基于并行计算(MapReduce)的PM2.5数据集处理
目录
- 问题描述
- 实现环境
- 方案设计
- 代码实现
- 结果展示
- 总结
问题描述
对提供的PM2.5的数据进行分析
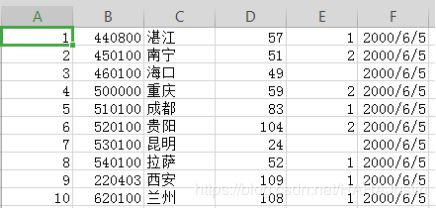
1.对所有城市的PM2.5的平均值进行排序,保存到一个文件中;

2.对每一个城市,计算2000年6月到2015年2月,每个月份的PM2.5平均值,并将每一个城市的结果保存到一个文件中。(对于每个月份数据缺失大于1/2的平均值用NaN表示,对于月份数据缺失小于1/2的计算已有天数的平均值)
实现环境
Hadoop2.7.2
Java1.8
IntelliJ IDEA
Maven
方案设计
(1)将每行数据读入切割,去除无效数据并封装成bean对象,分别利用城市id和城市名作为key,value为PM2.5的值,将Map阶段读取到的所有数据按照城市id排序分组,发送到Reduce。在Reduce之前对数据进行比较,只要城市id相同的则认为是同一个key,Reduce中计算各个城市PM2.5的平均值。
(2)将上一步输出的数据同样封装成bean对象,将PM2.5的平均值进行排序,value为空。最后发送到Reduce进行保存输出。
(1)将数据每行读入切割,去除无效数据。将城市id、城市名和检测日期作为key,PM2.5的值作为value进行Map操作。Reduce阶段计算各个城市每个月份PM2.5的平均值,同时对每个月份的缺失数据进行统计。若每个月缺失值大于等于15天,平均值用NaN表示,其他用已有天数的平均值。
(2)将上一步输出的数据在Map中进行切割,传入到Reduce中,将每一个城市的结果保存输出。
代码实现
(1)定义数据DataBean类
package pm_1.bob1;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class DataBean implements WritableComparable<DataBean> {
private long cityId;
private String cityName;
private double pmValue;
private String collectDate;
public DataBean() {
super();
}
public DataBean(long cityId, String cityName, int pmValue, String collectDate) {
super();
this.cityId = cityId;
this.cityName = cityName;
this.pmValue = pmValue;
this.collectDate = collectDate;
}
public long getCityId() {
return cityId;
}
public void setCityId(long cityId) {
this.cityId = cityId;
}
public String getCityName() {
return cityName;
}
public void setCityName(String cityName) {
this.cityName = cityName;
}
public double getPmValue() {
return pmValue;
}
public void setPmValue(double pmValue) {
this.pmValue = pmValue;
}
public String getCollectDate() {
return collectDate;
}
public void setCollectDate(String collectDate) {
this.collectDate = collectDate;
}
public int compareTo(DataBean o) {
if (o.getCityId() > this.getCityId()) {
return 1;
} else if (o.getCityId() < this.getCityId()) {
return -1;
}
return 0;
}
public void write(DataOutput out) throws IOException {
out.writeLong(cityId);
out.writeUTF(cityName);
out.writeDouble(pmValue);
out.writeUTF(collectDate);
}
public void readFields(DataInput in) throws IOException {
cityId = in.readLong();
cityName = in.readUTF();
pmValue = in.readDouble();
collectDate = in.readUTF();
}
@Override
public String toString() {
String pmValueStr = String.format("%.2f",pmValue);
return cityId + "\t" + cityName +"\t"+pmValueStr ;
}
}
(2)编写PM_map类
package pm_1.bob1;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class PM_map extends Mapper<LongWritable, Text, DataBean, DoubleWritable> {
DataBean db = new DataBean();
DoubleWritable v = new DoubleWritable(0);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1,440800,湛江,57,1,2000-06-05
String line = value.toString();
String[] spilt = line.split(",");
Long cityId ;
if (spilt[1].equals("")){
cityId = 0L;
}else cityId= Long.parseLong(spilt[1]);
String cityName = spilt[2];
double pmValue = Double.parseDouble(spilt[3]);
String collectDate = spilt[5];
db.setCityId(cityId);
db.setCityName(cityName);
db.setPmValue(pmValue);
db.setCollectDate(collectDate);
v.set(pmValue);
context.write(db,v);
}
}
(3)编写PM_GroupCompare类
package pm_1.bob1;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class PM_GroupCompare extends WritableComparator {
protected PM_GroupCompare(){
super(DataBean.class,true);
}
@Override
public int compare(WritableComparable a,WritableComparable b) {
DataBean db1 = (DataBean) a ;
DataBean db2 = (DataBean) b ;
int result ;
if (db1.getCityId()>db2.getCityId()){
result =1;
}else if (db1.getCityId()<db2.getCityId()){
result = -1;
}else result = 0;
return result;
}
}
(4)编写PM_reduce类
package pm_1.bob1;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
public class PM_reduce extends Reducer<DataBean, DoubleWritable, DataBean, NullWritable> {
private long count;
private double sum;
@Override
protected void reduce(DataBean key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException {
sum = 0;
count = 0;
DoubleWritable v = new DoubleWritable();
for (DoubleWritable value : values) {
sum += value.get();
count++;
}
double avr = sum/count;
v.set(avr);
key.setPmValue(avr);
context.write(key,NullWritable.get());
}
}
(5)编写PM_job类
package pm_1.bob1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class PM_job implements Tool {
Configuration configuration = null;
public int run(String[] args) throws Exception {
//1.获取job
Job job = Job.getInstance(configuration);
//2.设置jar包路径
job.setJarByClass(PM_job.class);
job.setMapperClass(PM_map.class);
job.setReducerClass(PM_reduce.class);
//设置最后 kv类型
job.setOutputKeyClass(DataBean.class);
job.setOutputValueClass(NullWritable.class);
//设置map输出类型
job.setMapOutputKeyClass(DataBean.class);
job.setMapOutputValueClass(DoubleWritable.class);
//设置输入输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setGroupingComparatorClass(PM_GroupCompare.class);
boolean result = job.waitForCompletion(true);
return result? 0 : 1;
}
public void setConf(Configuration conf) {
configuration=conf ;
}
public Configuration getConf() {
return configuration;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
args = new String[]{"D:\\justin666\\data\\input","D:\\justin666\\data\\out"};
int run = ToolRunner.run(configuration, new PM_job(), args);
System.out.println(run);
}
}
(6)定义数据DataBean_2类
package pm_1.bob2;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class DataBean_2 implements WritableComparable<DataBean_2> {
private long cityId;
private String cityName;
private double pmValue;
public long getCityId() {
return cityId;
}
public void setCityId(long cityId) {
this.cityId = cityId;
}
public String getCityName() {
return cityName;
}
public void setCityName(String cityName) {
this.cityName = cityName;
}
public double getPmValue() {
return pmValue;
}
public void setPmValue(double pmValue) {
this.pmValue = pmValue;
}
public DataBean_2() {
}
public int compareTo(DataBean_2 o) {
if (o.getPmValue() > this.getPmValue()) {
return 1;
} else if (o.getPmValue() < this.getPmValue()) {
return -1;
}
return 0;
}
public void write(DataOutput out) throws IOException {
out.writeLong(cityId);
out.writeUTF(cityName);
out.writeDouble(pmValue);
}
public void readFields(DataInput in) throws IOException {
cityId = in.readLong();
cityName = in.readUTF();
pmValue = in.readDouble();
}
@Override
public String toString() {
String pmValueStr = String.format("%.2f",pmValue);
return cityId + "\t" + cityName +"\t"+pmValueStr ;
}
}
(7)编写PM_map_2类
package pm_1.bob2;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//659004 五家渠 110.55
public class PM_map_2 extends Mapper<LongWritable, Text, DataBean_2, NullWritable> {
DataBean_2 db = new DataBean_2();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] spilt = line.split("\t");
long cityId= Long.parseLong(spilt[0]);
String cityName = spilt[1];
double pmValue = Double.parseDouble(spilt[2]);
db.setCityId(cityId);
db.setCityName(cityName);
db.setPmValue(pmValue);
context.write(db,NullWritable.get());
}
}
(8)编写PM_reduce_2类
package pm_1.bob2;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
public class PM_reduce_2 extends Reducer<DataBean_2, NullWritable, DataBean_2, NullWritable> {
@Override
protected void reduce(DataBean_2 key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
(9)编写PM_job_2类
package pm_1.bob2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class PM_job_2 implements Tool {
Configuration configuration = null;
public int run(String[] args) throws Exception {
//1.获取job
Job job = Job.getInstance(configuration);
//2.设置jar包路径
job.setJarByClass(PM_job_2.class);
job.setMapperClass(PM_map_2.class);
job.setReducerClass(PM_reduce_2.class);
//设置最后 kv类型
job.setOutputKeyClass(DataBean_2.class);
job.setOutputValueClass(NullWritable.class);
//设置map输出类型
job.setMapOutputKeyClass(DataBean_2.class);
job.setMapOutputValueClass(NullWritable.class);
//设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
return result ? 0 : 1;
}
public void setConf(Configuration conf) {
configuration = conf;
}
public Configuration getConf() {
return configuration;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
args = new String[]{"D:\\justin666\\data\\input2","D:\\justin666\\data\\out2"};
int run = ToolRunner.run(configuration, new PM_job_2(), args);
System.out.println(run);
}
}
(1)编写PM_map_3类
package pm_2.bob3;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class PM_map_3 extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable();
//1,440800,湛江,57,1,2000/06/05
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] spilt = line.split(",");
long cityId ;
if (spilt[1].equals("")){
cityId = 0;
//预处理: 没有 cityId 直接省去
return;
}else {
cityId = Long.parseLong(spilt[1]) ;
}
String cityName = spilt[2];
String pmValue = spilt[3];
String collYM = spilt[5];
String collData = collYM.substring(0,7);
v.set(Integer.parseInt(pmValue));
String kStr = cityId +"\t"+ cityName +"\t"+collData ;
k.set(kStr);
context.write(k,v);
}
}
(2)编写PM_reduce_3类
package pm_2.bob3;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class PM_reduce_3 extends Reducer<Text, IntWritable, Text, Text> {
Text v= new Text();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
double avg = 0;
String pmValue;
for(IntWritable value :values ){
sum += value.get();
count ++;
}
if(count >=15){
avg = (double)sum/count;
pmValue = String.format("%.2f",avg);
}else {
pmValue = "NaN";
}
v.set(pmValue);
context.write(key,v);
}
}
(3)编写PM_job_3类
package pm_2.bob3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class PM_job_3 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//输入输出的文件夹 输出的文件夹不能存在
args = new String[]{"D:\\justin666\\data\\input","D:\\justin666\\data\\out3"};
job.setJarByClass(PM_job_3.class);
// 2 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(PM_map_3.class);
job.setReducerClass(PM_reduce_3.class);
// 3 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 4 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 5 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
(4)编写PM_map_4类
package pm_2.bob4;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class PM_map_4 extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 110000 北京 2000-06 118.00
String line = value.toString();
String[] spilt = line.split("\t");
String str = spilt[0]+"\t"+spilt[1]+"\t"+ spilt[3]+"\t"+spilt[2];
k.set(spilt[1]);
v.set(str);
context.write(k,v);
}
}
(5)编写PM_reduce_4类
package pm_2.bob4;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import java.io.IOException;
public class PM_reduce_4 extends Reducer<Text, Text, Text,NullWritable > {
private MultipleOutputs output;
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value:values){
output.write(value, NullWritable.get(), key.toString());
}
}
@Override
protected void setup(Context context) throws IOException, InterruptedException {
output = new MultipleOutputs(context);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
output.close();
}
}
(6)编写PM_job_4类
package pm_2.bob4;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class PM_job_4 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//输入输出路径
args = new String[]{"D:\\justin666\\data\\input3","D:\\justin666\\data\\out4"};
job.setJarByClass(PM_job_4.class);
// 2 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(PM_map_4.class);
job.setReducerClass(PM_reduce_4.class);
// 3 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 4 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 5 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
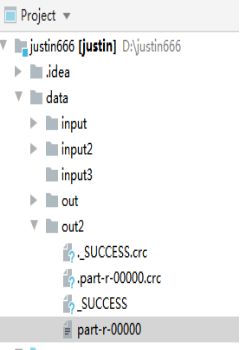
结果展示
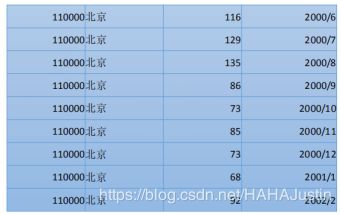
初始:

中间过程:
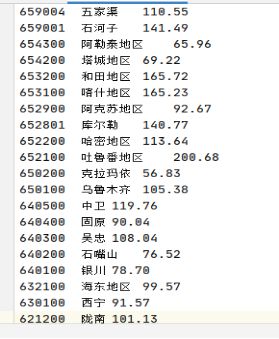
输出:
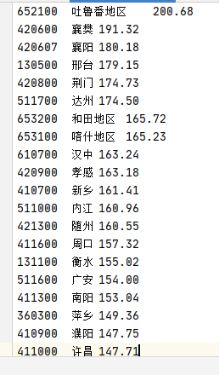
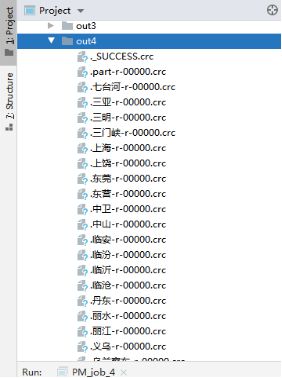
2.
初始:

中间过程:

输出:

总结
由于第一次接触MapReduce编程,同样也是首次使用Java写代码,在完成过程中遇到了许多问题。例如,解决这两个问题都用了两次MapReduce进行实现,但理论上感觉可以只使用一次MapReduce。其次在数据预处理时较为简单,只将缺少城市id的行直接省去。