【深度学习】经典神经网络 VGG 论文解读
VGG 在深度学习领域中非常有名,很多人 fine-tune 的时候都是下载 VGG 的预训练过的权重模型,然后在次基础上进行迁移学习。VGG 是 ImageNet 2014 年目标定位竞赛的第一名,图像分类竞赛的第二名,需要注意的是,图像分类竞赛的第一名是大名鼎鼎的 GoogLeNet,那么为什么人们更愿意使用第二名的 VGG 呢?
因为 VGG 够简单
VGG 是 Visual Geometry Group 的缩写,是这个网络创建者的队名,作者来自牛津大学。
VGG 最大的特点就是它在之前的网络模型上,通过比较彻底地采用 3x3 尺寸的卷积核来堆叠神经网络,从而加深整个神经网络的层级。
VGG 不是横空出世
我们都知道,最早的卷积神经网络 LeNet,但 2012 年 Krizhevsk 在 ISRVC 上使用的 AlexNet 一战成名,极大鼓舞了世人对神经网络的研究,后续人们不断在 AlexNet 的架构上进行改良,并且成绩也越来越好。
下面是 AlexNet 的网络结构图。
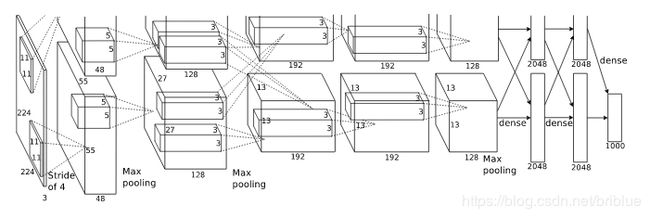
对于 AlexNet 的改进的手段有 2 个:
- 在第一层卷积层上采用感受野更小的的尺寸,和更小的 stride。
- 在 AlexNet 的基础上加深它的卷积层数量。
VGG 选择的是在 AlexNet 的基础上加深它的层数,但是它有个很显著的特征就是持续性的添加 3x3 的卷积核。
VGG 的网络结构
VGG 更多是被试验出来的,这是我最直观的看法
AlexNet 的改造
AlexNet 有 5 层卷积层,而 VGG 就是针对这 5 层卷积层进行改造,共进行了 6 种配置,得到了 6 中网络结构,下面是配置图。
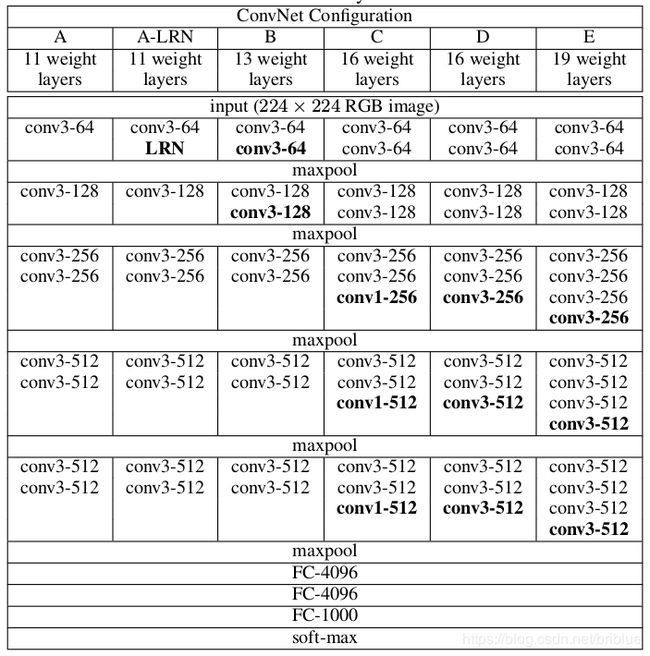
VGG 的细节之 3x3 卷积核
VGG 和 AlexNet 最大的不同就是 VGG 用大量的 3x3 卷积核替换了 AlexNet 的卷积核。
3x3 卷积核是能够感受到上下、左右、重点的最小的感受野尺寸。
并且,2 个 3x3 的卷积核叠加,它们的感受野等同于 1 个 5x5 的卷积核,3 个叠加后,它们的感受野等同于 1 个 7x7 的效果
既然,感受野的大小是一样的,那么用 3x3 有什么好处呢?
答案有 2,一是参数更少,二是层数加深了。
现在解释参数变少的问题。
假设现在有 3 层 3x3 卷积核堆叠的卷积层,卷积核的通道是 C 个,那么它的参数总数是 3x(3Cx3C) = 27C^2
同样和它感受野大小一样的一个卷积层,卷积核是 7x7 的尺寸,通道也是 C 个,那么它的参数总数就是 49C^2
通过计算很容易得出结论,3x3 卷积方案的参数数量比 7x7 方案少了 81% 多,并且它的层级还加深了。
VGG 的细节之 1x1 卷积核
堆叠后的 3x3 卷积层可以对比之前的常规网络的基础上,减少参数数量,而加深网络。
但是,如果我们还需要加深网络,怎么办呢?
堆叠更多的的卷积层,但有 2 个选择。
选择 1:继续堆叠 3x3 的卷积层,比如连续堆叠 4 层或者以上。
选择 2:在 3x3 的卷积层后面堆叠一层 1x1 的卷积层。
1x1 卷积核的好处是不改变感受野的情况下,进行升维和降维,同时也加深了网络的深度。
详情,请参考我的这篇博文。【深度学习】CNN 中 1x1 卷积核的作用
VGG 其它细节汇总
大家一般会听说 VGG-16 和 VGG-19 这两个网络,其中 VGG-16 更受欢迎。
16 和 19 对应的是网络中包含权重的层级数,如卷积层和全连接层,大家可以仔细观察文章前面贴的配置图信息。
所有的 VGG 网络中,卷积核的 stride 是 1,padding 是 1.
max-pooling 的滑动窗口大小是 2x2 ,stride 也是 2.
VGG 不同配置的表现

VGG-19 表现的结果自然最好。
但是,VGG-19 的参数比 VGG-16 的参数多了好多。

所以,综合考虑大家似乎更喜欢 VGG-16。
VGG 与其他模型的比较
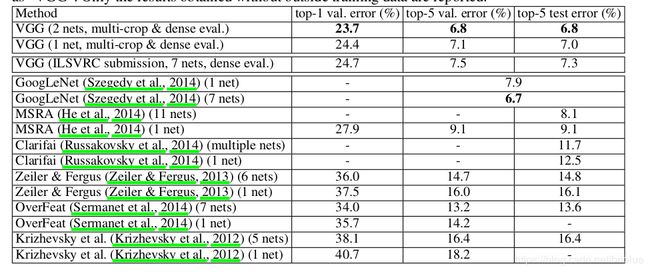
VGG 在当时非常优秀,仅次于 GoogLeNet,但 VGG 结构更简单易懂。
总结
VGG 在深度学习的历史上还是很有意义的,它在当时证明了神经网络更深表现会更好,虽然后来 ResNet 进一步革命了,不过那是后话,最重要的是 VGG 向世人证明了更小的卷积核尺寸的重要性。