随机森林(2)——代码简单实现
随机森林
Base Estimator,子模型是决策树集成起来,其实就是所谓的随机森林。
最开始想学的是这个,但是决策树看完,集成学习看完,好像这个就水到渠成了…找了视频发现讲的和之前看得差不多…所以个人这里直接看的代码,可看完代码,感觉也就这些东西啊…
代码
随机森林算法的主体,这个相对来说算是一个简单的随机森林算法实现,但其实逻辑就基本如下,如我开头所说,学会决策树和集成学习,随机森林真的没啥,难的应该是调参…而不是原理理解。
trees = list()
# n_trees 表示决策树的数量
for i in range(n_trees):
# 随机抽样的训练样本, 随机采样保证了每棵决策树训练集的差异性
sample = subsample(train, sample_size)
# 创建一个决策树
tree = build_tree(sample, max_depth, min_size, n_features)
trees.append(tree)
# 每一行的预测结果,bagging 预测最后的分类结果
predictions = [bagging_predict(trees, row) for row in test]
当然,比起单纯的构建决策树,这里显然增加了一些构建决策树的限制参数,但思想不变。
说几点关于本代码想说的:
- 详细代码解析直接看源码吧。(后面给出)
- 代码里的决策树是二分类树/ CART。
- 代码里没有减枝操作,而是以最大深度和叶子节点最少样本树来约束决策树的构建(防止过拟和)
- 随机森林代码中:每个子树输入的样本以及特征都为:有放回的随机抽取(bootstrap/bagging)
- 划分特征时,其代码只考虑了连续数值形式。
if row[index] < value:
left.append(row)
else:
right.append(row)
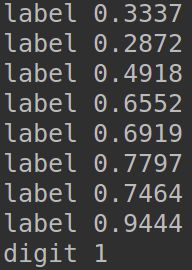
6.其原本代码运行报错,经过定位,是载入数据的语句出现了莫名奇妙的问题…恰好返过来了
if str_f.isdigit(): # 判断是否是数字
# 将数据集的第column列转换成float形式
print("digit",str_f)
lineArr.append(eval(str_f))
else:
# 添加分类标签
print("label", str_f)
lineArr.append(str_f)
7.自己进行了不正规的改写:
# 导入csv文件
def loadDataSet(filename):
dataset = []
with open(filename, 'r') as fr:
for line in fr.readlines():
if not line:
continue
lineArr = []
line_data = line.split(',')
featrue = [float(i) for i in line_data[:-1]]
lineArr.extend(featrue)
lineArr.append(line_data[-1])
dataset.append(lineArr)
return dataset
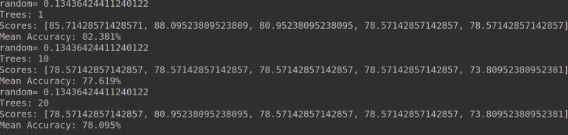
8.最后交叉验证,分别构建1/10/20颗树的运行结果:
9.这当然只是理论看完了,关于调参部分的经验学习,以及如何调参肯定也要学的。
代码内比较奇妙的用法
参数太多,直接用 *args接受后面的
evaluate_algorithm(dataset, algorithm, n_folds, *args)
合并list的用法,人生第一次见。
# 将多个 fold 列表组合成一个 train_set 列表, 类似 union all
"""
In [20]: l1=[[1, 2, 'a'], [11, 22, 'b']]
In [21]: l2=[[3, 4, 'c'], [33, 44, 'd']]
In [22]: l=[]
In [23]: l.append(l1)
In [24]: l.append(l2)
In [25]: l
Out[25]: [[[1, 2, 'a'], [11, 22, 'b']], [[3, 4, 'c'], [33, 44, 'd']]]
In [26]: sum(l, [])
Out[26]: [[1, 2, 'a'], [11, 22, 'b'], [3, 4, 'c'], [33, 44, 'd']]
"""
train_set = sum(train_set, [])
代码连接
https://github.com/MaybeWeCan/Random_Forest