智能信息检索——利用SIMNOMERGE余弦相似度计算文档得分的算法实现
智能信息检索——利用SIMNOMERGE余弦相似度计算文档得分的算法实现
- 1.实验目的
- 2.实验任务与要求
- 3.实验说明书
- ⑴功能描述
- ⑵概要设计
- ⑶详细设计
- ⑷代码实现
- 4.实验成果
《信息检索导论》部分实验python实现汇总请进入此博客查看。
1.实验目的
通过实验,使学生掌握利用 SIMNOMERGE余弦相似度计算文档得分的算法
2.实验任务与要求
XML由于文档包含非常复杂的树形结构,属性之间还存在嵌套关系,属性数目也高于参数化搜索和域搜索,因此检索更为复杂。基于向量空间模型的XML搜索中,为更好地提高检索正确率,需要利用SIMNOMERGE余弦相似度计算文档得分,本实验需要编程实现这个算法。
3.实验说明书
⑴功能描述
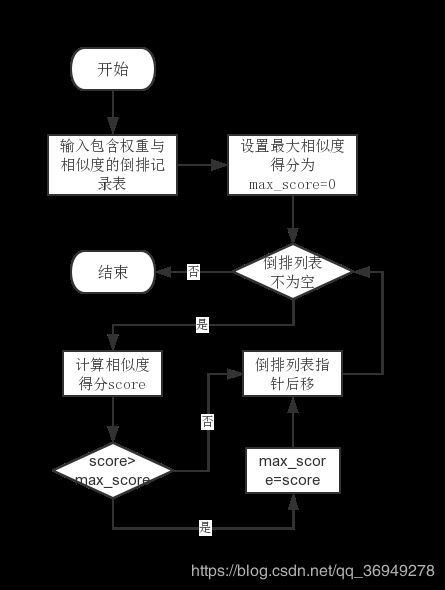
用户输入上下文c1,c2,c3与c1的匹配结果CR ,即CR(c1,c1),CR(c1,c2),CR(c1,c3)词项,以及词项t在各文档中的倒排记录表。系统计算词项与所有文档的相似度得分,并给出排名最高的文档。
⑵概要设计
通过相似度得分计算模块实现程序功能。
⑶详细设计
- 总体流程图
- 相似度得分计算模块
⑷代码实现
- 提示输入部分
num = 1
d, cts, df = [], [], []
while(1):
daopai = input('请输入词项t在文档c{}中的倒排记录表(用,分隔): '.format(num)).replace(' ', '').split(',')
weight = list(map(float, input('请依次输入倒排记录表的权重(用,分隔): ').replace(' ', '').split(',')))
d += daopai
ld, lw = len(daopai), len(weight)
if ld == lw:
locals()['c' + str(num) + 't'] = {}
for i, j in zip(daopai, weight):
locals()['c' + str(num) + 't'][i] = j
cts.append(locals()['c' + str(num) + 't'])
num += 1
else:
print('输入错误', end = ',')
flag = input('要继续输入吗[y|n]:')
if flag == 'n':
break
d = set(d)
lct = len(cts)
for i in range(lct):
CR = input('请输入文档c{}与查询的上下文相似度: '.format(i + 1))
locals()['CRc' + str(i + 1) + 't'] = {}
locals()['CRc' + str(i + 1) + 't'][float(CR)] = cts[i]
df.append(locals()['CRc' + str(i + 1) + 't'])
- 计算文档得分
max_score = 0
for i in d:
score = 0
for j in df:
CR = list(j.keys())[0]
if i in list(j[CR].keys()) and CR != 0:
score += CR*j[CR][i]
if max_score < score:
max_score = score
index = i
print("\n排名最高的是{}, 其相似度为{}".format(index, round(max_score, 3)))
程序中上部分内容均为获取用户输入及对其做出一定的处理过程,因为输入较为复杂,故在给出输入及输出范例如下。
请输入词项t在文档c1中的倒排记录表(用,分隔): d1,d4,d9
请依次输入倒排记录表的权重(用,分隔): 0.5,0.1,0.2
要继续输入吗[y|n]:y
请输入词项t在文档c2中的倒排记录表(用,分隔): d2,d3,d12
请依次输入倒排记录表的权重(用,分隔): 0.25,0.1,0.9
要继续输入吗[y|n]:y
请输入词项t在文档c3中的倒排记录表(用,分隔): d3,d6,d9
请依次输入倒排记录表的权重(用,分隔): 0.7,0.8,0.6
要继续输入吗[y|n]:n
请输入文档c1与查询的上下文相似度: 1
请输入文档c2与查询的上下文相似度: 0
请输入文档c3与查询的上下文相似度: 0.63
排名最高的是d9, 其相似度为0.578
4.实验成果
运行程序,根据提示进行输入,得到结果如下图。

观察结果可知排名最高的文档为d9,相似度为0.578。