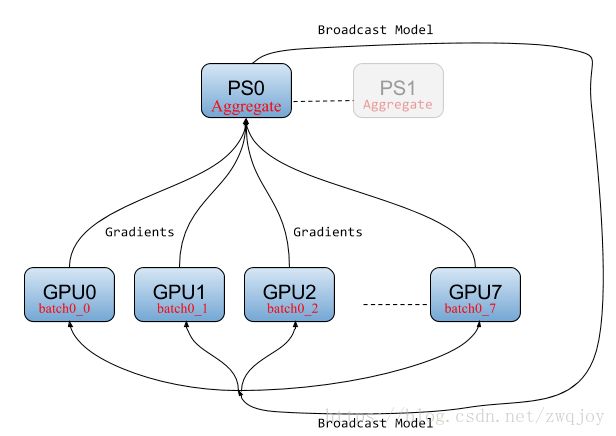
在Parameter server架构(PS架构)中,集群中的节点被分为两类:parameter server和worker。其中parameter server存放模型的参数,而worker负责计算参数的梯度。在每个迭代过程,worker从parameter sever中获得参数,然后将计算的梯度返回给parameter server,parameter server聚合从worker传回的梯度,然后更新参数,并将新的参数广播给worker。
PS架构是深度学习最常采用的分布式训练架构。采用同步SGD方式的PS架构如下图所示:
2.Ring-allreduce架构
在Ring-allreduce架构中,各个设备都是worker,并且形成一个环,如下图所示,没有中心节点来聚合所有worker计算的梯度。在一个迭代过程,每个worker完成自己的mini-batch训练,计算出梯度,并将梯度传递给环中的下一个worker,同时它也接收从上一个worker的梯度。对于一个包含N个worker的环,各个worker需要收到其它N-1个worker的梯度后就可以更新模型参数。其实这个过程需要两个部分:scatter-reduce和allgather,百度的教程对这个过程给出了详细的图文解释。百度开发了自己的allreduce框架,并将其用在了深度学习的分布式训练中。
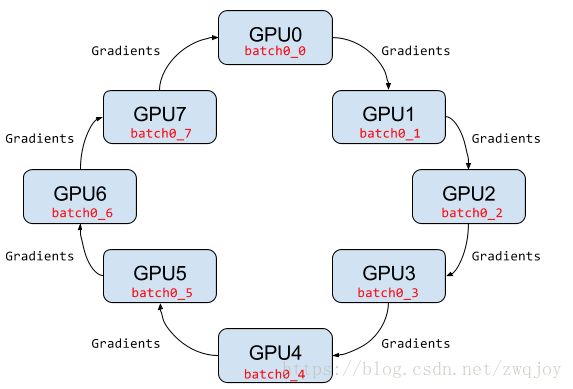
相比PS架构,Ring-allreduce架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。此外,在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。在百度的实验中,他们发现训练速度基本上线性正比于GPUs数目(worker数)。
一般的多卡gpu训练有一个很大的缺陷,就是因为每次都需要一个gpu(cpu)从其他gpu上收集训练的梯度,然后将新的模型分发到其他gpu上。这样的模型最大的缺陷是gpu 0的通信时间是随着gpu卡数的增长而线性增长的。
所以就有了ring-allreduce,如下图:
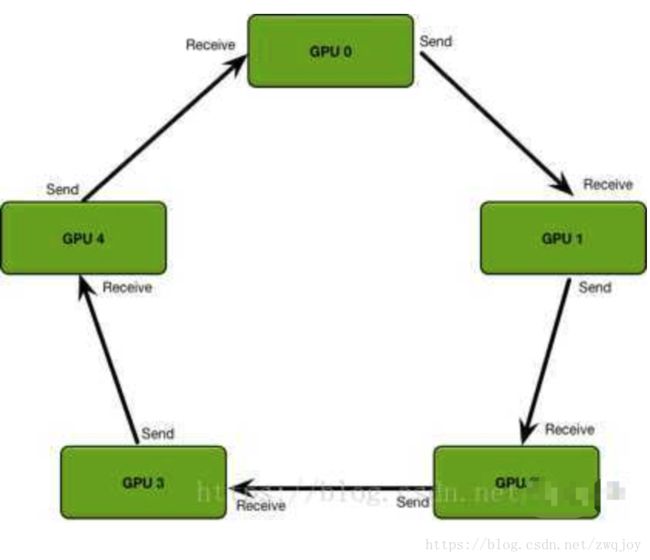
该算法的基本思想是取消Reducer,让数据在gpu形成的环内流动,整个ring-allreduce的过程分为两大步,第一步是scatter-reduce,第二步是allgather。
先说第一步:首先我们有n块gpu,那么我们把每个gpu上的数据(均等的)划分成n块,并给每个gpu指定它的左右邻居(图中0号gpu的左邻居是4号,右邻居是1号,1号gpu的左邻居是0号,右邻居是2号……),然后开始执行n-1次操作,在第i次操作时,gpu j会将自己的第(j - i)%n块数据发送给gpu j+1,并接受gpu j-1的(j - i - 1)%n块数据。并将接受来的数据进行reduce操作,示意图如下:
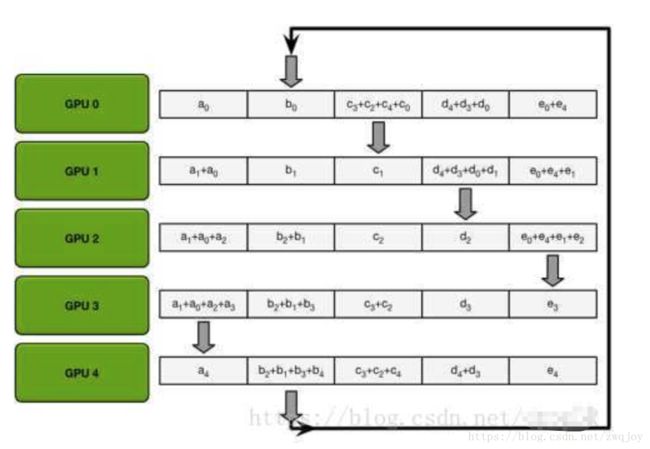
当n-1次操作完成后,ring-allreduce的第一大步scatter-reduce就已经完成了,此时,第i块gpu的第(i + 1) % n块数据已经收集到了所有n块gpu的第(i + 1) % n块数据,那么,再进行一次allgather就可以完成算法了。
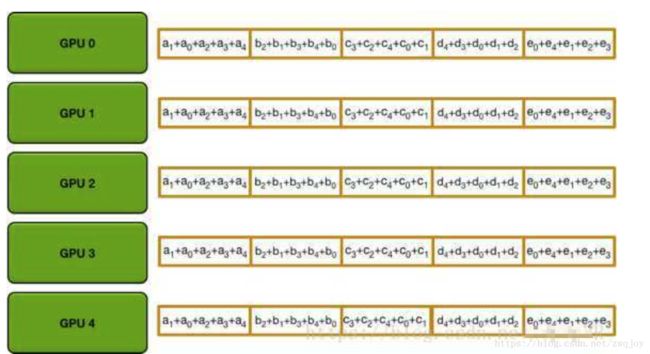
第二步allgather做的事情很简单,就是通过n-1次传递,把第i块gpu的第(i + 1) % n块数据传递给其他gpu,同样也是在i次传递时,gpu j把自己的第(j - i - 1)%n块数据发送给右邻居,接受左邻居的第(j - i - 2) % n数据,但是接受来的数据不需要像第一步那样做reduce,而是直接用接受来的数据代替自己的数据就好了。
最后每个gpu的数据就变成了这样:
首先是第一步,scatter-reduce:

然后是allgather的例子:

链接
https://www.jianshu.com/p/9c462bbb6628
https://www.jianshu.com/p/bf17ac9e6357