基于卷积神经网络的验证码识别(准确率87.5%+)
目录
- 一、任务背景与目标概述
- 二、卷积神经网络简介
- 三、方案设计及实现过程
- 四、实验结果及分析与讨论
- 五、结论
- 实现代码
一、任务背景与目标概述
随着现代网络技术的飞速发展和提高,改善了我们的生活质量,同时也给生活带来了很多便利,但随之而来的还有许多问题,例如日益严重的网络安全问题。在学习了人工神经网络之后,网络安全相关知识,决定完成一个基于卷积神经网络的验证码识别程序。在进行渗透测试时,发现网站或者CMS后台后可以进行爆破。账户名和密码可以用常用字符组成字典进行暴力破解,但安全性稍高的网站会在重复登录后添加验证码验证,这就需要对随机产生的验证码进行识别。能识别的验证码加上账户名和密码字典构造一个网络数据包便可以进行爆破以此尝试登录后台进行之后一系列的操作。
该程序的目标为能较准确的识别4位由英文大小写字母和数字所组成经过复杂化(加噪声等)处理的验证码。
二、卷积神经网络简介
卷积神经网络(Convolutional Neural Network,简称CNN)和人工神经网络(Artificial Neural Network,简称ANN)网络相比,拥有更强的网络稀疏性和参数共享性。CNN通常由输入层,隐藏层,输出层构成,其中隐藏层中常见的有卷积层,池化层和全连接层。其常见的架构模式为一个或几个卷积操作后跟着一个池化操作,以此为一个单元,重复数次。随后是若干全连接层,最后常使用softmax函数来处理输出。相较于单纯使用全连接层建构的神经网络相比,在提升性能的同时,大量减少了参数量,降低了计算成本。其主要原因为:1.参数共享,以图像分类为例,每个filter以及output都可以在input的不同区域中使用同样的参数,一边提取其他特征。整张图片会共享数个filter,提取效果也很好。2.系数连接,区别于全连接层,每个隐藏单元的output都只作为下一层相邻的数个隐层单元的input,为不再是全部。每一个像素的局部影响被放大,而全局影响被减弱。

三、方案设计及实现过程
卷积神经网络的训练最重要的是训练集,大量的数据训练的模型一定程度上可以提高模型的准确性。由于使用网络爬虫爬取大量的验证码较不方便,因此通过调用captcha模块来自己生成验证码。验证码生成的步骤:首先随机在英文大小写字母和数字中选择4个字符,然后创建背景图片,最后添加噪声以及字符扭曲等干扰手段。英文大小写字母各26个,数字0-9共10个,合计62个。验证码长度为4,因此总共有62×62×62×62种不同的可能。

获得数据集后就要对数据进行预处理。对获得的验证码进行分析,为彩色图,格式为60×160×3。为便于处理,将验证码转换为灰度图,再将图片降维转化数组的形式进行储存并将文本型的验证码转换成向量。由于最后测试阶段的得到的是向量型的验证码,所以也需要将向量型的验证码转化为文本的函数。


都定义完成后,调用这些函数来生成一个训练batch。batch_size的大小设置为64。同时判定一下图片格式是否正确。

做好对数据的预处理后便开始构建卷积神经网络。模型基于tensorflow构建,正向传播中设计了三个卷积池化层,池化方法选择最大池化,激活函数使用Relu函数,并使用dropout函数防止过拟合。
输入图片大小为60×160×1。
第一层卷积设置了32个滤波器,每个滤波器的大小为3×3×1,步长为1。输出60×160×32。
第一层池化,大小2×2,步长为2。输出30×80×32。
第二层卷积设置了64个滤波器,每个滤波器的大小为3×3×32,步长为1。输出30×80×64。
第二层池化,大小2×2,步长为2。输出15×40×64。
第三层卷积设置了64个滤波器,每个滤波器的大小为3×3×64,步长为1。输出15×40×64。
第三层池化,大小2×2,步长为2。输出8×20×64。
池化后的输出接全连接层。全连接层设置了1024个神经元。最后在接一个全连接层输出。

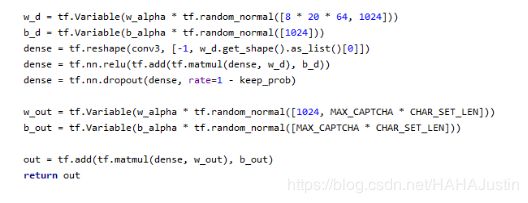
反向传播则使用sigmoid交叉熵计算损失值,采用梯度下降的方法获取极值,使用AdamOptimizer优化器优化算法,更新权值并计算准确率。设定为每100次计算一次准确率。利用tensorflow的saver.save函数来保存训练的模型,即当计算的准确率大于85%时保存这个模型在相应的文件夹。

最后还需要定义一个函数,需要将保存的模型导出,再将要预测的验证码图片放入模型中计算,得到最终识别的结果。
四、实验结果及分析与讨论
使用captcha模块生成的验证码。

经过7个小时的训练,得到了87.5%的准确率,共训练了2万多张的验证码。由于电脑配置以及时间原因,准确率到87.5%便停止了训练,将模型保存了下来。推测如果再花些时间训练,准确率应该可以达到90%以上。
训练的过程:
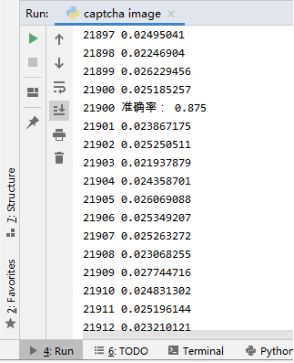
准确率大于85%所保存的模型:

得到模型后调用该模型对验证码进行测试。随机采用10个验证码进行测试。
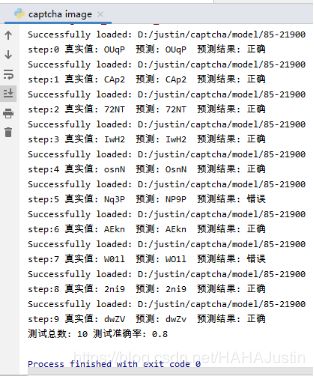
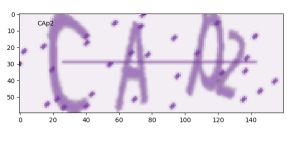
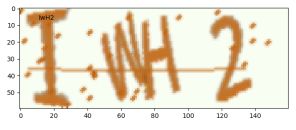
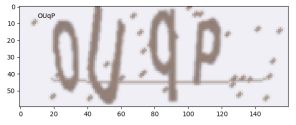
由上图可知该模型相对可靠,能够识别英文字母大小写以及数字,准确率相对较高。

该验证码识别错误,将w01l识别成了wo1l,由于0和o较为相似,人都不能够百分之百的认出,因此识别错误能够理解。
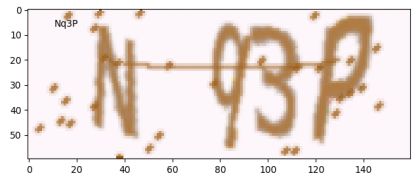
该验证码识别错误,将Nq3P识别成了NP9P。第一个字符和第四个字符识别正确,但第二个和第三个识别错误。可能原因为这两个字符太过靠近,造成了干扰,因此识别错误。
共测试了10个验证码,8个预测正确,2个预测错误,总体准确率为80%。模型仍然有不足,但个人认为该模型已算成功,能对大多数的英文大小写字母和数字进行识别。
五、结论
用卷积神经网络识别验证码的方法较为高效,经过不算很长时间的训练便可以达到85%以上的准确度。如果机器条件允许,加大训练的时间,准确度完全可以达到95%以上。但缺点也很明显,卷积神经网络识别验证码不同于将图片进行分割等处理的识别方法,而是直接对整个验证码图片进行分析,因此若字符太过靠近或者重叠则无法准确的识别。
随之技术的发展,单纯的字母和数字的组合慢慢会被淘汰。例如12306已经实行了图片验证码,学信网实行回答问题式的验证码,该程序只能应用到一些小型网站进行渗透测试。但卷积神经网络也在发展,不同的优化算法也不断出现。通过对网上资料的搜集,可以考虑用VGG16算法对该模型进行优化,识别能力也许能够提升,甚至可以识别图片验证码。
实现代码
import tensorflow as tf
import numpy as np
from captcha.image import ImageCaptcha
from PIL import Image
import random
import matplotlib.pyplot as plt
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z']
ALPHABET = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U',
'V', 'W', 'X', 'Y', 'Z']
def random_captcha_text(char_set=number + alphabet + ALPHABET, captcha_size=4):
captcha_text = []
for i in range(captcha_size):
c = random.choice(char_set)
captcha_text.append(c)
return captcha_text
def gen_captcha_text_and_image(i=0):
# 创建图像实例对象
image = ImageCaptcha()
# 随机选择4个字符
captcha_text = random_captcha_text()
# array 转化为 string
captcha_text = ''.join(captcha_text)
# 生成验证码
captcha = image.generate(captcha_text)
if i % 100 == 0:
image.write(captcha_text, "D:/justin/captcha/image/" + captcha_text + '.jpg')
captcha_image = Image.open(captcha)
captcha_image = np.array(captcha_image)
return captcha_text, captcha_image
def convert2gray(img):
if len(img.shape) > 2:
gray = np.mean(img, -1)
return gray
else:
return img
# 文本转向量
def text2vec(text):
text_len = len(text)
if text_len > MAX_CAPTCHA:
raise ValueError('验证码最长4个字符')
vector = np.zeros(MAX_CAPTCHA * CHAR_SET_LEN)
def char2pos(c):
if c == '_':
k = 62
return k
k = ord(c) - 48
if k > 9:
k = ord(c) - 55
if k > 35:
k = ord(c) - 61
if k > 61:
raise ValueError('No Map')
return k
for i, c in enumerate(text):
idx = i * CHAR_SET_LEN + char2pos(c)
vector[idx] = 1
return vector
# 向量转回文本
def vec2text(vec):
char_pos = vec[0]
text = []
for i, c in enumerate(char_pos):
char_idx = c % CHAR_SET_LEN
if char_idx < 10:
char_code = char_idx + ord('0')
elif char_idx < 36:
char_code = char_idx - 10 + ord('A')
elif char_idx < 62:
char_code = char_idx - 36 + ord('a')
elif char_idx == 62:
char_code = ord('_')
else:
raise ValueError('error')
text.append(chr(char_code))
return "".join(text)
# 生成一个训练batch
def get_next_batch(batch_size=64):
batch_x = np.zeros([batch_size, IMAGE_HEIGHT * IMAGE_WIDTH])
batch_y = np.zeros([batch_size, MAX_CAPTCHA * CHAR_SET_LEN])
def wrap_gen_captcha_text_and_image(i):
while True:
text, image = gen_captcha_text_and_image(i)
if image.shape == (60, 160, 3):
return text, image
for i in range(batch_size):
text, image = wrap_gen_captcha_text_and_image(i)
image = convert2gray(image)
batch_x[i, :] = image.flatten() / 255
batch_y[i, :] = text2vec(text)
return batch_x, batch_y
# 定义CNN
def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1):
x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
w_c1 = tf.Variable(w_alpha * tf.random_normal([3, 3, 1, 32]))
b_c1 = tf.Variable(b_alpha * tf.random_normal([32]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, rate=1 - keep_prob)
w_c2 = tf.Variable(w_alpha * tf.random_normal([3, 3, 32, 64]))
b_c2 = tf.Variable(b_alpha * tf.random_normal([64]))
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2))
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv2 = tf.nn.dropout(conv2, rate=1 - keep_prob)
w_c3 = tf.Variable(w_alpha * tf.random_normal([3, 3, 64, 64]))
b_c3 = tf.Variable(b_alpha * tf.random_normal([64]))
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3))
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv3 = tf.nn.dropout(conv3, rate=1 - keep_prob)
w_d = tf.Variable(w_alpha * tf.random_normal([8 * 20 * 64, 1024]))
b_d = tf.Variable(b_alpha * tf.random_normal([1024]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
dense = tf.nn.dropout(dense, rate=1 - keep_prob)
w_out = tf.Variable(w_alpha * tf.random_normal([1024, MAX_CAPTCHA * CHAR_SET_LEN]))
b_out = tf.Variable(b_alpha * tf.random_normal([MAX_CAPTCHA * CHAR_SET_LEN]))
out = tf.add(tf.matmul(dense, w_out), b_out)
return out
# 训练
def train_crack_captcha_cnn():
output = crack_captcha_cnn()
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=Y)) # 计算损失
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss) # 计算梯度
predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]) # 目标预测
max_idx_p = tf.argmax(predict, 2) # 目标预测最大值
max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2) # 真实标签最大值
correct_pred = tf.equal(max_idx_p, max_idx_l)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) # 准确率
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
step = 0
while True:
batch_x, batch_y = get_next_batch(64)
_, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.75})
print(step, loss_)
if step % 100 == 0:
batch_x_test, batch_y_test = get_next_batch(100)
acc = sess.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.})
print(step, "准确率:",acc)
if acc > 0.85:
saver.save(sess, "D:/justin/captcha/model/85", global_step=step)
step += 1
def crack_captcha(captcha_image, output):
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
# 获取训练后的参数
checkpoint = tf.train.get_checkpoint_state("model")
if checkpoint and checkpoint.model_checkpoint_path:
saver.restore(sess, checkpoint.model_checkpoint_path)
print("Successfully loaded:", checkpoint.model_checkpoint_path)
else:
print("Could not find old network weights")
predict = tf.argmax(tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
text_list = sess.run(predict, feed_dict={X: [captcha_image], keep_prob: 1})
text = vec2text(text_list)
return text
if __name__ == '__main__':
train = 1 # 0: 训练 1: 预测
if train == 0:
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't',
'u', 'v', 'w', 'x', 'y', 'z']
ALPHABET = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z']
text, image = gen_captcha_text_and_image()
print("验证码图像channel:", image.shape)
# 图像大小
IMAGE_HEIGHT = 60
IMAGE_WIDTH = 160
MAX_CAPTCHA = len(text)
print("验证码文本最长字符数", MAX_CAPTCHA)
# 文本转向量
char_set = number + alphabet + ALPHABET + ['_'] # 如果验证码长度小于4, '_'用来补齐
CHAR_SET_LEN = len(char_set)
# placeholder占位符
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT * IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA * CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32)
train_crack_captcha_cnn()
# 预测时需要将训练的变量初始化
if train == 1:
# 自然计数
step = 0
# 正确预测计数
rightCnt = 0
# 设置测试次数
count = 10
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't',
'u', 'v', 'w', 'x', 'y', 'z']
ALPHABET = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z']
IMAGE_HEIGHT = 60
IMAGE_WIDTH = 160
char_set = number + alphabet + ALPHABET + ['_']
CHAR_SET_LEN = len(char_set)
MAX_CAPTCHA = 4
# placeholder占位符
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT * IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA * CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32)
output = crack_captcha_cnn()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 获取训练后参数路径
checkpoint = tf.train.get_checkpoint_state("model")
if checkpoint and checkpoint.model_checkpoint_path:
saver.restore(sess, checkpoint.model_checkpoint_path)
print("Successfully loaded:", checkpoint.model_checkpoint_path)
else:
print("Could not find old network weights.")
while True:
text, image = gen_captcha_text_and_image()
f = plt.figure()
ax = f.add_subplot(111)
ax.text(0.1, 0.9,text, ha='center', va='center', transform=ax.transAxes)
plt.imshow(image)
plt.show()
image = convert2gray(image)
image = image.flatten() / 255
predict = tf.math.argmax(tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
text_list = sess.run(predict, feed_dict={X: [image], keep_prob: 1})
predict_text = vec2text(text_list)
predict_text = crack_captcha(image, output)
print("step:{} 真实值: {} 预测: {} 预测结果: {}".format(str(step), text, predict_text,
"正确" if text.lower() == predict_text.lower() else "错误"))
if text.lower() == predict_text.lower():
rightCnt += 1
if step == count - 1:
print("测试总数: {} 测试准确率: {}".format(str(count), str(rightCnt / count)))
break
step += 1