计算歌曲相似度:Jaccard系数
什么是Jaccard系数
其公式如下:
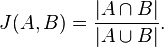
可以看出,其含义是集合A、B中相同的个数,除以A与B交集个数。可以看出,Jaccard系统主要关注的是元素是的个体是否相同,而不能用数值具体表示其差异。从这个意义上讲,我认为适合我的音乐,音乐推荐中计算相似度的过程。因为,我确定两个用户是否相似就是判断这两个用户是否收藏了相同的歌曲。
举例:
A=[shirt,shoes,pants,socks]
B=[shirt,shirt,shoes]
个人认为,这里我们是将其作为集合来看的话,由于集合的互异性,所以B改为:B=[shirt,shoes]
交集:2
并集:4
Jaccard系数为2/4=0.5
可以看出,其含义是集合A、B中相同的个数,除以A与B交集个数。可以看出,Jaccard系统主要关注的是元素是的个体是否相同,而不能用数值具体表示其差异。从这个意义上讲,我认为适合我的音乐,音乐推荐中计算相似度的过程。因为,我确定两个用户是否相似就是判断这两个用户是否收藏了相同的歌曲。
举例:
A=[shirt,shoes,pants,socks]
B=[shirt,shirt,shoes]
个人认为,这里我们是将其作为集合来看的话,由于集合的互异性,所以B改为:B=[shirt,shoes]
交集:2
并集:4
Jaccard系数为2/4=0.5
- 更多内容请看,我之前总结的博客:相似度计算方式的总结:java或python实现代码
java代码
之前只是总结Jaccard系数的python代码,这次我打算总结写出其java代码,并使用java计算,我相信计算速度会快很多。一个简单的计算Jaccard系数的代码如下:
/**
* 计算jaccard系数
* @param userIds1 List是收藏了某一首歌曲用户id集合,是int类型
* @param userIds2 List是收藏了另一首歌曲用户id集合,是int类型
* @return
*/
private static float jaccard(List userIds1, List userIds2) {
float intersectionNum=0;//等下计算Jaccard的时候我们需要产生小数,所以这里直接设置为float算了
Iterator it1 = userIds1.iterator();
Iterator it2 = userIds2.iterator();
while(it1.hasNext()){
int userId1=(int) it1.next();
while(it2.hasNext()){
int userId2=(int) it2.next();
if(userId1==userId2){
intersectionNum++;
}
}
}
float Jaccard=intersectionNum/(userIds1.size()+userIds2.size()-intersectionNum);
return Jaccard;
}哪些歌曲
是由被用户收藏数最多的10000首歌曲。也就是我们数据库中:mostsmallfavorites表内的歌曲。具体来历请看:利用协同过滤算法:计算歌曲相似度
看一下其sql语句能想起很多,如下所示:
CREATE TABLE mostsmallFavorites SELECT *
FROM (
SELECT *
FROM moresmallfavorites, (
SELECT userid AS uid
FROM moresmallfavorites
GROUP BY userid
HAVING COUNT( userid ) >80
AND COUNT( userid ) <500
)a
WHERE moresmallfavorites.userid = a.uid
)b 执行
思路非常简单,无非就是
- 读取所有歌曲id
- 找到每一个歌曲的收藏用户
- 计算某一个歌曲与其他歌曲的相似度
- 相似度排序
- 取出前10位
- 插入数据库
也是使用了一些机制,包括hastable、arraylist这样的容器,具体代码请看源代码。
结果的存储、分析
存储
对于每一首歌曲,我们将保留10首与其相似度最高的歌曲ID和相似度(用0-1之间的数来表示)。结果将会插入到一个表中,我取名为:simmusicjaccard。格式与simmusic一模一样。
sql语句如下:
CREATE TABLE simmusicjaccard(
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY ,
musicid INT,
simmusicid INT,
similarity FLOAT
)分析结果
非常令人震撼,结果单单从相似度的数值的角度来看,非常差,而且这个结果都快到了没有用的地步了,我随机抽查了一个歌曲,找到了其相似度最高和最低的歌曲,进行观察:选择一首歌曲,看其相似度的10首歌曲
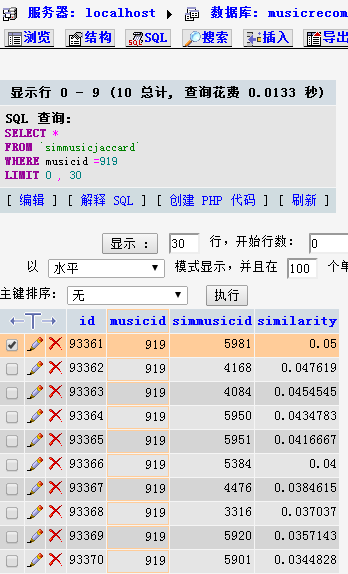
查看其该歌的收藏用户列表:
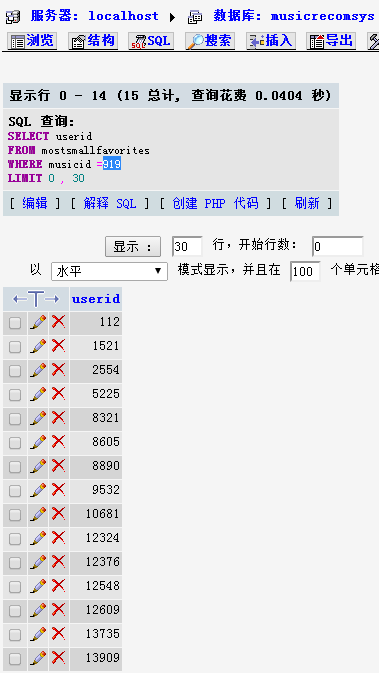
查看与其最相似度的歌曲的用户列表: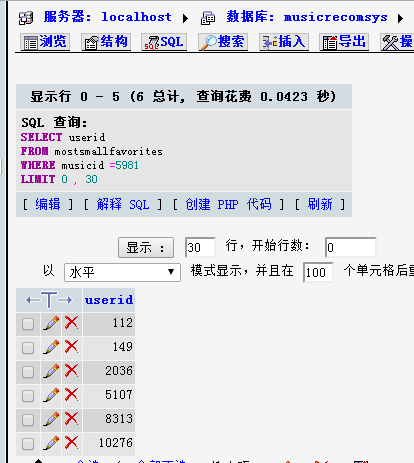
查看与相似度最低的歌曲的用户列表:
有以下现象:
- 无论是相似度最高还是最低的歌曲,都只有一两个用户重合了
- 相似度高的歌曲之所以高,是因为那首歌的用户列表数量少
我认为很
失败。
失败原因
歌曲有一万首,而用户只有1881位(为什么请看mostsmallfavorites的来历):歌曲很显然对于一首歌而言,收藏的其的用户本来就非常少。当计算两首歌的相似度,比较这两首歌的收藏用户时,就会更少。所以才会出现,计算相似度最高的两首歌,他们的用户重合度也只是1首而已。我觉得这个方式根本不适合用来计算歌曲相似度,反而非常适合用于计算用户相似度。因为用户收藏的歌曲非常多,所以产生的歌曲的重合度也想对比较高。
由此,我产生了另一个推荐引擎的思路:
- 给某一个目标用户推荐时,先使用Jaccard系数找到相似度高的用户。
- 选取排名前10的相似度高的用户
- 推荐这10位用户的都收藏的,而目标用户没有收藏的歌曲
- 如果找不到10位都收藏就找9位、8位....逐渐减少相似度最低的用户
- 如果有多个符合条件的歌曲,再用别的办法筛选(比如歌曲相似度、标签)
各类问题总结
与皮尔逊方式计算出的相似度对比
也许还是不能如此片面的观察,我们还是要用实际产生的推荐列表来考察,过程如下,这是之前既定的思路:
- 对比由不同相似度计算出来的歌曲相似度表,
- 再由不同的歌曲相似度表来产生推荐列表,
- 比较推荐列表中出现的我随机删除了的本来就被用户收藏了的歌曲的数量
- 肯定有一种相似度计算公式最优
- 根据原理分析为什么这种相似度方案最优
- 即可产生理论,有了论据
改进该相似度计算公式
质疑一种情况
int song1[]={1,2,3,4};int song2[]={3,4,5,6};
当此种情况使用如下代码计算时:
/**
* 使用Jaccard系数的方式计算歌曲的相似度
* @author chouyou
*
*/
public class Jaccard {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
int song1[]={1,2,3,4};
int song2[]={3,4,5,6};
float intersectionNum=0;//计算Jaccard时需要产生小数,故这里设置为float
int i,j;
for(i=0;i交集个数:2.0
Jaccard系数:0.33333334
质疑改进
在此种情况下:
int song1[]={1,2,3,4};
int song2[]={3,4,5,6};
int song2[]={3,4,5,6};
我认为相似度应该为50%,这是因为两个列表中有50%的用户是相同的。所以我认为应该减去两倍的交集部分。但是当两个列表的长度不同呢?我认为应该选取小的。这是因为如果歌曲A的收藏用户有50位,歌曲B的收藏用户有100位,并且包含歌曲A收藏的50位。我认为歌曲A与歌曲B目前应该是完全相似度应该为100%。只是有50位用户还没听过歌曲A罢了。
对于改进的疑问
歌曲A就被一个用户收藏了,歌曲B被另外100位用户收藏了,也包括收藏歌曲A的用户。难道这样就能说歌曲A与歌曲B的相似度100%吗?肯定不能,所以必须要求歌曲A与歌曲B两者收藏用户数量的差距在一定范围内。比如用户数量都大于10,相差不超过20%。这个可以再考虑。
二维数组的按列排序
后来发现用 treemap更方便,所以没有使用这个方法。
需要一个功能,类似于数据库的order by的功能:
- 将计算出来的相似度和歌曲id储存在一个二维的float数组
- 每一行的第一列存储歌曲相似度,第二列存储歌曲ID
- 然后对二维数组以歌曲的相似度排序由高到低的排序,并且歌曲相似度和歌曲ID对应关系不变
- 参考博客:二维数组排序 【java】
/**
* 使用Jaccard系数的方式计算歌曲的相似度
* @author chouyou
*
*/
public class Jaccard {
/**
* @param args
*/
public static void main(String[] args) {
/**
* 储存与某一首歌相似度最高的10首歌曲
*/
float simSongTop10[][]=new float[3][2];
simSongTop10[0][0]=(float) 0.3;
simSongTop10[0][1]=3;
simSongTop10[1][0]=(float) 0.2;
simSongTop10[1][1]=2;
simSongTop10[2][0]=(float) 0.1;
simSongTop10[2][1]=1;
System.out.print("排序前"+"\n");
for(int i=0;i<3;i++){
System.out.print(simSongTop10[i][0]+" "+simSongTop10[i][1]+"\n");
}
float sortedSimSongTop10[][]=arraySort(simSongTop10,1,false);
System.out.print("排序后"+"\n");
for(int i=0;i<3;i++){
System.out.print(sortedSimSongTop10[i][0]+" "+sortedSimSongTop10[i][1]+"\n");
}
}
/**
* 对一个二维数组进行按某列排序,并且要保证
* @param array 需要排序的数组
* @param row 按第几列进行排序,从1开始
* @param sort true表示降序排列,false表示升序排列
* @return 排好序的二维数组
*/
public static float[][] arraySort( float array[][], int row, boolean sort )
{
if( array!=null && array.length > 0 ) // 假如传入的输入不为 NULL 值
{
int len = array.length; // 得到排序数组的长度
int width = array[0].length; // 得到数组的列数
boolean exchange = true; // 交换记录
float[] temp = new float[width]; // 用于存放临时值
if( len < row ) {
System.out.println( "错误信息:排序列数大于数组列数" );
return null;
}
for( int i=0; i=i; j--)
{
if( sort ) // 从高到底
{
if( array[j][row] < array[j+1][row] )
{
for(int t=0; t array[j+1][row] )
{
for(int t=0; t 排序前
0.3 3.0
0.2 2.0
0.1 1.0
排序后
0.1 1.0
0.2 2.0
0.3 3.0
使用TreeMap
在处理储存相似歌的id和歌曲相似度的时候,不需要二维数组,java有很多优秀的机制供我们使用,非常方便。 TreeMap可以使key自动排序,我选择使用歌曲相似度为key,所以当我每插入一个的时候已经排好序了,非常方便。- TreeMap按照key排序
如果新建一个默认的Treemap是将key升序排列的,而我这里需要一个降序排列的,所以要自己写Comparator。java代码如下:
TreeMap simAndsongid = new TreeMap(new Comparator(){
/*
* int compare(Object o1, Object o2) 返回一个基本类型的整型,
* 返回负数表示:o1 小于o2,
* 返回0 表示:o1和o2相等,
* 返回正数表示:o1大于o2。
*/
public int compare(Float o1, Float o2) {
//指定排序器按照降序排列
return o2.compareTo(o1);
}
}); 获得Resultset的行数
后来没有用数组,用的ArrayList,动态数组,更为方便。
我在用JDBC执行sql语句后,必须要获得返回的结果有多少行,我才可以新建一个song的数组。但是Resultset居然有没有相应的函数完成这个功能,我在网上查了一下,主要使用的方法有下面一篇博客的总结:
- Resultset求行数和列数
失败经历
对mysql读写太频繁的话不好,还不如一次性读入到内存中。我本来打算,计算某一个歌曲A的相似度的时候,先读出这个歌曲的用户列表。再依次读下一个歌曲B的用户列表然后计算相似度,如果属于已经计算的相似度的top10的话,那么就替换,不属于就跳过这样导致我计算一个首歌时,就要对数据库读1万次,因为有1万首歌嘛,我要读其他9999首歌的用户列表。那么我读第二首的时候又读了9999次,读第三首的时候又读了9999次。一共要读10000乘以9999次。而我现在都完成一首歌的计算就要花费很长时间了,我现在才发现的(现在实际代码在运行),我看cpu的使用率主要是被数据库霸占了,所以我认为这是一次失败的方法。结论:
- 我不应该频繁的读取数据库,像上面数据我明明读10000次就可以,却读了10000乘以9999次,当然最好想办法一次性读到内存中就好了。
- 不要只考虑语言的优劣,还要考虑到对数据库的读取。因为对数据库的读取是非常耗时的,所以才出现了内存。
- 一次性读完所有数据:也就是一万首歌曲中每一首歌曲的收藏用户。使用hashtable的办法,收藏的用户列表用
JDBC数据库读写错误
如果在一个结果集的循环中还要再执行另一个sql语句的话,为了避免上一个sql连接关闭,请使用彻底解决Operation not allowed after ResultSet closed的问题
错误示范,将会报错Operation not allowed after ResultSet closed:
Statement statement = conn.createStatement();
//String sql = "select * from student";
String sql,sql1;
sql = "SELECT musicid FROM mostsmallfavorites GROUP BY musicid";
ResultSet rs1 = statement.executeQuery(sql);
//int musicids[]=new int[10000];//用于储存需要计算相似度的所有歌曲的id
index=0;//就是数组下标
while(rs1.next()){
List userids= new ArrayList();
int musicid = rs1.getInt("musicid");
sql1 = "SELECT userid FROM mostsmallfavorites where musicid ="+musicid;
ResultSet rs2 = statement.executeQuery(sql1);
while(rs2.next()){
userids.add(rs2.getInt("userid"));
}
musicids.put(musicid, userids);
userids=null;
}
正确的示范:
Statement statement = conn.createStatement();
Statement statement1 = conn.createStatement();
//String sql = "select * from student";
String sql,sql1;
sql = "SELECT musicid FROM mostsmallfavorites GROUP BY musicid";
ResultSet rs1 = statement.executeQuery(sql);
//int musicids[]=new int[10000];//用于储存需要计算相似度的所有歌曲的id
index=0;//就是数组下标
while(rs1.next()){
List userids= new ArrayList();
int musicid = rs1.getInt("musicid");
sql1 = "SELECT userid FROM mostsmallfavorites where musicid ="+musicid;
ResultSet rs2 = statement1.executeQuery(sql1);
while(rs2.next()){
userids.add(rs2.getInt("userid"));
}
musicids.put(musicid, userids);
userids=null;
}对比python、java、c/c++的计算速度
之前由于使用python代码和皮尔逊方式计算歌曲的相似度,导致一共算了4天,才能将1万首歌曲的相似度计算完成,我本来想使用java和c/c++来计算其他方式的时候,但是这次Jaccard系数的计算过程特别简单,不像皮尔逊方式需要维护巨大的矩阵。所以我觉得这次java的计算速度快并不能说明java就比python快很多。
但是我惊奇的发现,java在读取数据库的速度的时候好慢哦,我这次计算居然要读接近7分钟,而我记得python当时读的更为复杂,才读了1分半钟。
本次计算非常简单,所以我觉得除了读取数据库的时间,其他计算和插入数据库的部分都在5分钟之内结束了。
源代码
import java.io.File;
import java.sql.*;
import java.io.IOException;
import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
import java.util.Comparator;
import java.util.TreeMap;
/**
* 使用Jaccard系数的方式计算歌曲的相似度
* @author chouyou
*
*/
public class Jaccard {
public static void main(String[] args) {
Hashtable musicids= new Hashtable();//键为歌曲id,值为收藏用户的列表
int i;
// 驱动程序名
String driver = "com.mysql.jdbc.Driver";
// URL指向要访问的数据库名test
String urlToDB = "jdbc:mysql://localhost:3306/musicrecomsys";//数据默认的端口访问是3306
//MySQL配置时的用户名
String user = "root";
// MySQL配置时的密码
String password = "root";
try {
// 加载驱动程序
Class.forName(driver);
// 连续数据库
Connection conn = DriverManager.getConnection(urlToDB, user, password);
if(!conn.isClosed())
System.out.println("Succeeded connecting to the Database!");
// statement用来执行SQL语句
Statement statement = conn.createStatement();
Statement statement1 = conn.createStatement();
//String sql = "select * from student";
String sql,sql1;
sql = "SELECT musicid FROM mostsmallfavorites GROUP BY musicid";
ResultSet rs1 = statement.executeQuery(sql);
System.out.println("开始读....");
while(rs1.next()){
List userids= new ArrayList();
int musicid = rs1.getInt("musicid");
sql1 = "SELECT userid FROM mostsmallfavorites where musicid ="+musicid;
ResultSet rs2 = statement1.executeQuery(sql1);
while(rs2.next()){
userids.add(rs2.getInt("userid"));
}
musicids.put(musicid, userids);
userids=null;
}
System.out.println("读完....");
Set keyset=musicids.keySet();//拿到所有的键
//遍历所有的键
Iterator it1 = keyset.iterator();
//指定排序器
TreeMap simAndsongid = new TreeMap(new Comparator(){
/*
* int compare(Object o1, Object o2) 返回一个基本类型的整型,
* 返回负数表示:o1 小于o2,
* 返回0 表示:o1和o2相等,
* 返回正数表示:o1大于o2。
*/
public int compare(Float o1, Float o2) {
//指定排序器按照降序排列
return o2.compareTo(o1);
}
});
int flag=0;//输出在控制台表示计算到了第几首。
while(it1.hasNext()){
flag++;
System.out.println("共:"+keyset.size()+" 正在计算第"+flag+"首");
int songId1=(int) it1.next();
List userIds1= new ArrayList();
userIds1=musicids.get(songId1);
Iterator it2= keyset.iterator();
while(it2.hasNext()){
int songId2=(int) it2.next();
if(songId1==songId2){
continue;
}
List userIds2= new ArrayList();
userIds2=musicids.get(songId2);
float similarity=jaccard(userIds1, userIds2);
//把其他歌曲与songId1的相似度存起来,当然只存不为0的。
if(similarity!=0){
simAndsongid.put(similarity, songId2);//每插进去一个就会有高到底的排序
}
}
//计算完一首歌曲,也就是songid1之后,将simAndsongid的前10名结果插入表:simmusicjaccard
for(i=0;i<10;i++){//因为只保留前10首到数据库,所以只循环10次
if(!simAndsongid.isEmpty()){
float similarity=simAndsongid.firstKey();//第一个就是相似度最高的一个
int songId2=simAndsongid.get(similarity);
sql = "INSERT INTO simmusicjaccard SET musicid=\""+songId1+
"\",simmusicid =\""+songId2+"\",similarity =\""+similarity+"\"";
simAndsongid.remove(similarity);//把这次循环最高的给删除掉,那么次高的就会变成最高的
}else{
System.out.println("ID:"+songId1+",无相似歌");
break;
}
}
simAndsongid.clear();
it2=null;
}
}
catch(ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch(SQLException e) {
e.printStackTrace();
} catch(Exception e) {
e.printStackTrace();
}
}
/**
* 计算jaccard系数
* @param userIds1 List是收藏了某一首歌曲用户id集合,是int类型
* @param userIds2 List是收藏了另一首歌曲用户id集合,是int类型
* @return
*/
private static float jaccard(List userIds1, List userIds2) {
float intersectionNum=0;//等下计算Jaccard的时候我们需要产生小数,所以这里直接设置为float算了
Iterator it1 = userIds1.iterator();
Iterator it2 = userIds2.iterator();
while(it1.hasNext()){
int userId1=(int) it1.next();
while(it2.hasNext()){
int userId2=(int) it2.next();
if(userId1==userId2){
intersectionNum++;
}
}
}
float Jaccard=intersectionNum/(userIds1.size()+userIds2.size()-intersectionNum);
return Jaccard;
}
}
java工程已经打包上传至网盘:
- Jaccard系数计算歌曲相似度.rar