CentOS7环境下搭建Hadoop集群教程
文章目录
- 系统环境
- 所需软件
- 搭建步骤
- 1.虚拟机环境搭建
- 1.1虚拟机安装
- 1.2克隆虚拟机
- 1.3修改虚拟机静态IP
- 1.4修改主机名
- 1.5关闭防火墙及绑定IP
- 2.JDK的安装与配置
- 3.MYSQL的安装与配置
- 3.1下载与安装
- 3.2启动及配置
- 4.SSH免密钥登录
- 5.Hadoop的安装与配置
- 5.1下载与解压安装
- 5.2目录规划
- 5.3环境配置
- 5.4集群测试
- 6.Zookeeper的安装与配置
- 6.1下载安装与配置
- 6.2从机配置
- 6.3集群测试
- 7.Scala的安装与配置
- 8.HBase的安装与配置
- 8.1下载及安装
- 8.2环境配置
- 8.3集群测试
- 9.Hive的安装与配置
- 9.1Hive安装及配置
- 9.2MySQL配置
- 9.3Hive初始化及启动
系统环境
CentOS7-64位:
master: 192.168.10.100 hadoop100
worker1: 192.168.10.101 hadoop101
worker2: 192.168.10.102 hadoop102
所需软件
VMware Workstation Pro 12
CentOS-7-x86_64-Minimal-1810.iso
PuTTY
WinSCP
JDK-1.8
MySQL-8.0
Scala-2.13.1
Hadoop-3.2.1
zookeeper-3.4.14
Hbase-2.2.2
Hive-3.1.2
搭建步骤
1.虚拟机环境搭建
1.1虚拟机安装
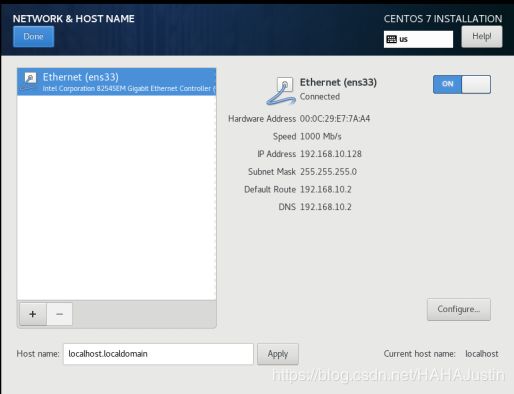
从CentOS官方网站下载系统的镜像文件(.iso),在VMware中进行虚拟机安装。首先应该将CentOS7系统安装好,配置虚拟机硬件时需要注意合理配置内存以及硬盘大小。配置完成后则可以进行安装,基本步骤为配置系统的时间,选择打开网络开关,选择系统文件安装的位置,设置root用户的密码以及创建新用户。配置完成后,等待安装完成后重启即可。安装过程即创建用户过程(简述)如下:
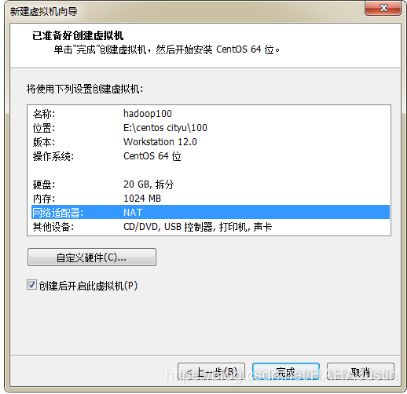
注意:网络适配器选择为NAT模式。
打开网络开关:
创建用户:
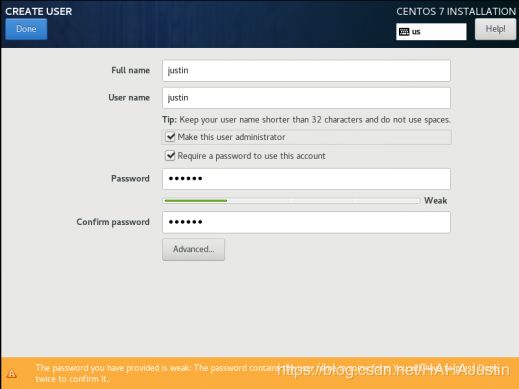
注意:勾选给予用户管理员权限。(也可以安装完成后为用户添加sudo权限。usermod -aG wheel 用户名)
1.2克隆虚拟机
(也可以将主机所有配置配置完成后再克隆从机,这样更简单)
以master为模板克隆两台虚拟机作为集群中worker1,worker2。

1.3修改虚拟机静态IP
进入网卡配置文件所在目录,使用ls命令查看配置文件名,再利用vi编辑器对文件进行修改。重点注意BOOTPROTO、ONBOOT、IP地址和网关。(vi编辑器使用命令略)
cd /etc/sysconfig/network-scripts
ls
vi ifcfg-ens33
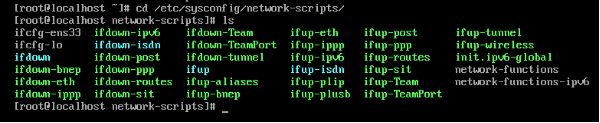
修改前:

修改后:
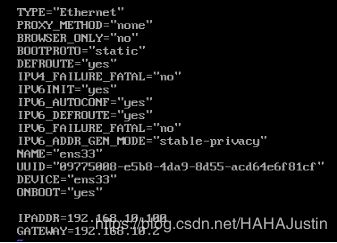
注意:可以使用service network restart 命令使修改生效,也可以重启。
1.4修改主机名
进入主机名所在目录,使用vi编辑器对主机名进行修改。
vi /etc/hostname
注意:重启生效。
1.5关闭防火墙及绑定IP
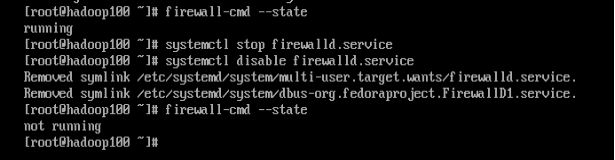
CentOS 7默认使用的是firewall作为防火墙,首先查看防火墙状态,使用命令关闭防火墙,再禁止firewall开机启动。
firewall-cmd --state
systemctl stop firewalld.service
systemctl disable firewalld.service
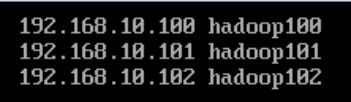
进入hosts所在目录,使用vi编辑器对各台机进行IP与主机名的绑定。
vi /etc/hosts
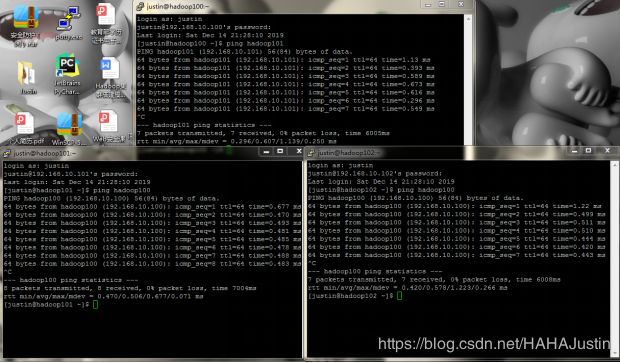
注意:修改完成后利用ping命令检测各台虚拟机之间的连通性。
连通性效果检测:
2.JDK的安装与配置
使用Putty连接虚拟机,用justin账户登录开始进行集群搭建。为系统更简洁明了,在~(/home/justin)路径下创建java文件夹,用于存放JDK文件。
cd ~
mkdir java
使用WinSCP登录虚拟机,将JDK文件复制到/home/justin/java路径下。
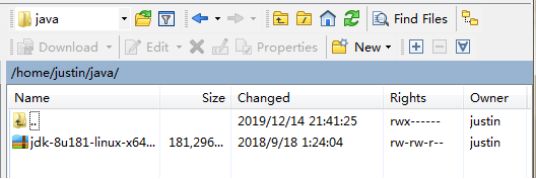
进入文件所在目录,进行解压安装并重命名。
cd /home/justin/java
tar -zxvf jdk-8u181-linux-x64.tar.gz
mv /home/justin/java/jdk1.8.0_181 /home/justin/java/jdk1.8.0_181-amd64
接着需要配置JAVA环境变量。利用vi编辑器对/etc/profile进行修改。(修改系统配置文件需要使用sudo权限)
sudo vi /etc/profile

注意:重启生效也可使用命令(source /etc/profile)立即生效。
最后输入命令(java -version)查看配置是否成功。若出现如下图所示版本号等则表示配置成功。集群中其他机器的配置也与此相同。

3.MYSQL的安装与配置
3.1下载与安装
首先创建mysql文件夹,然后在网上找到对应版本软件包的下载地址,利用curl命令进行下载,最后用yum命令进行安装(这里需要sudo权限)。
cd ~
mkdir mysql
cd mysql
curl -O http://repo.mysql.com/mysql80-community-release-el7-1.noarch.rpm
sudo yum -y localinstall mysql80-community-release-el7-1.noarch.rpm
sudo yum -y update
sudo yum -y install mysql-community-server

3.2启动及配置
首先启动mysql。
systemctl start mysqld
查看root临时密码。(这里需要sudo权限)
sudo grep ‘temporary password’ /var/log/mysqld.log

注意:如图所示可知root临时密码为 &he!af*(3veL 。如果没有返回任何结果,表示密码为“空”。
登录mysql,设置新密码(Hadoop@123),接着创建新账户(hadoop)。
mysql -u root -p
ALTER USER ‘root’@‘localhost’ IDENTIFIED BY ‘Hadoop@123’;
CREATE USER ‘hadoop’@‘localhost’ IDENTIFIED BY ‘Hadoop@123’;
CREATE USER ‘hadoop’@’%’ IDENTIFIED BY ‘Hadoop@123’;
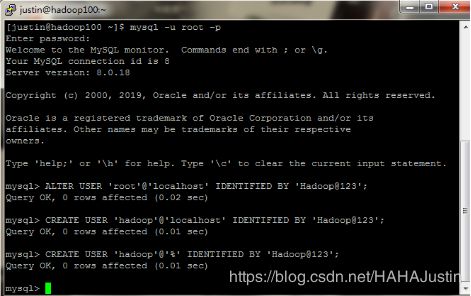
注意:mysql中操作语句需要“ ;”。
注意:使用SELECT user FROM mysql.user; 查看添加用户是否成功。

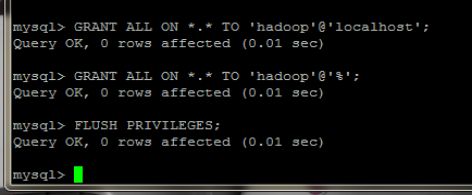
授予新账户权限。并使用(FLUSH PRIVILEGES;)命令刷新权限。
GRANT ALL ON . TO ‘hadoop’@‘localhost’;
GRANT ALL ON . TO ‘hadoop’@’%’;
4.SSH免密钥登录
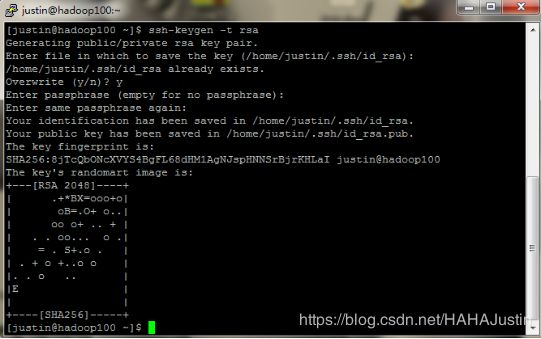
主机master创建密钥并传送给其他的从机(worker1、worker2)。
ssh-keygen -t rsa
ssh-copy-id justin@hadoop101
ssh-copy-id root@hadoop101
ssh-copy-id justin@hadoop102
ssh-copy-id root@hadoop102
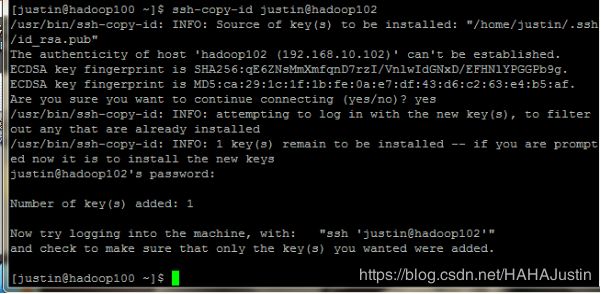
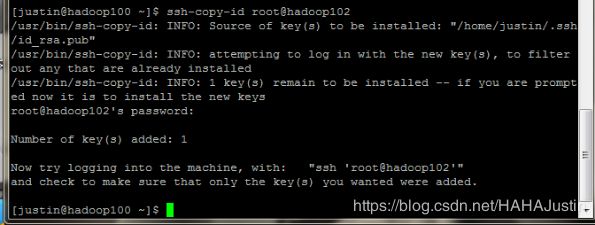
注意:需要输入从机账户的密码。
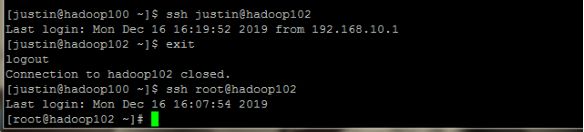
测试SSH免密钥登录是否成功。(以hadoop102为例)
ssh justin@hadoop102
ssh root@hadoop102
5.Hadoop的安装与配置
5.1下载与解压安装
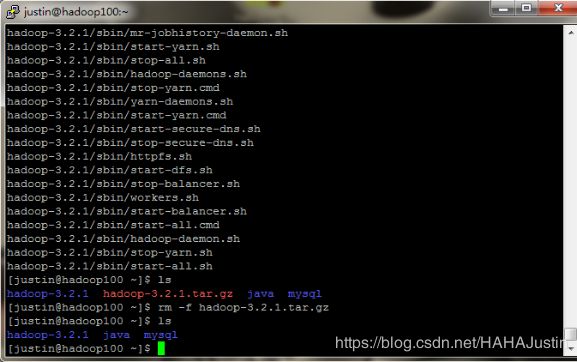
在网上找到hadoop-3.2.1的下载地址,利用curl命令进行下载并解压安装。(也可以直接下载安装包,用WinSCP传送到指定目录)。为节约磁盘空间,使用rm命令将安装包删除。
cd ~
curl -O https://www-us.apache.org/dist/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
tar -zvxf hadoop-3.2.1.tar.gz
rm -f hadoop-3.2.1.tar.gz

5.2目录规划
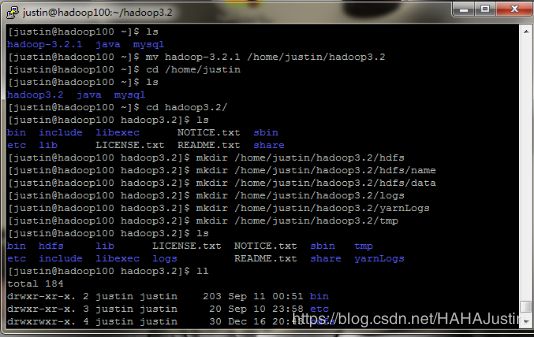
为方便操作,先将文件夹(hadoop-3.2.1)重命名,再进入该文件夹,按照主程序,集群数据,文件系统元数据,真正的数据,日志信息,临时文件的顺序依次创建相应的文件夹。
mv hadoop-3.2.1 /home/justin/hadoop3.2
cd /home/justin/hadoop3.2
mkdir /home/justin/hadoop3.2/hdfs
mkdir /home/justin/hadoop3.2/hdfs/name
mkdir /home/justin/hadoop3.2/hdfs/data
mkdir /home/justin/hadoop3.2/logs
mkdir /home/justin/hadoop3.2/yarnLogs
mkdir /home/justin/hadoop3.2/tmp
5.3环境配置
(1)进入系统目录配置环境变量。(需要sudo权限)
sudo vi /etc/profile

注意:重启生效也可使用命令(source /etc/profile)立即生效。
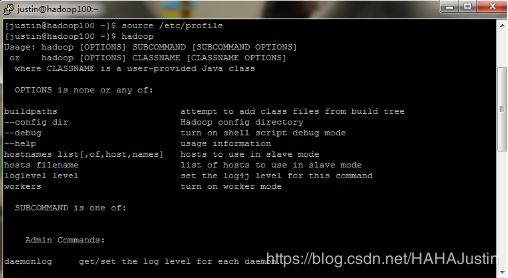
测试hadoop是否配置成功:
(2)修改Hadoop配置文件,修改hadoop-env.sh, yarn-env.sh, mapred-env.sh,分别插入下列代码。
cd $HADOOP_HOME/etc/hadoop
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh

vi $HADOOP_HOME/etc/hadoop/yarn-env.sh
![]()
vi $HADOOP_HOME/etc/hadoop/mapred-env.sh
![]()
(3)修改workers
vi $HADOOP_HOME/etc/hadoop/workers
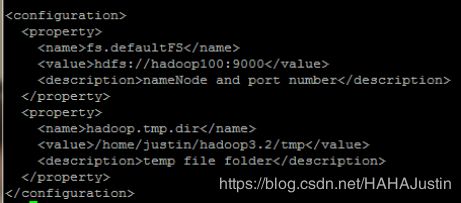
(4)配置core-site.xml
vi $HADOOP_HOME/etc/hadoop/core-site.xml
(5)配置hdfs-site.xml
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml

(6)配置mapred-site.xml
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
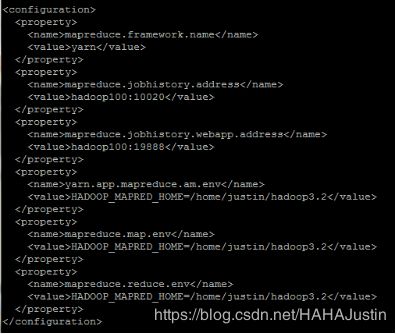
(7)配置yarn-site.xml
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
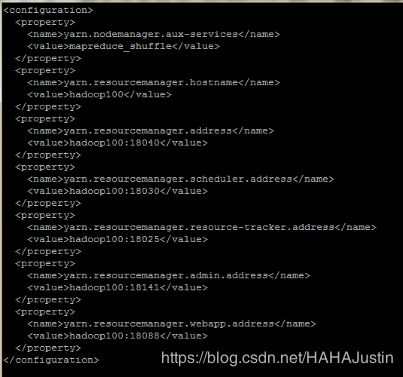
5.4集群测试
由于之前已经完成了SSH免密登录,所以可以将主机(hadoop100)的hadoop利用scp命令传送到各台从机上(hadoop101、hadoop102)。
scp -r /home/justin/hadoop3.2 hadoop101:~/
scp -r /home/justin/hadoop3.2 hadoop102:~/
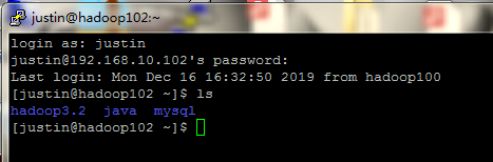
传送完毕,登录hadoop102查看目录下是否产生文件。
注意:第一次运行hadoop需要用命令对hdfs进行初始化。
hdfs namenode -format
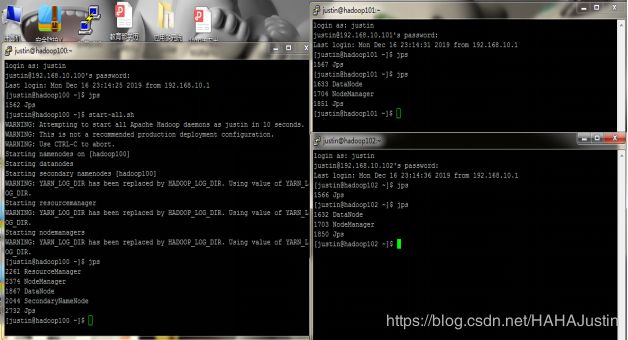
start-all.sh
注意:若不成功检查具体出错原因。1.是环境变量配置有误,2.免密没有做好需要重新做免密(主机自己也可以和自己做免密)。3.修改文件夹权限(chmod 777 -R /home/justin/hadoop3.2/logs)。
集群运行成功如图所示:
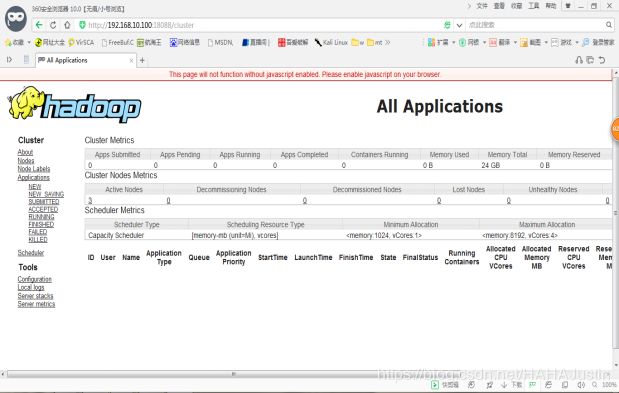
6.Zookeeper的安装与配置
6.1下载安装与配置
注意:zookeeper集群有个特点,半数以上节点存活整个集群就能正常提供服务。通常集群数量设置为奇数个。
在网上找到zookeeper-3.4.14的下载地址,利用curl命令进行下载并解压安装。(也可以直接下载安装包,用WinSCP传送到指定目录)。为节约磁盘空间,使用rm命令将安装包删除。最后在文件夹中创建相应的文件夹。
cd ~
curl -O https://www-us.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
tar -xzvf zookeeper-3.4.14.tar.gz
rm -rf zookeeper-3.4.14.tar.gz
cd zookeeper-3.4.14
mkdir data
mkdir logs
(1)进入系统目录配置环境变量。(需要sudo权限)
sudo vi /etc/profile

注意:重启生效也可使用命令(source /etc/profile)立即生效。
(2)配置zookeeper相关环境文件:
vi conf/zoo.cfg
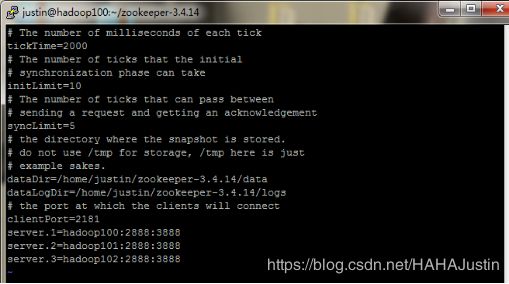
注意:各台机对应的服务器id号要记好,之后配置时需要声明。
(3)利用scp命令将zookeeper传送的其他从机上。
scp -r $ZOOKEEPER justin@hadoop101:/home/justin/zookeeper-3.4.14
scp -r $ZOOKEEPER justin@hadoop102:/home/justin/zookeeper-3.4.14
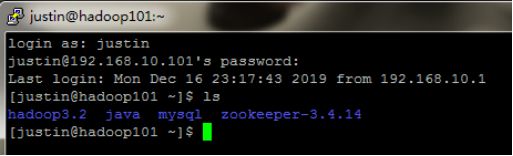
(4)配置主机id
进入zookeeper中data文件夹,声明自己的主机id。
注意:id号要与配置文件中的相同。
注意:配置完成后可用命令(cat myid)查看是否会返回自己的id号。
cd ~/zookeeper-3.4.14/data
echo “1” > myid

6.2从机配置
注意:从机也需要配置/etc/profile中的环境变量(也可以用scp命令从主机传送过来,传送后同样需要source /etc/profile)。
scp -r /etc/profile root@hadoop101:/etc/profile
scp -r /etc/profile root@hadoop102:/etc/profile
各台从机设置在配置文件中声明的相应id号。
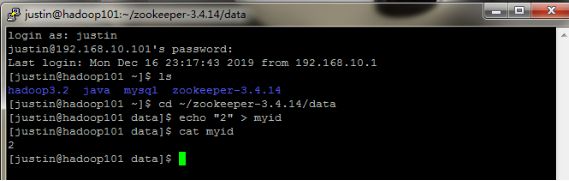
cd ~/zookeeper-3.4.14/data
hadoop101(worker1):
echo “2” > myid*
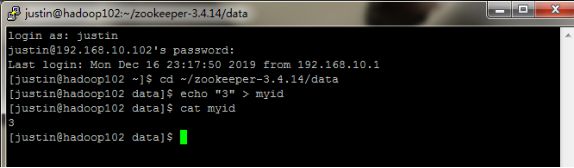
hadoop102(worker2):
echo “3” > myid
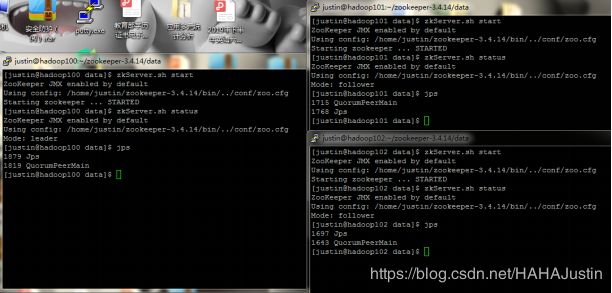
6.3集群测试
注意:zookeeper选择leader的模式简单概括为“少数服从多数”,具体可网上查阅资料。
基本命令:
zkServer.sh start #启动
zkServer.sh stop #停止
zkServer.sh status #查询节点状态
7.Scala的安装与配置
在网上找到scala-2.13.1的下载地址,利用curl命令进行下载并解压安装。(也可以直接下载安装包,用WinSCP传送到指定目录)。为节约磁盘空间,使用rm命令将安装包删除。
cd ~
curl -O https://downloads.lightbend.com/scala/2.13.1/scala-2.13.1.tgz
tar -zxvf scala-2.13.1.tgz
rm -f scala-2.13.1.tgz
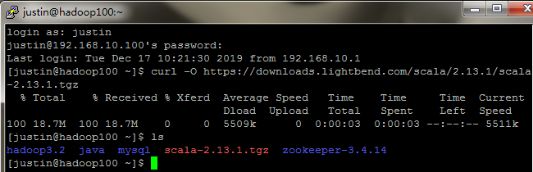
进入系统目录配置环境变量。(需要sudo权限)
sudo vi /etc/profile

注意:重启生效也可使用命令(source /etc/profile)立即生效。
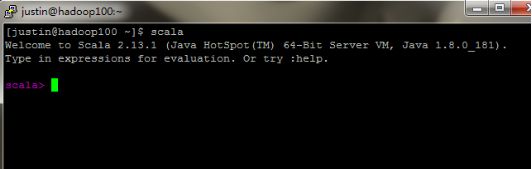
执行scala命令,输出以下信息,表示安装成功:
利用scp命令将scala传送的其他从机上。
scp -r ~/scala-2.13.1 justin@hadoop101:~/scala-2.13.1
scp -r ~/scala-2.13.1 justin@hadoop102:~/scala-2.13.1

注意:从机也需要配置/etc/profile中的环境变量(也可以用scp命令从主机传送过来,传送后同样需要source /etc/profile)。
scp -r /etc/profile root@hadoop101:/etc/profile
scp -r /etc/profile root@hadoop102:/etc/profile
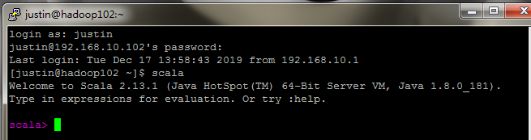
从机成功运行:
8.HBase的安装与配置
8.1下载及安装
在网上找到HBase-2.2.2的下载地址,利用curl命令进行下载并解压安装。(也可以直接下载安装包,用WinSCP传送到指定目录)。为节约磁盘空间,使用rm命令将安装包删除。
cd ~
curl -O https://www-eu.apache.org/dist/hbase/2.2.2/hbase-2.2.2-bin.tar.gz
tar -zxvf hbase-2.2.2-bin.tar.gz
rm -rf hbase-2.2.2-bin.tar.gz

8.2环境配置
(1)进入系统目录配置环境变量。(需要sudo权限)
sudo vi /etc/profile

注意:重启生效也可使用命令(source /etc/profile)立即生效。
(2)配置hbase-env.sh
vi $HBASE_HOME/conf/hbase-env.sh

注意:其实HBase里面自带了一个zookeeper,而HBASE_MANAGES_ZK的值就是是否使用这个自带的zookeeper,很显然这里要使用自己的zookeeper,所以修改为false。
(3)配置hbase-site.xml
vi $HBASE_HOME/conf/hbase-site.xml
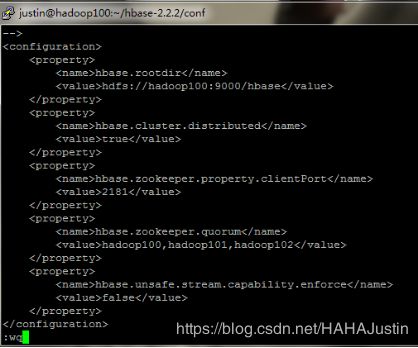
(4)配置regionservers
删除locahost,添加所有hbase从节点的主机名。
vi $HBASE_HOME/conf/regionservers
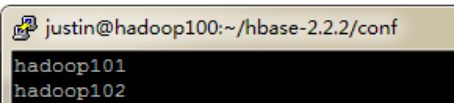
(5)利用scp命令将HBase传送的其他从机上。
scp -r $HBASE_HOME justin@hadoop101:/home/justin/hbase-2.2.2
scp -r $HBASE_HOME justin@hadoop102:/home/justin/hbase-2.2.2
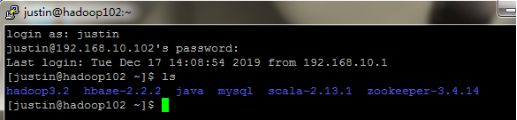
8.3集群测试
注意:从机也需要配置/etc/profile中的环境变量(也可以用scp命令从主机传送过来,传送后同样需要source /etc/profile)。
scp -r /etc/profile root@hadoop101:/etc/profile
scp -r /etc/profile root@hadoop102:/etc/profile
注意:确保hadoop,zookeeper已经正常启动的情况下才能启动HBase。
启动hbase:
start-hbase.sh

其他参考命令
start-all.sh #启动hadoop
zkServer.sh start #启动zookeeper
zkServer.sh status #查看zookeeper状态
hbase-daemon.sh start regionserver # start HBase Region Serve
hbase-daemon.sh stop regionserver # stop HBase Region Serve
9.Hive的安装与配置
9.1Hive安装及配置
在网上找到Hive-3.1.2的下载地址,利用curl命令进行下载并解压安装。(也可以直接下载安装包,用WinSCP传送到指定目录)。为节约磁盘空间,使用rm命令将安装包删除。
cd ~
curl -O https://www-eu.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
tar -zxvf apache-hive-3.1.2-bin.tar.gz
rm -f apache-hive-3.1.2-bin.tar.gz
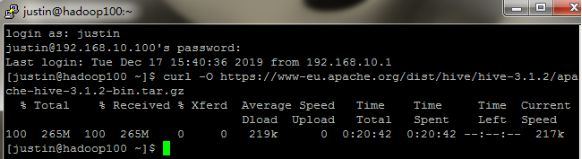
(1)为方便操作,先将文件夹(apache-hive-3.1.2-bin)重命名。
mv apache-hive-3.1.2-bin hive3.1
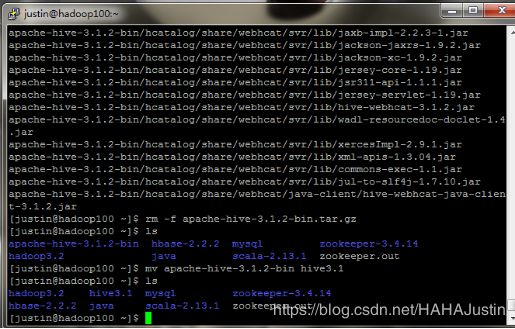
(2)进入系统目录配置环境变量。(需要sudo权限)
sudo vi /etc/profile

注意:重启生效也可使用命令(source /etc/profile)立即生效。
(3)配置hive-env.sh
进入conf目录,配置hive-env.sh。
cd $HIVE_HOME/conf
vi hive-env.sh
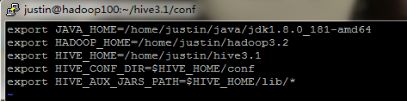
(4)配置hive-site.xml
首先创建tmp文件夹,然后配置hive-site.xml。
mkdir $HIVE_HOME/tmp
vi hive-site.xml
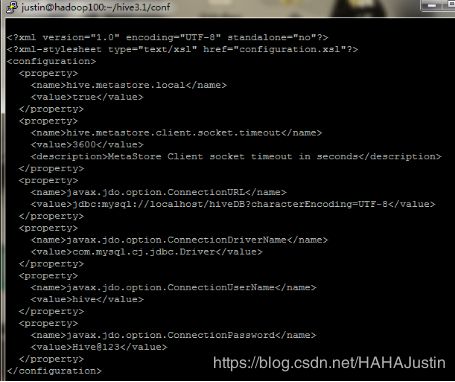
(5)配置hive-log4j2.properties。
首先创建logs文件夹,然后配置hive-log4j2.properties(由hive-log4j2.properties.template复制而来)。
mkdir $HIVE_HOME/logs
cd $HIVE_HOME/conf
cp hive-log4j2.properties.template hive-log4j2.properties
vi hive-log4j2.properties
注意:修改一处。(property.hive.log.dir = $HIVE_HOME/logs)

9.2MySQL配置
(1)下载MySQL驱动到lib目录下
cd $HIVE_HOME/lib
curl -O -L http://central.maven.org/maven2/mysql/mysql-connector-java/8.0.17/mysql-connector-java-8.0.17.jar

注意:curl -L参数会让HTTP请求跟随服务器的重定向。curl默认不跟随重定向。
(2)登录MySQL(root账号),创建Hive账户并授予权限,最后刷新权限。
mysql -u root -p
CREATE USER ‘hive’@‘localhost’ IDENTIFIED BY ‘Hive@123’;
CREATE USER ‘hive’@’%’ IDENTIFIED BY ‘Hive@123’;
GRANT ALL ON . TO ‘hive’@‘localhost’;
GRANT ALL ON . TO ‘hive’@’%’;
FLUSH PRIVILEGES;
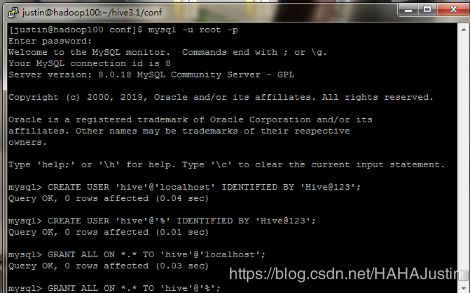
注意:mysql中操作语句需要“ ;”。
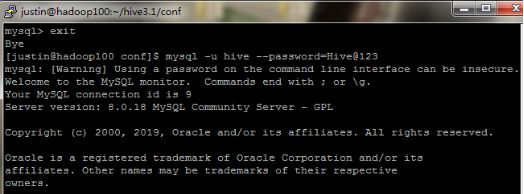
(3)登录Hive账户
mysql -u hive --password=Hive@123
create database hiveDB;
SHOW DATABASES;
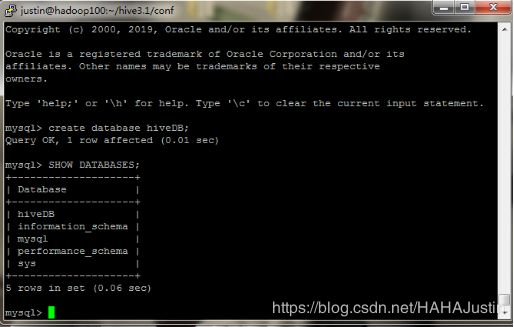
9.3Hive初始化及启动
初始化,执行下面命令:
schematool -dbType mysql -initSchema
注意:Hive只要在一台hadoop集群的服务器上安装即可。
注意:启动Hive之前要保证hadoop已经正常启动
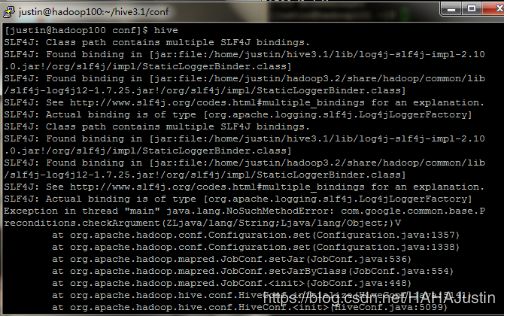
注意:运行出现上图问题,是因为找到了两处jar包,分别是在Hadoop和Hive的安装目录。错误原因是guava.jar包在两个位置版本不同。解决办法为对比两个目录下的jar包,删除版本较低的jar包,用高版本的替代。(可以使用WinSCP可视化操作更简单)

Hive成功运行:
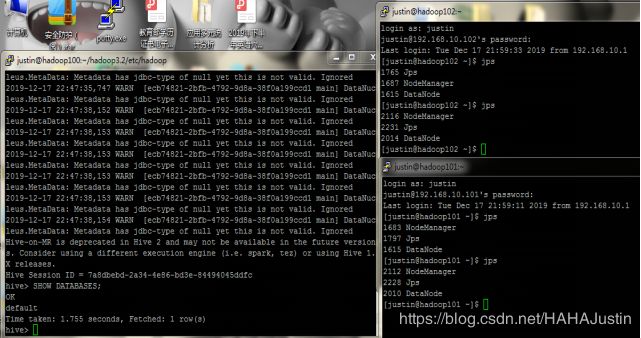
注意:mysql服务器需要启动。
注意:hdfs需要初始化。
注意:hive需要初拟化。