[深度学习] 自然语言处理 --- 文本分类模型总结
文本分类
包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMO,BERT等)的文本分类
- fastText 模型
- textCNN 模型
- charCNN 模型
- Bi-LSTM 模型
- Bi-LSTM + Attention 模型
- RCNN 模型
- Adversarial LSTM 模型
- Transformer 模型
- ELMO 预训练模型
- BERT 预训练模型
一 fastText 模型
fastText模型架构和word2vec中的CBOW很相似, 不同之处是fastText预测标签而CBOW预测的是中间词,即模型架构类似但是模型的任务不同。
![[深度学习] 自然语言处理 --- 文本分类模型总结_第1张图片](http://img.e-com-net.com/image/info8/4c40415e40164d3383032815d8b912de.jpg)
![[深度学习] 自然语言处理 --- 文本分类模型总结_第2张图片](http://img.e-com-net.com/image/info8/b2e1eb66907e4a13a1b6e04f0b803459.jpg)
其中x1,x2,...,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。
![[深度学习] 自然语言处理 --- 文本分类模型总结_第3张图片](http://img.e-com-net.com/image/info8/94082eaa07234abab79bb7a8d77a87d7.jpg)
import torch.nn as nn
import torch.nn.functional as F
class FastText(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_dim, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.fc = nn.Linear(embedding_dim, output_dim)
def forward(self, text):
#text = [sent len, batch size]
embedded = self.embedding(text)
#embedded = [sent len, batch size, emb dim]
embedded = embedded.permute(1, 0, 2)
#embedded = [batch size, sent len, emb dim]
pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1)
#pooled = [batch size, embedding_dim]
return self.fc(pooled)
二 TextCNN模型
TextCNN 是利用卷积神经网络对文本进行分类的算法,由 Yoon Kim 在 “Convolutional Neural Networks for Sentence Classification” 一文 中提出. 是2014年的算法.
将Text的词向量拼接在一起,就好比一张图,只不过这个图只是一个channel的.这里使用的就是Conv1d.
模型的结构是:
- Embedding layer
- Convolutional layer:可以用不同尺度的filter产生多个feature map
- MaxPooling Layer
- Feedfoward layer
- Softmax Layer
![[深度学习] 自然语言处理 --- 文本分类模型总结_第4张图片](http://img.e-com-net.com/image/info8/6588908654224e3284a089b6da36d7f6.jpg)
class CNN1d(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,
dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)
self.convs = nn.ModuleList([
nn.Conv1d(in_channels = embedding_dim,
out_channels = n_filters,
kernel_size = fs)
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
#text = [sent len, batch size]
text = text.permute(1, 0)
#text = [batch size, sent len]
embedded = self.embedding(text)
#embedded = [batch size, sent len, emb dim]
embedded = embedded.permute(0, 2, 1)
#embedded = [batch size, emb dim, sent len]
conved = [F.relu(conv(embedded)) for conv in self.convs]
#conved_n = [batch size, n_filters, sent len - filter_sizes[n] + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
#pooled_n = [batch size, n_filters]
cat = self.dropout(torch.cat(pooled, dim = 1))
#cat = [batch size, n_filters * len(filter_sizes)]
return self.fc(cat)三 CharCNN模型
在charCNN论文Character-level Convolutional Networks for Text Classification中提出了6层卷积层 + 3层全连接层的结构,
在此之前很多基于深度学习的模型都是使用更高层面的单元对文本或者语言进行建模,比如单词(统计信息或者 n-grams、word2vec 等),短语(phrases),句子(sentence)层面,或者对语义和语法结构进行分析,但是CharCNN则提出了从字符层面进行文本分类,提取出高层抽象概念。
字符编码层 为了实现 CharCNN,首先要做的就是构建字母表,本文中使用的字母标如下,共有 69 个字符,对其使用 one-hot 编码,外加一个全零向量(用于处理不在该字符表中的字符),所以共 70 个,所以每个字符转化为一个 70 维的向量。文中还提到要反向处理字符编码,即反向读取文本,这样做的好处是最新读入的字符总是在输出开始的地方。:
![[深度学习] 自然语言处理 --- 文本分类模型总结_第5张图片](http://img.e-com-net.com/image/info8/5848628d73644a889d2553564fb57138.jpg)
模型卷积 - 池化层 文中提出了两种规模的神经网络–large 和 small。(kernel——size的不同)都由 6 个卷积层和 3 个全连接层共 9 层神经网络组成。这里使用的是 1-D 卷积神经网络。除此之外,在三个全连接层之间加入两个 dropout 层以实现模型正则化。
![[深度学习] 自然语言处理 --- 文本分类模型总结_第6张图片](http://img.e-com-net.com/image/info8/88b985f1fa7740a5aabfef6e58007b46.jpg)
import torch
from torch import nn
import numpy as np
from utils import *
class CharCNN(nn.Module):
def __init__(self, config, vocab_size, embeddings):
super(CharCNN, self).__init__()
self.config = config
embed_size = vocab_size
# Embedding Layer
self.embeddings = nn.Embedding(vocab_size, embed_size)
self.embeddings.weight = nn.Parameter(embeddings, requires_grad=False)
# This stackoverflow thread explains how conv1d works
# https://stackoverflow.com/questions/46503816/keras-conv1d-layer-parameters-filters-and-kernel-size/46504997
conv1 = nn.Sequential(
nn.Conv1d(in_channels=embed_size, out_channels=self.config.num_channels, kernel_size=7),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3)
) # (batch_size, num_channels, (seq_len-6)/3)
conv2 = nn.Sequential(
nn.Conv1d(in_channels=self.config.num_channels, out_channels=self.config.num_channels, kernel_size=7),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3)
) # (batch_size, num_channels, (seq_len-6-18)/(3*3))
conv3 = nn.Sequential(
nn.Conv1d(in_channels=self.config.num_channels, out_channels=self.config.num_channels, kernel_size=3),
nn.ReLU()
) # (batch_size, num_channels, (seq_len-6-18-18)/(3*3))
conv4 = nn.Sequential(
nn.Conv1d(in_channels=self.config.num_channels, out_channels=self.config.num_channels, kernel_size=3),
nn.ReLU()
) # (batch_size, num_channels, (seq_len-6-18-18-18)/(3*3))
conv5 = nn.Sequential(
nn.Conv1d(in_channels=self.config.num_channels, out_channels=self.config.num_channels, kernel_size=3),
nn.ReLU()
) # (batch_size, num_channels, (seq_len-6-18-18-18-18)/(3*3))
conv6 = nn.Sequential(
nn.Conv1d(in_channels=self.config.num_channels, out_channels=self.config.num_channels, kernel_size=3),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3)
) # (batch_size, num_channels, (seq_len-6-18-18-18-18-18)/(3*3*3))
# Length of output after conv6
conv_output_size = self.config.num_channels * ((self.config.seq_len - 96) // 27)
linear1 = nn.Sequential(
nn.Linear(conv_output_size, self.config.linear_size),
nn.ReLU(),
nn.Dropout(self.config.dropout_keep)
)
linear2 = nn.Sequential(
nn.Linear(self.config.linear_size, self.config.linear_size),
nn.ReLU(),
nn.Dropout(self.config.dropout_keep)
)
linear3 = nn.Sequential(
nn.Linear(self.config.linear_size, self.config.output_size),
nn.Softmax()
)
self.convolutional_layers = nn.Sequential(conv1,conv2,conv3,conv4,conv5,conv6)
self.linear_layers = nn.Sequential(linear1, linear2, linear3)
def forward(self, x):
embedded_sent = self.embeddings(x).permute(1,2,0) # shape=(batch_size,embed_size,seq_len)
conv_out = self.convolutional_layers(embedded_sent)
conv_out = conv_out.view(conv_out.shape[0], -1)
linear_output = self.linear_layers(conv_out)
return linear_output
四 Bi-LSTM模型
Bi-LSTM即双向LSTM,较单向的LSTM,Bi-LSTM能更好地捕获句子中上下文的信息。
![[深度学习] 自然语言处理 --- 文本分类模型总结_第7张图片](http://img.e-com-net.com/image/info8/0e0d736c364b4118b6f7d7ebf288ec0e.jpg)
双向循环神经网络(BRNN)的基本思想是提出每一个训练序列向前和向后分别是两个循环神经网络(RNN),而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。下图展示的是一个沿着时间展开的双向循环神经网络。六个独特的权值在每一个时步被重复的利用,六个权值分别对应:输入到向前和向后隐含层(w1, w3),隐含层到隐含层自己(w2, w5),向前和向后隐含层到输出层(w4, w6)。值得注意的是:向前和向后隐含层之间没有信息流,这保证了展开图是非循环的。
![[深度学习] 自然语言处理 --- 文本分类模型总结_第8张图片](http://img.e-com-net.com/image/info8/761e3ae437be4ab0aaaf5a264ed7a653.jpg)
import torch
from torch import nn
import numpy as np
from utils import *
class TextRNN(nn.Module):
def __init__(self, config, vocab_size, word_embeddings):
super(TextRNN, self).__init__()
self.config = config
# Embedding Layer
self.embeddings = nn.Embedding(vocab_size, self.config.embed_size)
self.embeddings.weight = nn.Parameter(word_embeddings, requires_grad=False)
self.lstm = nn.LSTM(input_size = self.config.embed_size,
hidden_size = self.config.hidden_size,
num_layers = self.config.hidden_layers,
dropout = self.config.dropout_keep,
bidirectional = self.config.bidirectional)
self.dropout = nn.Dropout(self.config.dropout_keep)
# Fully-Connected Layer
self.fc = nn.Linear(
self.config.hidden_size * self.config.hidden_layers * (1+self.config.bidirectional),
self.config.output_size
)
# Softmax non-linearity
self.softmax = nn.Softmax()
def forward(self, x):
# x.shape = (max_sen_len, batch_size)
embedded_sent = self.embeddings(x)
# embedded_sent.shape = (max_sen_len=20, batch_size=64,embed_size=300)
lstm_out, (h_n,c_n) = self.lstm(embedded_sent)
final_feature_map = self.dropout(h_n) # shape=(num_layers * num_directions, 64, hidden_size)
# Convert input to (64, hidden_size * hidden_layers * num_directions) for linear layer
final_feature_map = torch.cat([final_feature_map[i,:,:] for i in range(final_feature_map.shape[0])], dim=1)
final_out = self.fc(final_feature_map)
return self.softmax(final_out)五 Bi-LSTM+Attention 模型
Bi-LSTM + Attention模型来源于论文Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification。关于Attention的介绍见这篇。
Bi-LSTM + Attention 就是在Bi-LSTM的模型上加入Attention层,在Bi-LSTM中我们会用最后一个时序的输出向量 作为特征向量,然后进行softmax分类。Attention是先计算每个时序的权重,然后将所有时序 的向量进行加权和作为特征向量,然后进行softmax分类。在实验中,加上Attention确实对结果有所提升。其模型结构如下图:
![[深度学习] 自然语言处理 --- 文本分类模型总结_第9张图片](http://img.e-com-net.com/image/info8/af9f24e7f2b2461c94f2003050da4463.jpg)
六 RCNN模型
Here, we have implemented Recurrent Convolutional Neural Network model for text classification, as proposed in the paper Recurrent Convolutional Neural Networks for Text Classification.
在文本表示方面,会有超过filter_size的上下文的语义缺失,因此本篇文章利用RNN来进行文本表示,中心词左侧和右侧的词设为trainable,然后将中心词左侧和右侧的词concat作为中心词的表示。 当前step的中心词不输入lstm,仅仅与左侧词和右侧词在lstm的输出concat。
先经过1层双向LSTM,该词的左侧的词正向输入进去得到一个hidden state(从上往下),该词的右侧反向输入进去得到一个hidden state(从下往上)。再结合该词的词向量,生成一个 1 * 3k 的向量。
再经过全连接层,tanh为非线性函数,得到y2。
再经过最大池化层,得出最大化向量y3.
再经过全连接层,sigmod为非线性函数,得到最终的多分类。
1、结合了中心词窗口的输入,其输出的representation能很好的保留上下文语义信息
2、全连接层+pooling进行特征选择,获取全局最重要的特征
![[深度学习] 自然语言处理 --- 文本分类模型总结_第10张图片](http://img.e-com-net.com/image/info8/8d6fa4576edf4f9185b1fb33f051f084.jpg)
RCNN 整体的模型构建流程如下:
1)利用Bi-LSTM获得上下文的信息,类似于语言模型。
2)将Bi-LSTM获得的隐层输出和词向量拼接[fwOutput,wordEmbedding, bwOutput]。
3)将拼接后的向量非线性映射到低维。
4)向量中的每一个位置的值都取所有时序上的最大值,得到最终的特征向量,该过程类似于max-pool。
5)softmax分类。
import torch
from torch import nn
import numpy as np
from torch.nn import functional as F
from utils import *
class RCNN(nn.Module):
def __init__(self, config, vocab_size, word_embeddings):
super(RCNN, self).__init__()
self.config = config
# Embedding Layer
self.embeddings = nn.Embedding(vocab_size, self.config.embed_size)
self.embeddings.weight = nn.Parameter(word_embeddings, requires_grad=False)
# Bi-directional LSTM for RCNN
self.lstm = nn.LSTM(input_size = self.config.embed_size,
hidden_size = self.config.hidden_size,
num_layers = self.config.hidden_layers,
dropout = self.config.dropout_keep,
bidirectional = True)
self.dropout = nn.Dropout(self.config.dropout_keep)
# Linear layer to get "convolution output" to be passed to Pooling Layer
self.W = nn.Linear(
self.config.embed_size + 2*self.config.hidden_size,
self.config.hidden_size_linear
)
# Tanh non-linearity
self.tanh = nn.Tanh()
# Fully-Connected Layer
self.fc = nn.Linear(
self.config.hidden_size_linear,
self.config.output_size
)
# Softmax non-linearity
self.softmax = nn.Softmax()
def forward(self, x):
# x.shape = (seq_len, batch_size)
embedded_sent = self.embeddings(x)
# embedded_sent.shape = (seq_len, batch_size, embed_size)
lstm_out, (h_n,c_n) = self.lstm(embedded_sent)
# lstm_out.shape = (seq_len, batch_size, 2 * hidden_size)
input_features = torch.cat([lstm_out,embedded_sent], 2).permute(1,0,2)
# final_features.shape = (batch_size, seq_len, embed_size + 2*hidden_size)
linear_output = self.tanh(
self.W(input_features)
)
# linear_output.shape = (batch_size, seq_len, hidden_size_linear)
linear_output = linear_output.permute(0,2,1) # Reshaping fot max_pool
max_out_features = F.max_pool1d(linear_output, linear_output.shape[2]).squeeze(2)
# max_out_features.shape = (batch_size, hidden_size_linear)
max_out_features = self.dropout(max_out_features)
final_out = self.fc(max_out_features)
return self.softmax(final_out)
七 Adversarial LSTM模型
模型来源于论文Adversarial Training Methods For Semi-Supervised Text Classification
![[深度学习] 自然语言处理 --- 文本分类模型总结_第11张图片](http://img.e-com-net.com/image/info8/2b63c3ccd69e4b57860dabae663942fe.jpg)
上图中左边为正常的LSTM结构,右图为Adversarial LSTM结构,可以看出在输出时加上了噪声。
Adversarial LSTM的核心思想是通过对word Embedding上添加噪音生成对抗样本,将对抗样本以和原始样本 同样的形式喂给模型,得到一个Adversarial Loss,通过和原始样本的loss相加得到新的损失,通过优化该新 的损失来训练模型,作者认为这种方法能对word embedding加上正则化,避免过拟合。
八 Transformer模型
创新之处在于使用了scaled Dot-Product Attention和Multi-Head Attention
![[深度学习] 自然语言处理 --- 文本分类模型总结_第12张图片](http://img.e-com-net.com/image/info8/cd5756086bc44a328c1c5698a2be5575.jpg)
Encoder部分
![[深度学习] 自然语言处理 --- 文本分类模型总结_第13张图片](http://img.e-com-net.com/image/info8/258f572d6d9c4a37a9c7b1ffb731cfa2.jpg)
上面的Q,K和V,被作为一种抽象的向量,主要目的是用来做计算和辅助attention。根据文章我们知道Attention的计算公式如下:
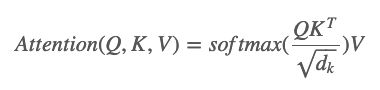
接着是Multi-head Attention:
![[深度学习] 自然语言处理 --- 文本分类模型总结_第14张图片](http://img.e-com-net.com/image/info8/2d894e1ed4a848a1b7605fc3d918c9b1.jpg)
![[深度学习] 自然语言处理 --- 文本分类模型总结_第15张图片](http://img.e-com-net.com/image/info8/4de5bed9d712448bb95aec04453498cb.jpg)
![[深度学习] 自然语言处理 --- 文本分类模型总结_第16张图片](http://img.e-com-net.com/image/info8/cf8b05ac5f0e4daeb6b0e5048ba3804a.jpg)
这里的positional encoding需要说明一下:
![[深度学习] 自然语言处理 --- 文本分类模型总结_第17张图片](http://img.e-com-net.com/image/info8/199e64a137f347e884f5afd57abcc70e.jpg)
公式中pos就代表了位置index,然后i就是index所对应的向量值,是一个标量,然后dmodel就是512了。之所以选择这个函数是因为作者假设它能够让模型通过相关的位置学习Attend。
(引入这个的原因就是因为模型里没有用到RNN和CNN,不能编码序列顺序,因此需要显示的输入位置信息.之前用到的由position embedding,作者发现上述方法与这个方法差不多.位置特征在这里是一种重要特征。)
Decoder部分
对比单个encoder和decoder,可以看出,decoder多出了一个encoder-decoder Attention layer,接收encoder部分输出的向量和decoder自身的self attention出来的向量,然后再进入到全连接的前馈网络中去,最后向量输出到下一个的decoder
![[深度学习] 自然语言处理 --- 文本分类模型总结_第18张图片](http://img.e-com-net.com/image/info8/cbc8e080560c41029452a4c5ba9a4981.jpg)
最后一个decoder输出的向量会经过Linear层和softmax层。Linear层的作用就是对decoder部分出来的向量做映射成一个logits向量,然后softmax层根据这个logits向量,将其转换为了概率值,最后找到概率最大值的位置。这样就完成了解码的输出了。
![[深度学习] 自然语言处理 --- 文本分类模型总结_第19张图片](http://img.e-com-net.com/image/info8/c3f16236492a41939ed410c3aff31387.jpg)
九 ELMO 预训练模型
ELMo模型是利用BiLM(双向语言模型)来预训练词的向量表示,可以根据我们的训练集动态的生成词的向量表示。ELMo预训练模型来源于论文:Deep contextualized word representations。具体的ELMo模型的详细介绍见ELMO模型(Deep contextualized word representation)。
ELMo的模型代码发布在github上,我们在调用ELMo预训练模型时主要使用到bilm中的代码,因此可以将bilm这个文件夹拷贝到自己的项目路径下,之后需要导入这个文件夹中的类和函数。此外,usage_cached.py,usage_character.py,usage_token.py这三个文件中的代码是告诉你该怎么去调用ELMo模型动态的生成词向量。在这里我们使用usage_token.py中的方法,这个计算量相对要小一些。
在使用之前我们还需要去下载已经预训练好的模型参数权重,打开https://allennlp.org/elmo链接,在Pre-trained ELMo Models 这个版块下总共有四个不同版本的模型,可以自己选择,我们在这里选择Small这个规格的模型,总共有两个文件需要下载,一个"options"的json文件,保存了模型的配置参数,另一个是"weights"的hdf5文件,保存了模型的结构和权重值(可以用h5py读取看看)。
十 BERT 预训练模型
BERT 模型来源于论文BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding。BERT模型是谷歌提出的基于双向Transformer构建的语言模型。BERT模型和ELMo有大不同,在之前的预训练模型(包括word2vec,ELMo等)都会生成词向量,这种类别的预训练模型属于domain transfer。而近一两年提出的ULMFiT,GPT,BERT等都属于模型迁移。
BERT 模型是将预训练模型和下游任务模型结合在一起的,也就是说在做下游任务时仍然是用BERT模型,而且天然支持文本分类任务,在做文本分类任务时不需要对模型做修改。谷歌提供了下面七种预训练好的模型文件。
![[深度学习] 自然语言处理 --- 文本分类模型总结_第20张图片](http://img.e-com-net.com/image/info8/7adb53b2395141f2aa0c47c3b731adcb.jpg)
BERT模型在英文数据集上提供了两种大小的模型,Base和Large。Uncased是意味着输入的词都会转变成小写,cased是意味着输入的词会保存其大写(在命名实体识别等项目上需要)。Multilingual是支持多语言的,最后一个是中文预训练模型。