基于线性判别分析(LDA)的客户流失预测
线性判别分析简述:
线性判别分析(Linear Discriminant Analysis, 简称LDA)是一个经典的降维算法。LDA在模式识别领域(比如人脸识别,舰艇识别等图形图像识别领域)中有非常广泛的应用。它与PCA(主成分分析)有一定的相似性。常见的LDA其实有两种,在NLP(自然语言处理)领域中LDA是隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),是一种处理文档的主题模型。
LDA的个人理解为:将数据在低维度上进行投影,投影后希望每类别数据的投影点尽可能的接近,不同类别数据的类别中心之间的距离尽可能的大。也就是就是“投影后类内方差最小,类间方差最大”。

数据来源:
https://www.kaggle.com/blastchar/telco-customer-churn

数据说明:
关于电信运营商客户数据集,每一行代表一个客户,每一列包含列元数据中描述的客户属性。原始数据包含7043行和21列。
各个字段的含义:
{
‘customerID’: ‘客户ID’,
‘gender’: ‘性别’,
‘SeniorCitizen’: ‘是否老年人’,
‘Partner’: ‘客户是否有配偶’,
‘Dependents’: ‘客户是否有亲属’,
‘tenure’: ‘客户本产品使用时长’,
‘PhoneService’: ‘是否订购电话服务’,
‘MultipleLines’: ‘是否有多重号码’,
‘InternetService’: ‘是否连接宽带网络’,
‘OnlineSecurity’: ‘是否开通网络安全服务’,
‘OnlineBackup’: ‘是否开通线上备份’,
‘DeviceProtection’: ‘是否开通设备保护’,
‘TechSupport’: ‘是否订购技术支持服务’,
‘StreamingTV’: ‘是否订购网络电视’,
‘StreamingMovies’: ‘是否订购网络电影’,
‘Contract’: ‘客服团队沟通维系频率’,
‘PaperlessBilling’: ‘客户是否有电子账单’,
‘PaymentMethod’: ‘客户支付方式’,
‘MonthlyCharges’: ‘每月消费金额’,
‘TotalCharges’: ‘累积消费金额’,
‘Churn’: ‘是否流失’,
}
实现过程:
导入数据集文件,查看数据集大小,并初步观察前5条的数据内容。
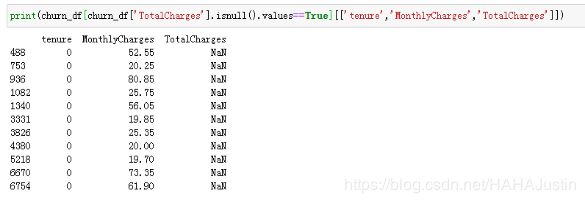
查看数据的详细情况,将TotalCharges(累计消费金额)的数据类型由字符串转换为浮点型。采用强制转换,如果遇到空值,则转换为NaN。


结合数据分析,累计消费金额为0的应该为新入网的客户,因此将这些客户使用时长改为1,将累计消费金额填充为每月消费金额。

查看流失客户数量和占比。


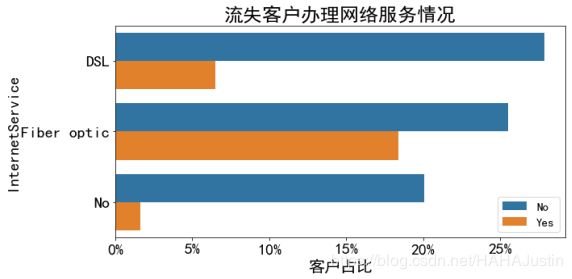
分析流失客户办理网络服务的情况。

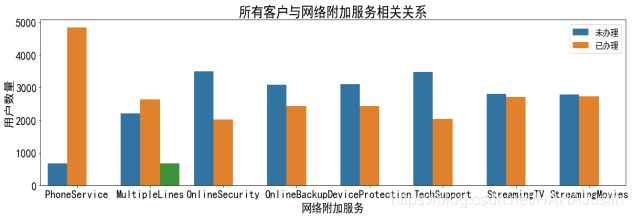
分析所有客户办理网络后对网络附加服务的办理情况。

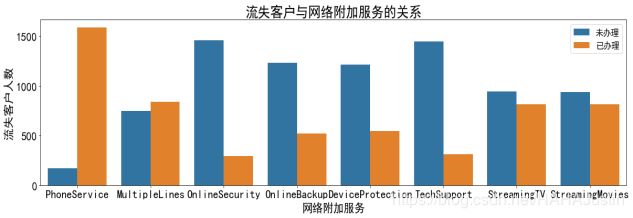
分析流失客户当中网络附加服务的办理情况。

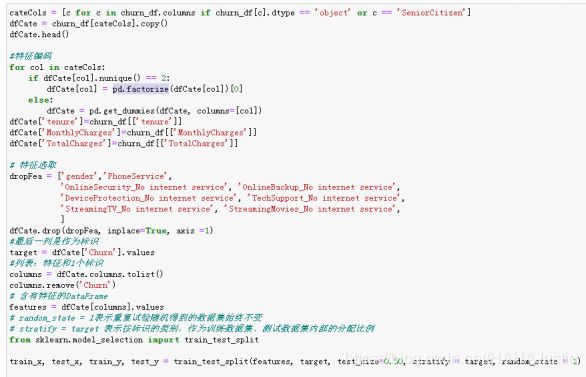
分析完成后便可以开始建模进行预测。首先观察数据类型,发现大多数都是离散特征。因此对于连续特征,采用标准化方式处理;对于离散特征,特征之间没有大小关系,采用one-hot编码;特征之间有大小关联,则采用数值映射。特征编码完成后就对特征进行提取,选择MothlyCharges、TotalCharges作为特征值,选择tenure为目标。并调用Sklearn包将数据划分为训练集合测试集。这里我设置了0.3,即将30%的数据设置为测试集。
使用LDA对数据集进行训练,并计算该模型的正确率。

得出LDA的正确率有80%。最后使用该模型对数据进行测试,得出预测结果。选择最后10条数据进行预测。

总结:
分析可知在办理了网络服务的客户中,办理光纤用户的流失占比较高,大于办理普通宽带的客户,因此建议降低光纤的资费或提高服务质量。在剩余的网络附加服务中,办理了安全、备份、保护、技术支持服务的流失率较低,而办理了网络电视、电影服务的流失率占比较高。因此建议可以适当降低资费甚至赠送网络电视等服务来挽留客户。对使用LDA模型预测出的可能流失的客户可以打电话、发信息等方式进行营销,使用赠送优惠券等方式挽留可能流失的客户。
实现代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
churn_df = pd.read_csv('./WA_Fn-UseC_-Telco-Customer-Churn.csv')
churn_df.shape
churn_df.head(5)
churn_df.info()
churn_df['TotalCharges']=pd.to_numeric(churn_df['TotalCharges'],errors='coerce')
churn_df['TotalCharges']
print(churn_df[churn_df['TotalCharges'].isnull().values==True][['tenure','MonthlyCharges','TotalCharges']])
churn_df.loc[:,'TotalCharges'].replace(to_replace=np.nan,value=churn_df.loc[:,'MonthlyCharges'],inplace=True)
churn_df.loc[:,'tenure'].replace(to_replace=0,value=1,inplace=True)
print(pd.isnull(churn_df['TotalCharges']).sum())
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['figure.figsize']=5,5
plt.pie(churn_df['Churn'].value_counts(),labels=churn_df['Churn'].value_counts().index,autopct='%1.1f%%',explode=(0.1,0))
plt.title('流失用户占比')
plt.show()
ratios = pd.DataFrame()
g = (churn_df.groupby("InternetService")["Churn"].value_counts()/len(churn_df)).to_frame()
g.rename(columns={"Churn":'客户占比'},inplace=True)
g.reset_index(inplace=True)
plt.figure(figsize=(10, 5))
ax = sns.barplot(x= '客户占比', y="InternetService", hue='Churn', data=g, orient='h')
ax.set_xticklabels(['{:,.0%}'.format(x) for x in ax.get_xticks()])
plt.legend(fontsize=15)
plt.title('流失客户办理网络服务情况' )
plt.show()
cols = ["PhoneService","MultipleLines","OnlineSecurity", "OnlineBackup", "DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies"]
df1 = pd.melt(churn_df[churn_df["InternetService"] != "No"][cols])
df1.rename(columns={'value': 'Has service'},inplace=True)
plt.figure(figsize=(20, 5))
ax = sns.countplot(data=df1, x='variable', hue='Has service')
ax.set(xlabel='网络附加服务', ylabel='用户数量')
plt.rcParams.update({'font.size':20})
plt.legend( labels = ['未办理', '已办理'],fontsize=15)
plt.title('所有用户与网络附加服务相关关系')
plt.show()
plt.figure(figsize=(20, 5))
df1 = churn_df[(churn_df.InternetService != "No") & (churn_df.Churn == "Yes")]
df1 = pd.melt(df1[cols])
df1.rename(columns={'value': 'Has service'}, inplace=True)
ax = sns.countplot(data=df1, x='variable', hue='Has service', hue_order=['No', 'Yes'])
ax.set(xlabel='网络附加服务', ylabel='流失用户人数')
plt.rcParams.update({'font.size':20})
plt.legend( labels = ['未办理', '已办理'],fontsize=15)
plt.title('流失用户与网络附加服务的关系')
plt.show()
cateCols = [c for c in churn_df.columns if churn_df[c].dtype == 'object' or c == 'SeniorCitizen']
dfCate = churn_df[cateCols].copy()
dfCate.head()
#特征编码
for col in cateCols:
if dfCate[col].nunique() == 2:
dfCate[col] = pd.factorize(dfCate[col])[0]
else:
dfCate = pd.get_dummies(dfCate, columns=[col])
dfCate['tenure']=churn_df[['tenure']]
dfCate['MonthlyCharges']=churn_df[['MonthlyCharges']]
dfCate['TotalCharges']=churn_df[['TotalCharges']]
# 特征选取
dropFea = ['gender','PhoneService',
'OnlineSecurity_No internet service', 'OnlineBackup_No internet service',
'DeviceProtection_No internet service', 'TechSupport_No internet service',
'StreamingTV_No internet service', 'StreamingMovies_No internet service',
]
dfCate.drop(dropFea, inplace=True, axis =1)
#最后一列是作为标识
target = dfCate['Churn'].values
#列表:特征和1个标识
columns = dfCate.columns.tolist()
columns.remove('Churn')
# 含有特征的DataFrame
features = dfCate[columns].values
# random_state = 1表示重复试验随机得到的数据集始终不变
# stratify = target 表示按标识的类别,作为训练数据集、测试数据集内部的分配比例
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(features, target, test_size=0.30, stratify = target, random_state = 1)
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
lda= LDA(n_components=1)
lda.fit(train_x,train_y)
X_sklearn = lda.transform(train_x)
print ('LDA的正确率:',lda.score(test_x,test_y))
# 提取customerID
customerID=churn_df['customerID']
churn_df.drop(['customerID'],axis=1, inplace=True)
pred_id = customerID.tail(10)
pred_x = dfCate.drop(['Churn'],axis=1).tail(10)
# 预测值
pred_y = lda.predict(pred_x)
# 预测结果
predDf = pd.DataFrame({'customerID':pred_id, 'Churn':pred_y})
print(predDf)