第12章 电子商务网站用户行为分析及服务推荐
八十几万条的数据,第一次让我感觉到了小笔记本是多么的不给力。个人想要学习大数据真是从开始就很难啊。磕磕碰碰总算把这一章中的主要代码全都弄出来了。下面就开始。
为了避免在中间插入太多代码造成内容本身零落,所以代码请至我的个人博客中中自行下载。
背景与挖掘目标
推荐系统和搜索引擎的不同在于,推荐系统不需要用户提供明确的要求,而是通过分析用户的历史行为,从而主动想用户推荐能够满足他们兴趣和需求的信息。
分析方法与过程
通过协同过滤算法进行推荐。而最主要的问题在于:数据量太大以为物品数与用户数很多,在构件用户和物品的稀疏矩阵时,会出现设备内存不够的情况。
分析的过程主要包括:
- 从系统中获取用户访问网站的原始记录。(这一点已经提供给我们)
- 对数据进行多维度分析。
- 对数据进行预处理。
- 对用户防卫的html页面进行数据处理
利用多种算法进行推荐,进行模型评价。(暂时我只做了一种推荐)
2.1 数据探索和抽取
这是我花费最多时间的部分,原因有几个。- 首先,pandas处理这么大数据量时只能分次读取,然后再进行合并,相当的耗费时间。
- 其次,我利用了sql和pandas两种方法进行这一部分工作,所以,下面的内容会有一些代码和结果的对比。
- 最后,确实对于复杂的sql和pandas的数据抽取方法不够熟悉,花费了很多时间。
开始需要安装MariaDB并且导入sql文件。开始我导入很多次都提示失败,一直也没找到原因,试了好几次以后突然就成功了。所以,如果你导入不了,那就多试几次吧。
因为过程中会多次进行各种切片抽取,会爆出很多提示错误,所以输入以下代码,忽略所有警告。
import warnings
warnings.filterwarnings("ignore")导入方法同书中代码,不再赘述。我这里读取一次大概需要一分多钟,确实很慢。
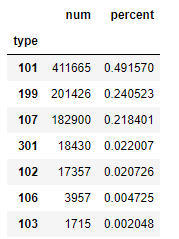
可以和书中的结果是一致的。这一段书中代码也没有什么问题。
基本也是同样的方法,可以获取101类型各种网页的比例。
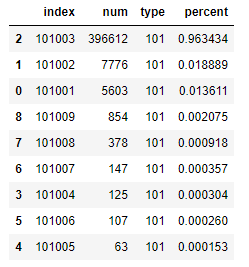
随后是对107类型网页进行分块的统计。
有朋友会在这里遇到一个问题,counts2始终获取不到值。这是因为sql是一个生成器类型,所以在使用过一次以后,就不能继续使用了。必须要重新执行一次读取。

可以看到,结果与书上的表12-5也是一致的。
随后书上也就没有提供代码了,我们可以看一下包含?的网页。其实方法和前面的都一样,最后结果如下。
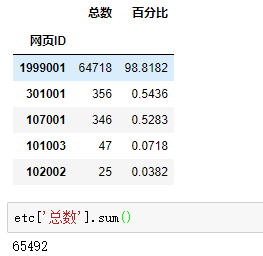
与书中的表12-6的结果也是一致的。但是在这里我引入了用sql进行查询的方法来验证结果。过程中我发现,sql进行这一类的数据探索的过程,远远比pandas要快很多。
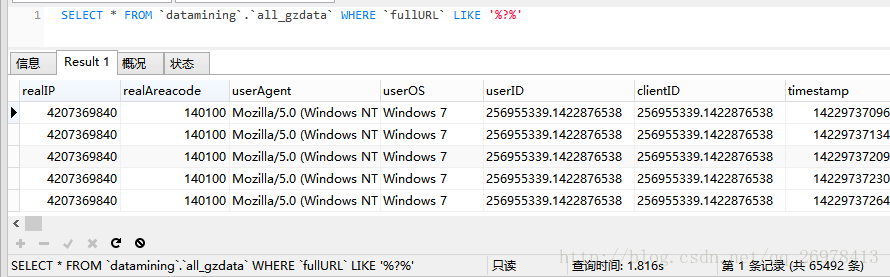
看看这个结果,速度只需要2秒不到,而pandas连读取都没有完成呢。
上面的结果展示了分类筛选pandas和sql的对比,在对其他类型中的分类统计,我们再来看下汇总为百分比以后的结果。
这是pandas计算的结果

这是sql计算的结果
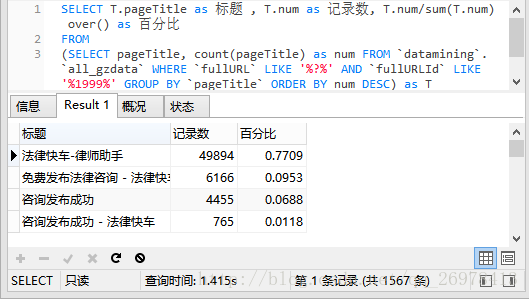
看出也是两者结果相同,并且与书中表12-7是相同的,而sql只用时1.41秒。这比pd.concat所花费的时间还要短。
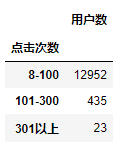
在瞎逛类型的统计中,书中也没有给出代码,而且给出的统计方法也很简略,所以做出的结果也有所不同。不知道有没有大神做出了相似的结果。
页面点击次数的统计中,也做了pandas和sql进行的对比。
pandas执行的结果

sql执行的结果
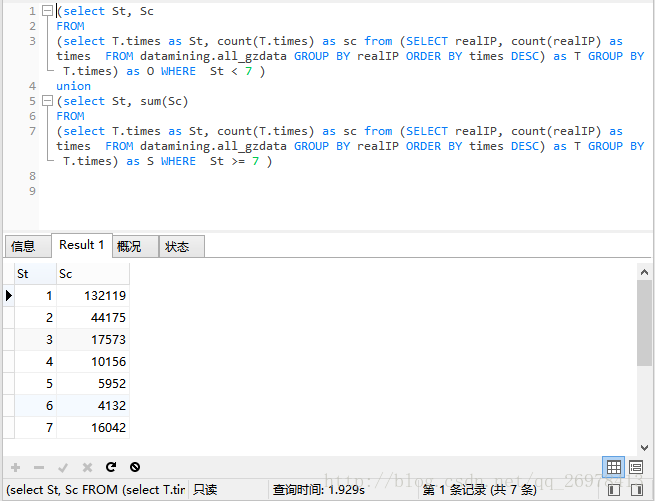
可见均与书中表12-9是一致的。
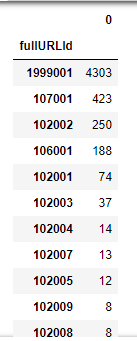
随后,是对点击次数的网页进行分类。
可见这里的结果与书中表12-10的结果并不一样,原因我找了很久也没找到。因为我认为书中结果可能有错误。
因为随后的数据探索内容,基本都比较简单,而且在后文中也没有实际用到,我就没有进行实验了。不过都不是太难的代码。
不过整篇文章中,数据探索阶段其实是最花时间的,不过在这过程中确实对pandas的数据抽取方法有了进一步的训练。同时我认为,对于实际工作而言,探索工作可以利用sql的方式进行,可以节约很多时间。所以,学习sql各种统计方法可以说是必须的。
2.2 数据清洗
表12-16 规则清洗表基本是对上面工作的一个汇总,我没有进行重现。结果应该是有所不同的。
cleaned_gzdata 和 changed_gzdata采用书中的代码,说实话,不如在数据库工具中操作起来快。
splited_gzdata书中代码提供的比较少,如果光只用书中的代码,后面的工作可能就没法做了。所以自己进行调整后。获得splited_gzdata表。
至此,数据的准备工作算是完成了。
2.3 推荐算法的实现
由于机器实在不给力,我试过跑了几次用全部数据进行R矩阵的生成,全都最后以无响应为结局。
在这里也就体现了,本文开始所说的 最主要的问题在于:数据量太大以为物品数与用户数很多,在构件用户和物品的稀疏矩阵时,会出现设备内存不够的情况。
所以,我只选取了1万条数据做了一个较为简略的测试,不过过程是相似的,如果用更好的机器和更多的时间,应该还是可以做出结果的。
书中给出的jaccard和recommender的代码,我认为都有一点问题,所以我进行了重写。

看下结果,说实话,这远没有之前几讲的内容直观。无法直接看出结果是否正确。
- 模型评价部分
因为这一篇的模型评价是多个推荐算法的对比,并且评价指标所用的数据好像也没有给出,所以我这里就没有做了,如果有大神做了,拜托给出链接参考学习。
总结:
本章的难度感觉还是高于前几章内容的,对pandas的各种功能和用法需要比较熟悉。协同推荐算法本身不算困难,不过如果没有demo参考的情况下,感觉自己也还是写不出来的。