OpenCV实战5: LBP级联分类器实现人脸检测
OpenCV中的HAAR与LBP数据
HAAR特征数据 参看 haarcascade_frontalface_alt.xml 各标签
LBP特征数据 参看 lbpcascade_frontalface.xml 各标签
HAAR与LBP的区别:
HAAR特征是浮点数计算
LBP特征是整数计算
LBP训练需要的样本数量要比HAAR大
同样的样本空间, HAAR训练出来的数据检测结果要比LBP准确
扩大LBP的样本数据,训练结果可以跟HAAR一样
LBP的速度一般可以比HAAR快几倍
LBP特征的背景介绍
LBP指局部二值模式,英文全称:Local Binary Pattern,是一种用来描述图像局部特征的算子,LBP特征具有灰度不变性和旋转不变性等显著优点。它是由T. Ojala, M.Pietikäinen, 和 D. Harwood在1994年提出,由于LBP特征计算简单、效果较好,因此LBP特征在计算机视觉的许多领域都得到了广泛的应用,LBP特征比较出名的应用是用在人脸识别和目标检测中,LBP提取局部特征作为判别依据,LBP方法显著的优点是对光照不敏感,但是依然没有解决姿态和表情的问题。不过相比于特征脸方法,LBP的识别率已经有了很大的提升。在计算机视觉开源库OpenCV中有使用LBP特征进行人脸识别的接口,也有用LBP特征训练目标检测分类器的方法,Opencv实现了LBP特征的计算,但没有提供一个单独的计算LBP特征的接口。
LBP特征的原理
1、原始LBP特征描述及计算方法
原始的LBP算子定义在像素3*3的邻域内,以邻域中心像素为阈值,相邻的8个像素的灰度值与邻域中心的像素值进行比较,若周围像素大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经过比较可产生8位二进制数,将这8位二进制数依次排列形成一个二进制数字,这个二进制数字就是中心像素的LBP值(通常转换为十进制数即LBP码,共256种)。中心像素的LBP值反映了该像素周围区域的纹理信息。
计算LBP特征的图像必须是灰度图,如果是彩色图,需要先转换成灰度图。
上述过程用图像表示为:

用比较正式的公式来定义的话:
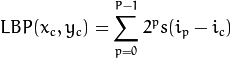
其中 代表3x3邻域的中心元素,它的像素值为ic,ip代表邻域内其他像素的值。s(x)是符号函数,定义如下:
代表3x3邻域的中心元素,它的像素值为ic,ip代表邻域内其他像素的值。s(x)是符号函数,定义如下:

原始LBP特征计算代码(Opencv下):
//原始LBP特征计算
template
void getOriginLBPFeature(InputArray _src,OutputArray _dst)
{
Mat src = _src.getMat();
_dst.create(src.rows-2,src.cols-2,CV_8UC1);
Mat dst = _dst.getMat();
dst.setTo(0);
for(int i=1;i(i,j);
unsigned char lbpCode = 0;
lbpCode |= (src.at<_tp>(i-1,j-1) > center) << 7;
lbpCode |= (src.at<_tp>(i-1,j ) > center) << 6;
lbpCode |= (src.at<_tp>(i-1,j+1) > center) << 5;
lbpCode |= (src.at<_tp>(i ,j+1) > center) << 4;
lbpCode |= (src.at<_tp>(i+1,j+1) > center) << 3;
lbpCode |= (src.at<_tp>(i+1,j ) > center) << 2;
lbpCode |= (src.at<_tp>(i+1,j-1) > center) << 1;
lbpCode |= (src.at<_tp>(i ,j-1) > center) << 0;
dst.at(i-1,j-1) = lbpCode;
}
}
}
LBP算子利用了周围点与该点的关系对该点进行量化。量化后可以更有效地消除光照对图像的影响。只要光照的变化不足以改变两个点像素值之间的大小关系,那么LBP算子的值不会发生变化,所以一定程度上,基于LBP的识别算法解决了光照变化的问题,但是当图像光照变化不均匀时,各像素间的大小关系被破坏,对应的LBP模式也就发生了变化。
二、LBP特征的改进版本
在原始的LBP特征提出以后,研究人员对LBP特征进行了很多的改进,因此产生了许多LBP的改进版本。
2.1 圆形LBP特征(Circular LBP or Extended LBP)
由于原始LBP特征使用的是固定邻域内的灰度值,因此当图像的尺度发生变化时,LBP特征的编码将会发生错误,LBP特征将不能正确的反映像素点周围的纹理信息,因此研究人员对其进行了改进。基本的 LBP 算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,只局限在3*3的邻域内,对于较大图像大尺度的结构不能很好的提取需要的纹理特征,因此研究者们对LBP算子进行了扩展。
新的LBP算子LBP(P,R) 可以计算不同半径邻域大小和不同像素点数的特征值,其中P表示周围像素点个数,R表示邻域半径,同时把原来的方形邻域扩展到了圆形,下图给出了四种扩展后的LBP例子,其中,R可以是小数,对于没有落到整数位置的点,根据轨道内离其最近的两个整数位置像素灰度值,利用双线性差值的方法可以计算它的灰度值:
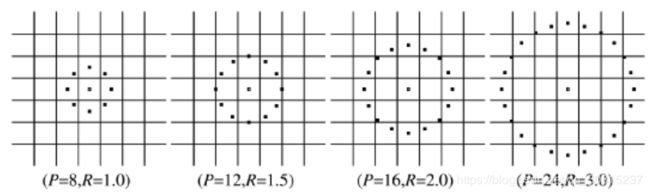
这种LBP特征叫做Extended LBP,也叫Circular LBP。使用可变半径的圆对近邻像素进行编码,可以得到如下的近邻:
通过LBP特征的定义可以看出,LBP特征对光照变化是鲁棒的,其效果如下图所示:

//圆形LBP特征计算,效率优化版本,声明时默认neighbors=8
template
void getCircularLBPFeatureOptimization(InputArray _src,OutputArray _dst,int radius,int neighbors)
{
Mat src = _src.getMat();
//LBP特征图像的行数和列数的计算要准确
_dst.create(src.rows-2*radius,src.cols-2*radius,CV_8UC1);
Mat dst = _dst.getMat();
dst.setTo(0);
for(int k=0;k(radius * cos(2.0 * CV_PI * k / neighbors));
float ry = -static_cast(radius * sin(2.0 * CV_PI * k / neighbors));
//为双线性插值做准备
//对采样点偏移量分别进行上下取整
int x1 = static_cast(floor(rx));
int x2 = static_cast(ceil(rx));
int y1 = static_cast(floor(ry));
int y2 = static_cast(ceil(ry));
//将坐标偏移量映射到0-1之间
float tx = rx - x1;
float ty = ry - y1;
//根据0-1之间的x,y的权重计算公式计算权重,权重与坐标具体位置无关,与坐标间的差值有关
float w1 = (1-tx) * (1-ty);
float w2 = tx * (1-ty);
float w3 = (1-tx) * ty;
float w4 = tx * ty;
//循环处理每个像素
for(int i=radius;i(i,j);
//根据双线性插值公式计算第k个采样点的灰度值
float neighbor = src.at<_tp>(i+x1,j+y1) * w1 + src.at<_tp>(i+x1,j+y2) *w2 \
+ src.at<_tp>(i+x2,j+y1) * w3 +src.at<_tp>(i+x2,j+y2) *w4;
//LBP特征图像的每个邻居的LBP值累加,累加通过与操作完成,对应的LBP值通过移位取得
dst.at(i-radius,j-radius) |= (neighbor>center) <<(neighbors-k-1);
}
}
}
}
2.2 旋转不变LBP特征
从上面可以看出,上面的LBP特征具有灰度不变性,但还不具备旋转不变性,因此研究人员又在上面的基础上进行了扩展,提出了具有旋转不变性的LBP特征。首先不断的旋转圆形邻域内的LBP特征,根据选择得到一系列的LBP特征值,从这些LBP特征值选择LBP特征值最小的作为中心像素点的LBP特征。具体做法如下图所示:
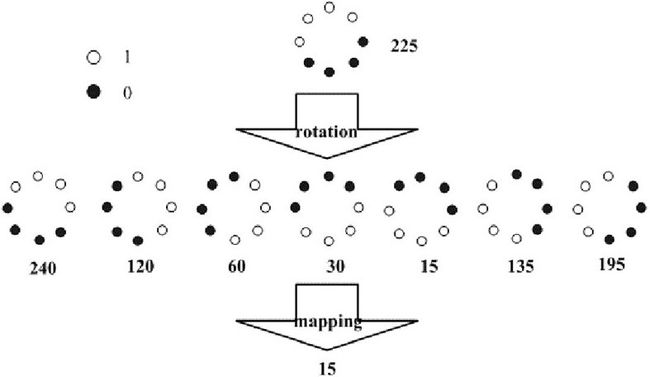
假设一开始得到的LBP特征为10010000,那么将这个二进制特征,按照顺时针方向旋转,可以转化为00001001的形式,这样得到的LBP值是最小的。无论图像怎么旋转,对点提取的二进制特征的最小值是不变的,用最小值作为提取的LBP特征,这样LBP就是旋转不变的了。当P=8时,能产生的不同的二进制特征数量是2^8个,经过上述表示,就变为36个。(我以为应当是2^8/8=32个)
//旋转不变圆形LBP特征计算,声明时默认neighbors=8
template
void getRotationInvariantLBPFeature(InputArray _src,OutputArray _dst,int radius,int neighbors)
{
Mat src = _src.getMat();
//LBP特征图像的行数和列数的计算要准确
_dst.create(src.rows-2*radius,src.cols-2*radius,CV_8UC1);
Mat dst = _dst.getMat();
dst.setTo(0);
for(int k=0;k(radius * cos(2.0 * CV_PI * k / neighbors));
float ry = -static_cast(radius * sin(2.0 * CV_PI * k / neighbors));
//为双线性插值做准备
//对采样点偏移量分别进行上下取整
int x1 = static_cast(floor(rx));
int x2 = static_cast(ceil(rx));
int y1 = static_cast(floor(ry));
int y2 = static_cast(ceil(ry));
//将坐标偏移量映射到0-1之间
float tx = rx - x1;
float ty = ry - y1;
//根据0-1之间的x,y的权重计算公式计算权重,权重与坐标具体位置无关,与坐标间的差值有关
float w1 = (1-tx) * (1-ty);
float w2 = tx * (1-ty);
float w3 = (1-tx) * ty;
float w4 = tx * ty;
//循环处理每个像素
for(int i=radius;i(i,j);
//根据双线性插值公式计算第k个采样点的灰度值
float neighbor = src.at<_tp>(i+x1,j+y1) * w1 + src.at<_tp>(i+x1,j+y2) *w2 \
+ src.at<_tp>(i+x2,j+y1) * w3 +src.at<_tp>(i+x2,j+y2) *w4;
//LBP特征图像的每个邻居的LBP值累加,累加通过与操作完成,对应的LBP值通过移位取得
dst.at(i-radius,j-radius) |= (neighbor>center) <<(neighbors-k-1);
}
}
}
//进行旋转不变处理
for(int i=0;i(i,j);
unsigned char minValue = currentValue;
for(int k=1;k>(neighbors-k)) | (currentValue<(i,j) = minValue;
}
}
}
2.3 Uniform Pattern LBP特征
Uniform Pattern,也被称为等价模式或均匀模式,由于一个LBP特征有多种不同的二进制形式,对于半径为R的圆形区域内含有P个采样点的LBP算子将会产生2^P种模式。很显然,随着邻域集内采样点数的增加,二进制模式的种类是以指数形式增加的。例如:5×5邻域内20个采样点,有2^20=1,048,576种二进制模式。这么多的二进制模式不利于纹理的提取、分类、识别及存取。例如,将LBP算子用于纹理分类或人脸识别时,常采用LBP模式的统计直方图来表达图像的信息,而较多的模式种类将使得数据量过大,且直方图过于稀疏。因此,需要对原始的LBP模式进行降维,使得数据量减少的情况下能最好的表示图像的信息。
为了解决二进制模式过多的问题,提高统计性,Ojala提出了采用一种“等价模式”(Uniform Pattern)来对LBP算子的模式种类进行降维。Ojala等认为,在实际图像中,绝大多数LBP模式最多只包含两次从1到0或从0到1的跳变。因此,Ojala将“等价模式”定义为:当某个LBP所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该LBP所对应的二进制就称为一个等价模式类。如00000000(0次跳变),00000111(只含一次从0到1的跳变),10001111(先由1跳到0,再由0跳到1,共两次跳变)都是等价模式类。除等价模式类以外的模式都归为另一类,称为混合模式类,例如10010111(共四次跳变)。
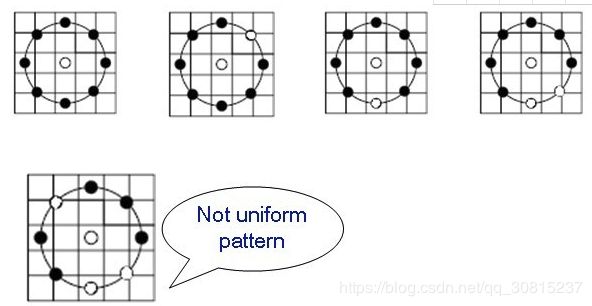
通过这样的改进,二进制模式的种类大大减少,而不会丢失任何信息。模式数量由原来的2^P种减少为 P ( P-1)+2种,其中P表示邻域集内的采样点数。对于3×3邻域内8个采样点来说,二进制模式由原始的256种减少为58种,即:它把值分为59类,58个uniform pattern为一类,其它的所有值为第59类。这样直方图从原来的256维变成59维。这使得特征向量的维数更少,并且可以减少高频噪声带来的影响。
具体实现:采样点数目为8个,即LBP特征值有2^8种,共256个值,正好对应灰度图像的0-255,因此原始的LBP特征图像是一幅正常的灰度图像,而等价模式LBP特征,根据0-1跳变次数,将这256个LBP特征值分为了59类,从跳变次数上划分:跳变0次—2个,跳变1次—0个,跳变2次—56个,跳变3次—0个,跳变4次—140个,跳变5次—0个,跳变6次—56个,跳变7次—0个,跳变8次—2个。共9种跳变情况,将这256个值进行分配,跳变小于2次的为等价模式类,共58个,他们对应的值按照从小到大分别编码为1—58,即它们在LBP特征图像中的灰度值为1—58,而除了等价模式类之外的混合模式类被编码为0,即它们在LBP特征中的灰度值为0,因此等价模式LBP特征图像整体偏暗。
//等价模式LBP特征计算
template
void getUniformPatternLBPFeature(InputArray _src,OutputArray _dst,int radius,int neighbors)
{
Mat src = _src.getMat();
//LBP特征图像的行数和列数的计算要准确
_dst.create(src.rows-2*radius,src.cols-2*radius,CV_8UC1);
Mat dst = _dst.getMat();
dst.setTo(0);
//LBP特征值对应图像灰度编码表,直接默认采样点为8位
uchar temp = 1;
uchar table[256] = {0};
for(int i=0;i<256;i++)
{
if(getHopTimes(i)<3)
{
table[i] = temp;
temp++;
}
}
//是否进行UniformPattern编码的标志
bool flag = false;
//计算LBP特征图
for(int k=0;k(radius * cos(2.0 * CV_PI * k / neighbors));
float ry = -static_cast(radius * sin(2.0 * CV_PI * k / neighbors));
//为双线性插值做准备
//对采样点偏移量分别进行上下取整
int x1 = static_cast(floor(rx));
int x2 = static_cast(ceil(rx));
int y1 = static_cast(floor(ry));
int y2 = static_cast(ceil(ry));
//将坐标偏移量映射到0-1之间
float tx = rx - x1;
float ty = ry - y1;
//根据0-1之间的x,y的权重计算公式计算权重,权重与坐标具体位置无关,与坐标间的差值有关
float w1 = (1-tx) * (1-ty);
float w2 = tx * (1-ty);
float w3 = (1-tx) * ty;
float w4 = tx * ty;
//循环处理每个像素
for(int i=radius;i(i,j);
//根据双线性插值公式计算第k个采样点的灰度值
float neighbor = src.at<_tp>(i+x1,j+y1) * w1 + src.at<_tp>(i+x1,j+y2) *w2 \
+ src.at<_tp>(i+x2,j+y1) * w3 +src.at<_tp>(i+x2,j+y2) *w4;
//LBP特征图像的每个邻居的LBP值累加,累加通过与操作完成,对应的LBP值通过移位取得
dst.at(i-radius,j-radius) |= (neighbor>center) <<(neighbors-k-1);
//进行LBP特征的UniformPattern编码
if(flag)
{
dst.at(i-radius,j-radius) = table[dst.at(i-radius,j-radius)];
}
}
}
}
}
//计算跳变次数
int getHopTimes(int n)
{
int count = 0;
bitset<8> binaryCode = n;
for(int i=0;i<8;i++)
{
if(binaryCode[i] != binaryCode[(i+1)%8])
{
count++;
}
}
return count;
}
4、LBP特征用于检测的原理
显而易见的是,上述提取的LBP算子在每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(每个像素点的LBP值)。
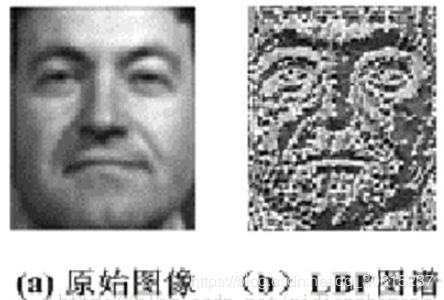
LBP的应用中,如纹理分类、人脸分析等,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
因为,从上面的分析我们可以看出,这个“特征”跟位置信息是紧密相关的。直接对两幅图片提取这种“特征”,并进行判别分析的话,会因为“位置没有对准”而产生很大的误差。后来,研究人员发现,可以将一幅图片划分为若干的子区域,对每个子区域内的每个像素点都提取LBP特征,然后,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述;整个图片就由若干个统计直方图组成;
例如:一幅100*100像素大小的图片,划分为10*10=100个子区域(可以通过多种方式来划分区域),每个子区域的大小为10*10像素;在每个子区域内的每个像素点,提取其LBP特征,然后,建立统计直方图;这样,这幅图片就有10*10个子区域,也就有了10*10个统计直方图,利用这10*10个统计直方图,就可以描述这幅图片了。之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了,LBP即可以用于人脸检测,也可用于人脸识别。
对LBP特征向量进行提取的步骤:
(1)首先将检测窗口划分为16×16的小区域(cell);
(2)对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值;
(3)然后计算每个cell的直方图,即每个数字(假定是十进制数LBP值)出现的频率;然后对该直方图进行归一化处理。
(4)最后将得到的每个cell的统计直方图进行连接成为一个特征向量,也就是整幅图的LBP纹理特征向量;
然后便可利用SVM或者其他机器学习算法进行分类了。
from:LBP原理加源码解析
from:Haar ,LBP 级联分类器
from:目标检测的图像特征提取之(二)LBP特征
from:人脸识别经典算法二:LBP方法
OpenCV实现了LBP+Adaboost+级联器检测方法
LBP+Adaboost方法用在目标检测中的效果比Haar特征、HOG特征都要好(HOG特征用的不多,主要是Haar和LBP),而且LBP特征的训练速度比Haar和HOG都要快很多。在LBP+Adaboost中,LBP特征主要是用作输入的训练数据(特征),使用的LBP特征应该是DLBP(维基百科上说的,没太看明白Cascade中LBP特征的计算方式),具体用法需要看源码。Opencv的TrainCascade中使用的LBP特征是MB-LBP。
OpenCV附带了一个名为traincascade的工具,用于训练LBP,Haar和HOG。特别是对于人脸检测,他们甚至以traincascade所需的格式处理了24x24像素大小的3000幅图像。
检测器以24x24的滑动窗口来寻找面部。从级联分类器的第1阶段到第20级步进,如果它可以显示当前24x24窗口可能不是面部,则它拒绝它并在窗口上移动一到两个像素到下一个位置;否则它将进入下一阶段。
在每个阶段,检查3-10个左右的LBP特征。每个LBP特征在窗口内都有一个偏移量和一个大小,它覆盖的区域完全包含在当前窗口中。计算每个给定位置LBP特征,可能导致通过或失败。根据LBP功能是成功还是失败,将特定于该功能的正或负权重添加到累加器。Evaluating an LBP feature at a given position can result in either a pass or fail.
Depending on whether an LBP feature succeeds or fails, a positive or negative weight particular to that feature is added to an accumulator.
将每个阶段的输出的值与每个阶段的阈值进行比较。如果输出低于阈值则该阶段失败,如果输出高于阈值则通过。同样如果一个阶段失败,则退出级联并且窗口移动到下一个位置。
与haar基本类似,不在赘述!
实例:
//cascades+LBP检测器的运用,用于人脸识别和人眼识别
#include
#include
using namespace std;
using namespace cv;
CascadeClassifier face_cascade;
CascadeClassifier eyes_cascade;
void detectAndDisplay(Mat frame);
int main(int argc, char** argv)
{
Mat srcImage;
srcImage = imread("1.jpg", 1);
imshow("原图", srcImage);
//============加载分类器=========
if (!face_cascade.load("D:\\Program Files\\OpenCV\\opencv\\sources\\data\\lbpcascades\\lbpcascade_frontalface.xml"))//也可用Haar分类器
{
printf("人脸检测器加载失败\n");
return -1;
}
if (!eyes_cascade.load("D:\\Program Files\\OpenCV\\opencv\\sources\\data\\haarcascades_cuda\\haarcascade_eye.xml"))
{
printf("人眼检测器加载失败\n");
return -1;
};
//============调用人脸检测函数 =========
detectAndDisplay(srcImage);
waitKey(0);
}
void detectAndDisplay(Mat dispFace)
{
//定义变量
std::vector faces;
std::vectoreyes;
Mat srcFace, grayFace, eqlHistFace;
int eye_number = 0;
cvtColor(dispFace, grayFace, CV_BGR2GRAY);
equalizeHist(grayFace, eqlHistFace); //直方图均衡化
//人脸检测******************
face_cascade.detectMultiScale(eqlHistFace, faces, 1.1, 3, 0 | CV_HAAR_SCALE_IMAGE, Size(10, 10));
//增大第四个参数可以提高检测精度,但也可能会造成遗漏
//人脸尺寸minSize和maxSize,关键参数,自行设定,随图片尺寸有很大关系,
for (unsigned int i = 0; i < faces.size(); i++)
{
//用蓝色椭圆标记检测到的人脸
Point center(faces[i].x + faces[i].width / 2, faces[i].y + faces[i].height / 2);
ellipse(dispFace, center, Size(faces[i].width / 2, faces[i].height * 65 / 100), 0, 0, 360, Scalar(255, 0, 0), 2, 8, 0);
//人眼检测*****************
Mat faceROI = eqlHistFace(faces[i]);
eyes_cascade.detectMultiScale(faceROI, eyes, 1.2, 3, 0 | CV_HAAR_SCALE_IMAGE, Size(15, 15), Size(80, 80));
eye_number += eyes.size();//人眼计数
//用绿色圆标记检测到的人眼*****************
for (unsigned int j = 0; j