本章主要解决的是如何为应用选择一个合适的数据库,使之能够正确地进行数据的存储和检索。不同的数据库的工作方式可能会差异很大,因此我们作为开发者需要对每个数据库的特性了然于胸,才能选择到适合应用的数据库。
本节内容先介绍数据结构和索引的相关知识。
数据库的数据结构
先从一个世界上最简单的数据库来引起话题,这两个bash函数就实现了一个数据库:
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
通过上面的语句,我们很容易的可以使用这个数据库:
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}'
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
$ db_set 42 '{"name":"San Francisco","attractions":["Exploratorium"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Exploratorium"]}
$ cat database
123456,{"name":"London","attractions":["Big Ben","London Eye"]}
42,{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
42,{"name":"San Francisco","attractions":["Exploratorium"]}
这个数据库用的很爽是不是?但它存在着一个隐藏的问题:当数据量不断增加时,每次查找一条记录的时间会越来越长,时间复杂度为O(n)。那要解决这个问题,就引出了索引的概念。
索引是和存储的数据分离的额外结构,也就是对索引的添加、删除等操作,并不会影响数据库中的数据。索引的目的是为了提升查询性能。但由于索引会带来一些额外的写操作,因此会带来写入性能的降低。那么在实际应用中,如何选择合适的列创建索引,是完全由开发者来决定的。
Hash索引
前面的shell数据库,之所以查询性能会在大数据量下降低,是由于数据库并不知道某个key下的最后一条记录的存储位置。构建一个key和存储位置的关系,便是Hash索引的初衷。Hash索引适用于作为key-value型的数据库的索引结构。
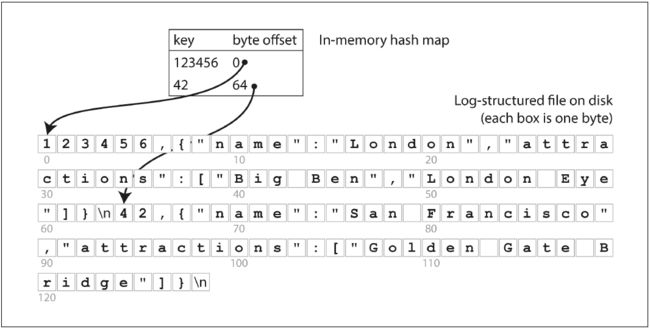
Hash索引的结构为一个HashMap,索引和数据的key是相同的, 索引的value为数据在文件中的byte offset。在每次写入一条新纪录时,在Hash索引中,更新这条记录对应的byte offset值;当查询一个值时,先在Hash索引中找到key对应的数据文件偏移量offset,然后查找到该位置,读出值即可。
这种方式的实现就是Bitcask,它将所有的keys放在RAM中,values存储在磁盘上,这样只需要最多一次寻址,就可以得到想要查找的值。这种很适合key的数量变化不是很快,同时每个key的值都会频繁变化的情况。
如果key的值都不相同,并且有大量写发生的情况,如果索引在一个文件中,很可能最终会用尽磁盘空间。如何避免这种情况呢?
一个好的解决方法是,分成多个文件存储,每个文件为一个segment。当文件到达特定大小时,将这个segment文件关闭,并写入到一个新的segment中。这样可以压缩每个segment文件,丢弃重复的key取值,只保留最新更新的值,减少每个segment文件的大小。这些动作都是在后台线程中进行的,不会影响正常的数据写入。在压缩完成后,用压缩后的segment文件替换掉压缩前的segment文件即可。以下分别是Segment的压缩,和多个Segments文件的压缩。
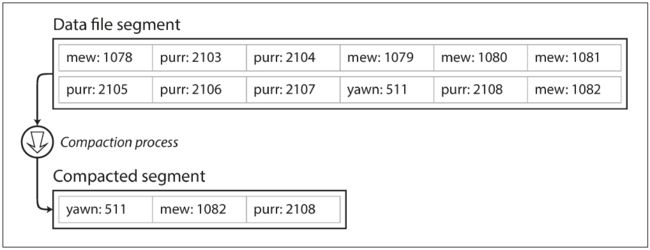

每个文件在内存中有自己的Hash索引,因此在查找时,先查找最新的Hash索引,如果key不存在,则继续查找第二新的索引,直到找遍所有的索引。
此外,还有以下的实现细节是需要注意的:
- 文件格式:CSV格式并不是最合适进行日志存储的,二进制格式更快且更简单;
- 删除记录:如果想要删除一个key时,需要追加一个特殊的删除标记,当在进行segment合并时,处理这个标记,丢弃这个key所有的values;
- 故障恢复:当数据库重启时,内存中的Hash索引需要读完所有的segment才能恢复,非常耗时,因此这里Bitcask采用了定期写入索引快照的方式,加速了索引读入内存的速度;
- 部分写入记录:数据库崩溃时写了一半的数据记录,Bitcask通过checksum的方式将这些损坏的数据标识为删除;
- 并发控制:写入文件是严格有序的,因此只有一个写入线程,但由于数据文件是不可变的,因此读取可以有多个线程并行。
追加日志存储的总结
- 好处:
- 文件块的追加写,要比磁盘的随机写速度快;
- 并发和故障恢复更加简单,不用担心有一部分旧的和一部分新的数据;
- 合并旧的segments可以避免数据文件碎片化的问题。
- 坏处:
- Hash索引必须在内存中,不能用于海量key值的情况;
- 范围查询效率不高,必须在Hash表中逐个查找。
SSTable的概念
SSTable的全称为Sorted String Table,和前面的追加日志型数据库,SSTable要求key-value对是按照key进行排序的,并且在每个合并后的segment文件中每个key只能出现一次。这样带来的好处是:
-
Segments的合并更加简单和高效,类似于归并排序;如果key在多个segments中出现,使用最近的segment文件中的值。
 多个SSTable segments文件的合并
多个SSTable segments文件的合并 -
不需要在内存中保存所有key的索引,只需要记录一些key的索引,便可以由他们的排序顺序,快速找到要查找的key的位置。
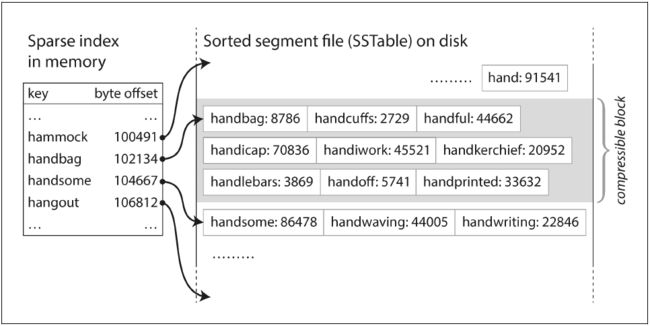 SSTable的内存索引
SSTable的内存索引 - 每个读请求扫描的key-value对的一段,可以将这段数据写入磁盘前进行压缩,
这样每个内存索引中的值指向的就是一个压缩块的起始位置,起到减少I/O带宽的作用。
SSTable的实现
在内存中保存一个有序的结构是比较简单的,有许多树的数据结构可以使用,比如红黑树,AVL树等。那么实现一个SSTable的过程如下:
- 当发生写时,将它添加到内存中的树数据结构中,成为memtable;
- 当memtable的大小超过某个值时,写入到磁盘成为SSTable文件,同时创建出一个新的memtable实例;
- 处理读请求的方式为,首先在memtable中查找key的值,然后在最新的磁盘segment中,然后在第二新的磁盘segment中,以此类推;
- 始终在后台进行segments的合并来丢弃被覆盖和删除的值。
为了避免当数据库崩溃时,memtable数据的丢失,将每次写操作记录在磁盘中的一个独立日志文件,以用于故障恢复。
LSM树
LSM树的算法就是上面介绍的SSTable,比如LevelDB和RocksDB都是该算法的应用。此外还有Lucene,在Elasticsearch和Solr中被广泛采用的全文本搜索引擎,也就是将文本的每个单词作为key,整个文本作为value的类SSTable。
LSM树的性能优化:
由于查询需要逐个查找每个segments,才知道某个key是否存在,因此使用Bloom Filter来快速判断某个key是否在数据库中存在,而不需要读取磁盘内容。
SSTables压缩和合并的优化方式:
- size-tierd:HBase,新的和小的SSTable,持续地合并为老的和大的SSTable;
- leveled:key分裂成为多个更小的SSTable,并且将更老的数据移动到独立的层。