Python爬虫实战爬取租房网站2w+数据-链家上海区域信息(超详细)
Python爬虫实战爬取租房网站-链家上海区域信息(过程超详细)
内容可能有点啰嗦 大佬们请见谅 后面会贴代码 带火们有需求的话就用吧
正好这几天做的实验报告就直接拿过来了,我想后面应该会有人用的到吧.
自己学着分析网址的话链家这个租房网站其他地区的也可以爬大家不妨试试
任务目的:从链家上爬取上海地区的租房信息
1.url分析
https://sh.lianjia.com/zufang/这是网站的首页
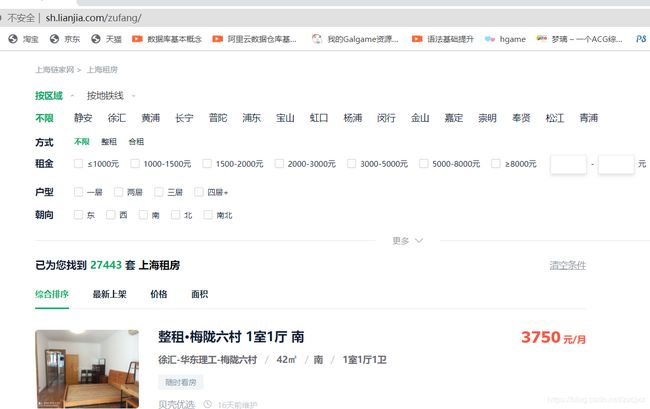
网站的第二页https://sh.lianjia.com/zufang/pg2/#contentList
此时通过对比,可以发现将/pg2/中的2换成1那时网站内容就是第一页的内容,后面的#contentList对网页内容没有影响这里我们就直接删除了。
我这里拿静安区为例
首页网址:https://sh.lianjia.com/zufang/jingan/。第二页: https://sh.lianjia.com/zufang/jingan/pg2/
2.页面元素分析
(1) 使用chrome浏览器的检查功能,点击  左侧的小箭头来分析页面。
左侧的小箭头来分析页面。
我们将鼠标放到第一个房源信息那,可以看到里面的内容都是在content__list—item这个类里面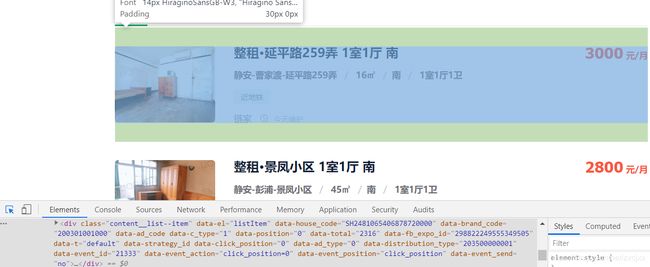
第二个房源的话也是在这个类里面,后面的内容有些不同而已
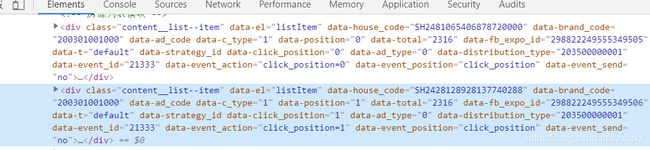
我们往上翻发现这些房源信息都在content__list这个类中
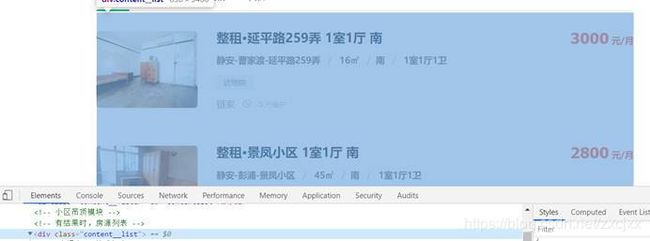
所以我们要的信息从这里面获取就行不需要再从整个页面中查找,先找大标签(这里就是这个content__list),再找其中的小便签。
我们这里把要获取的数据都放入infos里面
infos = soup.find('div',{'class':'content__list'}).find_all('div',{'class':'content__list--item'})`
(2) 分析小标签里要提取的元素;
拿名称来举例,它是在之前找的小便签里的content__list–item–title twoline类的a标签中
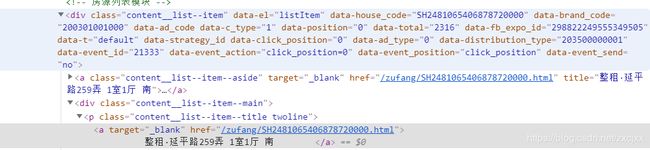
name = info.find('p',
{'class': 'content__list--item--title twoline'}).find(
'a').get_text().strip()
我们只需获取里面的文本信息就行了所以这里我们用到了get_text()函数,strip()用来消除左右空格
当然,我们发现content__list–item–title twoline类是在content__list–item—main里面的,这里我们可以在检查里面用ctrl+f来搜索看看content__list–item—main类里是否有第二个content__list–item–title twoline类,如果重复就要另外分析。这边并没有第二个content__list–item–title twoline类,就不需要考虑了。
(1of30一个页面30个信息还有29个content__list–item–title twoline是下面房子里面的)
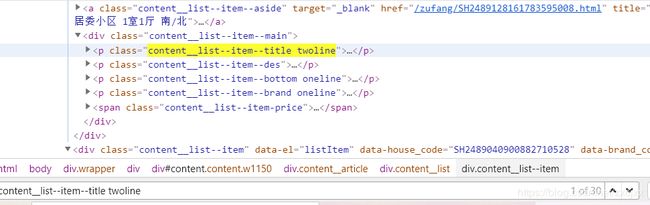
价格这边同样的方法不做赘述
获取具体地址,面积,门朝向以及户型的时候我们发现它是在同一个类里面,它们用’ / '做了分隔。这边我们可以用split()函数来切割,这样就能解决这个问题。
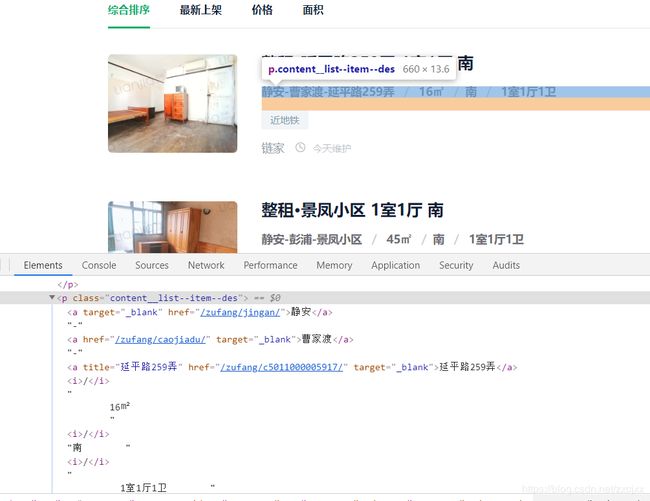
我们将文本放入变量mix中
mix = info.find('p', {'class': 'content__list--item--des'}).get_text()
mix = re.split(r'/', mix)
后面地址,面积,门朝向和房型就很好处理了
area = mix[1].strip()
address = mix[0].strip()
door_orientation = mix[2].strip()
style = mix[3].strip()
地区的话方法类似就不赘述了直接贴代码
region = re.split(r'-', address)[0]
核心代码如下所示:
infos = soup.find('div',{'class':'content__list'}).find_all('div',{'class':'content__list--item'})
# print(infos)
for info in infos:
name = info.find('p',
{'class': 'content__list--item--title twoline'}).find(
'a').get_text().strip()
price = info.find('span',
{'class': 'content__list--item-price'}).get_text()
mix = info.find('p', {'class': 'content__list--item--des'}).get_text()
mix = re.split(r'/', mix)
area = mix[1].strip()
address = mix[0].strip()
door_orientation = mix[2].strip()
style = mix[3].strip()
# advantage = info.find('p',{'class':'content__list--item--bottom oneline'}).get_text()
region = re.split(r'-', address)[0]
3. 逐页爬取
我们要爬取网页关键字搜索返回的所有页面的数据,因此我们需要做逐页爬取,通过定位网页元素中下一页的点击按钮中的url。
拿静安区为例,总共有78页

urls = ['https://sh.lianjia.com/zufang/jingan/pg{}/'.format(str(i)) for i in range(1, 79)]
再加上个for循环就可以访问所有页面了
最后是代码详情(静安区为例):
import requests, time, re, csv
from bs4 import BeautifulSoup
import codecs
with open(r'C:\Users\小阿辰\Desktop\链家上海\静安.csv', 'ab+')as fp:
fp.write(codecs.BOM_UTF8)
f = open(r'C:\Users\小阿辰\Desktop\链家上海\静安.csv','a+',newline='', encoding='utf-8')
writer = csv.writer(f)
writer.writerow(('名称', '租金', '面积', '具体地址', '门朝向', '户型', '地区'))
r'C:\Users\小阿辰\Desktop\链家上海\静安.csv'
urls = ['https://sh.lianjia.com/zufang/jingan/pg{}/'.format(str(i)) for i in range(1, 79)]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36'
}
for url in urls:
res = requests.get(url, headers=headers)
# print(res.text) 网页内容 文本
# print(res.content.decode('utf-8')) #网页内容 二进制
html = res.text
soup = BeautifulSoup(html, 'lxml')
# print(soup)
infos = soup.find('div',{'class':'content__list'}).find_all('div',{'class':'content__list--item'})
# print(infos)
for info in infos:
name = info.find('p',
{'class': 'content__list--item--title twoline'}).find(
'a').get_text().strip()
price = info.find('span',
{'class': 'content__list--item-price'}).get_text()
mix = info.find('p', {'class': 'content__list--item--des'}).get_text()
mix = re.split(r'/', mix)
area = mix[1].strip()
address = mix[0].strip()
door_orientation = mix[2].strip()
style = mix[3].strip()
# advantage = info.find('p',{'class':'content__list--item--bottom oneline'}).get_text()
region = re.split(r'-', address)[0]
writer.writerow((name, price, area, address, door_orientation, style, region))
time.sleep(1)
f.close()
爬取到的数据:
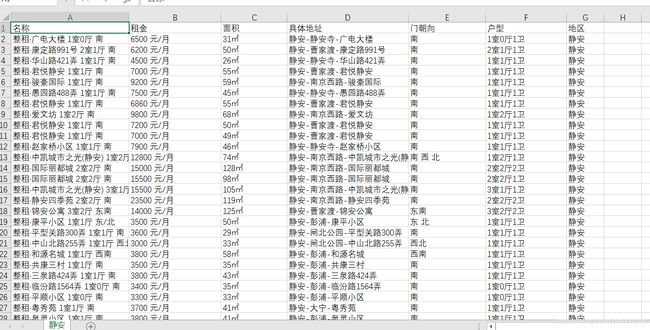
换一下url就可以爬其他区的数据了,我是3.31左右弄的 当时爬各个区得到了大概2.3w条左右的数据 如果有大佬帮我改改的话就再好不过了 我是个萌新 函数都没封装 大家就将就着看看吧。
希望能得到大佬的指教,诶
qq:2798704484