数据分析练习
在日常生活及工作中,类别型数据大量存在,对他们采用恰当的分析方法,是数据分析工作中重要的关键点之一。
在类别型数据中,有时候,不同类别之间没有好坏之分,比如性别中的男和女。但在实际生活中,还存在另一种有序类别,他们有好坏顺序之分,比如成绩分级中的优良中差。
针对这样的类别型数据,不管是无序的或是有序的,我们都一起来探讨适合他们各自的处理方法。
知识结构
数据离散化及分箱操作
在实际的数据处理过程中,有时需要我们将连续的数据值进行划分,放到不同的区间中,减少过多的数据值给分析工作带来的麻烦。
将连续型数据打散放入到不同的区间,就类似将货物进行分箱存放,在数据分析过程中,常被称为“分箱操作”。比如我们常做的将不同年龄的人归为婴幼儿、儿童、少年、青年、中年、老年。
在pandas中,使用cut()方法进行分箱操作,比如以下代码样例,数据中记录了几个学生的姓名和他们各自的成绩,我们对成绩进行分箱:
import pandas as pd
#创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
df
| Name | Score | |
|---|---|---|
| 0 | George | 63 |
| 1 | Andrea | 48 |
| 2 | micheal | 56 |
| 3 | maggie | 75 |
| 4 | Ravi | 32 |
| 5 | Xien | 77 |
| 6 | Jalpa | 85 |
| 7 | Tyieren | 22 |
#对得分进行分箱操作,bins为整数,定义分为几个类别
pd.cut(df['Score'],bins=3)
0 (43.0, 64.0]
1 (43.0, 64.0]
2 (43.0, 64.0]
3 (64.0, 85.0]
4 (21.937, 43.0]
5 (64.0, 85.0]
6 (64.0, 85.0]
7 (21.937, 43.0]
Name: Score, dtype: category
Categories (3, interval[float64]): [(21.937, 43.0] < (43.0, 64.0] < (64.0, 85.0]]
向cut()中传入了两个参数,第一个是需要进行分箱操作的数据列,第二个参数bins表示我们希望将数据分配到几个区间之中。
cut()的操作将这列数据一共划分成了三个区间:(21.937, 43]、(43, 64]和(64, 85]。这个区间是系统根据提供的参数bins将数据区间进行平均划分得到的。请留意所有区间都是半开半闭形态,不包含区间开始的数字而包含区间的结束数字。
从cut()计算的结果列表中可以看到,第0、1、2个元素的结果是(43, 64],它表示原来的数据中,前三个数字(63、48、56)属于这个区间。接下来的数字75属于区间(64, 85],等等。你可以实际的观察一下结果的计算是否正确。
根据实际的应用场景,对于分箱边界的平均划分常常不能满足我们的需求。因此,cut()方法中,pandas让bins参数值可以用另一种方式定义——使用列表形式列出划分边界,如以下的代码:
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
#对得分进行分箱操作,bins为边界列表
pd.cut(df['Score'],bins=[0,60,80,90,100])
0 (60, 80]
1 (0, 60]
2 (0, 60]
3 (60, 80]
4 (0, 60]
5 (60, 80]
6 (80, 90]
7 (0, 60]
Name: Score, dtype: category
Categories (4, interval[int64]): [(0, 60] < (60, 80] < (80, 90] < (90, 100]]
这段代码中,传入cut()方法的bins参数被定义成了[0, 60, 80, 90, 100],于是分箱的区间就会被定义为(0, 60]、(60, 80]、(80, 90]和(90, 100]。从结果输出的最后一列也能很明确的看到这点。
分箱操作的结果中,会把每个数据所归属的结果区间直接显示出来。但我们可能希望用更直观的文本来表示分箱的结果。
比如成绩案例中,我们希望将前面划分的这几个区间从高分到低分分别叫做优、良、中、差。可以使用cut()方法的labels参数达到这一目的:
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
#对得分进行分箱操作,bins为边界列表,并且使用label定义区间的名字
df['Level'] = pd.cut(df['Score'],bins=[0,60,80,90,100],labels=['差','中','良','优'])
df
| Name | Score | Level | |
|---|---|---|---|
| 0 | George | 63 | 中 |
| 1 | Andrea | 48 | 差 |
| 2 | micheal | 56 | 差 |
| 3 | maggie | 75 | 中 |
| 4 | Ravi | 32 | 差 |
| 5 | Xien | 77 | 中 |
| 6 | Jalpa | 85 | 良 |
| 7 | Tyieren | 22 | 差 |
代码中,在进行了cut()操作之后,将分箱的结果与原有的df数据进行了拼接,成为了df中新的Level列。从结果中能更直观的看出不同学员成绩的好坏。
请注意在指定cut()方法的labels参数值时,labels定义的列表中的类别名顺序,是与bins定义的划分区间按顺序一一对应的。
分箱操作,其实就相当于将连续的数字类型数据(比如分数)映射成了类别型数据(比如这里的成绩等级)。分箱操作之后的结果,时常会再进行groupby操作。比如我们对分好等级之后的成绩再进行分组并计算每组中的平均值:
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
# 对得分进行分箱操作,bins为边界列表,并且使用labels定义区间的名字
df['Level'] = pd.cut(df['Score'], bins=[0, 60, 80, 90, 100], labels=['差', '中', '良', '优'])
#获取每个等级的平均成绩
df.groupby('Level').mean()
| Score | |
|---|---|
| Level | |
| 差 | 39.500000 |
| 中 | 71.666667 |
| 良 | 85.000000 |
| 优 | NaN |
这就能得到不同等级的平均成绩分别是多少。
在这个计算每个等级平均分的案例中,由于没有成绩落入优级别,在进行分组以及求均值计算之后,对应结果单元中得到的是NaN。
类别型数据类型
在前面的小节中,我们使用一个学生成绩的案例直接体验了pandas处理类别型数据的方法。现在我们来仔细了解pandas中的类别型数据类型。
跟整型(int)、字符串(str)等类型类似,类别型数据类型在pandas中也是一种数据类型。它使用category表示。
就像整型可以进行加减乘除操作一样,category也包含自己特殊的操作方式。
在之前我们通过pandas的cut()方法操作数据之后,会在结果输出中看到dtype: category这样的字样,这就表示结果数组中的元素,是类别数据类型的。
主动构造类别数据类型的变量,有以下几种主要的方法:
dtype
在创建一个Series变量的时候,使用dtype=‘category’,可以指定元素为类别类型。
import pandas as pd
s=pd.Series(['a','b','c','a'],dtype='category')
s
0 a
1 b
2 c
3 a
dtype: category
Categories (3, object): [a, b, c]
从代码输出中可以看出,这个Series的元素类型已经是类别型了。
astype()
另一种方式,调用Series的astype(),也可以将其中的元素转换为类别型。
import pandas as pd
s=pd.Series(['a','b','c','a'])
s2=s.astype('category')
print('s的值:')
print(s)
print('\ns2的值:')
print(s2)
s的值:
0 a
1 b
2 c
3 a
dtype: object
s2的值:
0 a
1 b
2 c
3 a
dtype: category
Categories (3, object): [a, b, c]
astype()方法其实就是pandas中的类型转换方法,参数中传入类型的名字,就可以将数组中的元素类型转换成这个参数指定的类型。
我们在代码中打印了Series变量s和s2的值。从输出内容上看,他们好像是一样的,不同只在于结果中的dtype。
只是内容上看起来一样,并不能说明s与s2是一样的。看以下代码展示类别型元素与字符串类型元素的差别:
import pandas as pd
s=pd.Series(['a','b','c','a'])
s2=s.astype('category')
s.max()
'c'
s2.max()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
----> 1 s2.max()
c:\users\administrator\appdata\local\programs\python\python37\lib\site-packages\pandas\core\generic.py in stat_func(self, axis, skipna, level, numeric_only, **kwargs)
11616 return self._agg_by_level(name, axis=axis, level=level, skipna=skipna)
11617 return self._reduce(
> 11618 f, name, axis=axis, skipna=skipna, numeric_only=numeric_only
11619 )
11620
c:\users\administrator\appdata\local\programs\python\python37\lib\site-packages\pandas\core\series.py in _reduce(self, op, name, axis, skipna, numeric_only, filter_type, **kwds)
4069 # TODO deprecate numeric_only argument for Categorical and use
4070 # skipna as well, see GH25303
-> 4071 return delegate._reduce(name, numeric_only=numeric_only, **kwds)
4072 elif isinstance(delegate, ExtensionArray):
4073 # dispatch to ExtensionArray interface
c:\users\administrator\appdata\local\programs\python\python37\lib\site-packages\pandas\core\arrays\categorical.py in _reduce(self, name, axis, **kwargs)
2259 msg = "Categorical cannot perform the operation {op}"
2260 raise TypeError(msg.format(op=name))
-> 2261 return func(**kwargs)
2262
2263 def min(self, numeric_only=None, **kwargs):
c:\users\administrator\appdata\local\programs\python\python37\lib\site-packages\pandas\core\arrays\categorical.py in max(self, numeric_only, **kwargs)
2302 max : the maximum of this `Categorical`
2303 """
-> 2304 self.check_for_ordered("max")
2305 if numeric_only:
2306 good = self._codes != -1
c:\users\administrator\appdata\local\programs\python\python37\lib\site-packages\pandas\core\arrays\categorical.py in check_for_ordered(self, op)
1584 "Categorical is not ordered for operation {op}\n"
1585 "you can use .as_ordered() to change the "
-> 1586 "Categorical to an ordered one\n".format(op=op)
1587 )
1588
TypeError: Categorical is not ordered for operation max
you can use .as_ordered() to change the Categorical to an ordered one
我们在代码中分别调用了元素是字符串类型的Series变量s以及元素是类别型的Series变量s2的max()方法。
从结果中你会发现,s.max()会输出结果’c’,因为字符串是可以比较大小的,在所有的元素中,'c’的值最大。
而s2.max()执行之后会发生错误。这就是我们之前提到的,类别型数据中,各类别在默认情况下没有大小之分,不能比较,因此就没有最大值。
对于有序型类别,pandas则提供了以下直接创建对象的方式,满足要求:
pandas.Categorical()
通过pandas.Categorical()构建一个对象,并在构建这个对象时,传入参数ordered=True,然后以这个Categorical作为数据模板创建Series,即可得到有序型的类别数据。看以下代码示例:
import pandas as pd
#pd.Categorical(),指定类别以及有序
s = pd.Series(pd.Categorical(['差','中','良','优'],ordered=True))
s
0 差
1 中
2 良
3 优
dtype: category
Categories (4, object): [中 < 优 < 差 < 良]
s.max()
'良'
在代码中,将有序型类别数据s进行输出,可以看到其中对优、良、中、差给出了明确的大小关系描述:[中 < 优 < 差 < 良]。
我们在第二段代码中打印了s.max(),可以从输出结果中看到最大值’良’。
但这里还有个问题,对于优、良、中、差的排序,并不是按照中文意思上的优最大、差最小进行的。
你可以尝试执行print(‘中’<‘优’<‘差’<‘良’),会得到结果True。这说明这里的类别顺序用的就是字符串的排序结果。
如果希望按照自己定义的顺序来定义类别,在构造Categorical对象的时候,还需要提供一个参数:categories。
老师使用以下代码再次构建有序的类别型变量s,这次我们希望在类别中,让[差 < 中 < 良 < 优]。
import pandas as pd
#pd.Categorical(),指定类别,指定顺序
s=pd.Series(
pd.Categorical(['差','中','良','优'],categories=['差','中','良','优'],ordered=True)
)
s
0 差
1 中
2 良
3 优
dtype: category
Categories (4, object): [差 < 中 < 良 < 优]
s.min()
'差'
s.max()
'优'
可以获取到我们想要结果的原因是,categories参数定义的列表中,从左到右的类别名字,会被pandas识别为从小到大。
类别型数据的基本操作
对于类别型数据的操作,跟其它类型相比,pandas多了操作类型本身的功能支持。
pandas基于自己向量化操作的设计宗旨,与之前我们介绍过的.str属性类似,让我们可以使用.cat属性对类别类型进行操作。
对数据类别的操作,主要包括获取类别相关信息、类别名字修改、类别添加和类别的删除。
类别信息查看
通过cat.categories,可以获取一个类别型数据中的类别名称列表:
import pandas as pd
s=pd.Series(['a','b','c','a'],dtype='category')
s.cat.categories
Index(['a', 'b', 'c'], dtype='object')
通过cat.ordered,可以判断出一个类别型数据中的类别是否是有序的:
import pandas as pd
s=pd.Series(['a','b','c','a'],dtype='category')
s.cat.ordered
False
类别修改
cat.categories属性是可读也可以修改的,修改它的值,可以将数据中的类别名字进行修改:
import pandas as pd
s=pd.Series(['a','b','c','a'],dtype='category')
s.cat.categories
Index(['a', 'b', 'c'], dtype='object')
s.cat.categories=['类别a','类别b','c']
s
0 类别a
1 类别b
2 c
3 类别a
dtype: category
Categories (3, object): [类别a, 类别b, c]
通过操作为cat.categories赋值,除了类别名字被修改之外,数据中的具体值也会被相应的改动。
除了修改cat.categories,调用cat.rename_categories()也可以达到修改类别名的目的。所不同的是,cat.rename_categories()不会作用在调用它的变量上,我们需要将方法调用的返回值赋值给一个新的变量,才能让类型修改的操作被记录下来。
import pandas as pd
s=pd.Series(['a','b','c','a'],dtype='category')
s2=s.cat.rename_categories(['cat1','cat2','cat3'])
print(s)
print('###########')
print(s2)
0 a
1 b
2 c
3 a
dtype: category
Categories (3, object): [a, b, c]
###########
0 cat1
1 cat2
2 cat3
3 cat1
dtype: category
Categories (3, object): [cat1, cat2, cat3]
添加新类别
可能你已经差不多猜到了,类别的添加使用方法cat.add_categories()实现:
import pandas as pd
pd.Series(['a','b','c','a'],dtype='category')
print('============添加类别之前============')
print(s)
s2=s.cat.add_categories(['类别4'])
print('\n=========添加类别之后==============')
s2[1]='类别4'
s2
============添加类别之前============
0 a
1 b
2 c
3 a
dtype: category
Categories (3, object): [a, b, c]
=========添加类别之后==============
0 a
1 类别4
2 c
3 a
dtype: category
Categories (4, object): [a, b, c, 类别4]
cat.add_categories()可以一次添加多个类别,只要将多个类别的名字都放到传入它的列表参数中就可以。
请注意,例子中,在进行了类别添加之后,原来数据的值并没有改变,只是多了一个类别类别4,可以让它成为指定类别值的一个新选项。
比如,你可以在指定某个数组元素的值时,给它赋上这个新的类别,类似:
s2[1]='类别4'
cat.add_categories()与cat.rename_categories()类似,它不会修改调用方法的变量本身,需要将操作的结果赋值给新的变量,才能把操作结果保留下来。
删除类别
cat.remove_categories()是删除类别的方法,与cat.add_categories()相对应。也同样是通过传入的列表型变量,列出需要删除的类别。方法不作用于调用它的变量,而是通过函数执行的返回值返回删除类别之后的数据。
import pandas as pd
s=pd.Series(['a','b','c','a'],dtype='category')
print('=====删除类别之前======')
print(s)
s2=s.cat.remove_categories(['a'])
print('\n===删除类别之后的s2变量值===')
print(s2)
print('\n===删除类别之后的s变量值===')
print(s)
=====删除类别之前======
0 a
1 b
2 c
3 a
dtype: category
Categories (3, object): [a, b, c]
===删除类别之后的s2变量值===
0 NaN
1 b
2 c
3 NaN
dtype: category
Categories (2, object): [b, c]
===删除类别之后的s变量值===
0 a
1 b
2 c
3 a
dtype: category
Categories (3, object): [a, b, c]
上面代码中,使用s.cat.remove_categories([‘a’])对类型’a’进行删除之后,所得结果中,原来值为’a’的元素值会变成NaN。
有了对类别型数据操作的进一步理解,我们将本关开始时的,对成绩进行分箱操作的例子再做一下改进。
使用cut()方法进行分箱之后,将结果的Level列指定为有序的类别列,类别的顺序是:[差 < 中 < 良 < 优]。并分别计算每个类别的平均成绩。
请在下面代码的TODO部分补全逻辑,完成以上要求:
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
df['Level'] = pd.cut(df['Score'], bins=[0, 60, 80, 90, 100], labels=['差', '中', '良', '优'])
# TODO,将df['Level']指定为有序型类别,类别顺序是[差 < 中 < 良 < 优]。
df['Level'] = pd.Series(pd.Categorical(df['Level'],categories=['差', '中', '良', '优'],ordered=True))
df
| Name | Score | Level | |
|---|---|---|---|
| 0 | George | 63 | 中 |
| 1 | Andrea | 48 | 差 |
| 2 | micheal | 56 | 差 |
| 3 | maggie | 75 | 中 |
| 4 | Ravi | 32 | 差 |
| 5 | Xien | 77 | 中 |
| 6 | Jalpa | 85 | 良 |
| 7 | Tyieren | 22 | 差 |
df.groupby('Level').mean()
| Score | |
|---|---|
| Level | |
| 差 | 39.500000 |
| 中 | 71.666667 |
| 良 | 85.000000 |
| 优 | NaN |
在上面代码的结果中,对应于优类别的均值是NaN,是由于数据中其实并不存在值是这个类别的数据。这个类别可以认为是多余的。
cat.remove_unused_categories()方法可以用于删除这样的多余分类,如下操作:
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
df['Level'] = pd.cut(df['Score'], bins=[0, 60, 80, 90, 100], labels=['差', '中', '良', '优'])
# 将df['Level']指定为有序型类别,类别顺序是[差 < 中 < 良 < 优]。
df['Level'] = pd.Series(
pd.Categorical(df['Level'], categories=['差', '中', '良', '优'], ordered=True)
)
df['Level']=df['Level'].cat.remove_unused_categories()
#计算每种类别的平均成绩
df.groupby('Level').mean()
| Score | |
|---|---|
| Level | |
| 差 | 39.500000 |
| 中 | 71.666667 |
| 良 | 85.000000 |
我们通过df[‘Level’] = df[‘Level’].cat.remove_unused_categories()这样一句代码,将Level列中的无用类别去除,并将结果重新赋值给df[‘Level’]。
在最后的输出中,可以看到Level优以及它对应的NaN都没有了。
排序及比较
有序型类别因为其有序性,数据之间可以进行排序和大小比较。
排序
我们都知道Series可以通过sort_values()方法对值进行排序,如:
import pandas as pd
data = ['c','a','b','b']
s=pd.Series(data)
s.sort_values()
1 a
2 b
3 b
0 c
dtype: object
数据以字符串的顺序为标准进行排序。当将这个代码中的数组指定为类别型数据,并自己定义类别顺序时,排序将会按照我们自己定义的类别顺序进行:
import pandas as pd
data=['c','a','b','b']
s=pd.Series(pd.Categorical(data,categories=['c','b','a'],ordered=True))
s.sort_values()
0 c
2 b
3 b
1 a
dtype: category
Categories (3, object): [c < b < a]
类似的,应用到成绩案例里,我们将学生成绩按照等级做简单的从差到优排序,就可以如下这样:
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
df['Level'] = pd.cut(df['Score'], bins=[0, 60, 80, 90, 100], labels=['差', '中', '良', '优'])
# TODO,将df['Level']指定为有序型类别,类别顺序是[差 < 中 < 良 < 优]。
df['Level'] = pd.Series(
pd.Categorical(df['Level'], categories=['差', '中', '良', '优'], ordered=True)
)
df.sort_values(by='Level')
| Name | Score | Level | |
|---|---|---|---|
| 1 | Andrea | 48 | 差 |
| 2 | micheal | 56 | 差 |
| 4 | Ravi | 32 | 差 |
| 7 | Tyieren | 22 | 差 |
| 0 | George | 63 | 中 |
| 3 | maggie | 75 | 中 |
| 5 | Xien | 77 | 中 |
| 6 | Jalpa | 85 | 良 |
DataFrame的sort_values()方法我们之前已经学习过,通过提供参数by='Level’指定按照Level进行排序,而这里排序的规则就会依照这个有序类别列中类别的顺序进行。
当我们希望对已经设置好顺序的类别型数组重新定义顺序的时候,可以使用cat.reorder_categories()方法。
比如,通过以下操作,将差 < 中 < 良 < 优的排序顺序改为优 < 良 < 中 < 差。
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
df['Level'] = pd.cut(df['Score'], bins=[0, 60, 80, 90, 100], labels=['差', '中', '良', '优'])
df['Level'] = pd.Series(
pd.Categorical(df['Level'], categories=['差', '中', '良', '优'], ordered=True)
)
df['Level'] = df['Level'].cat.reorder_categories(['优', '良', '中', '差'], ordered=True)
df.sort_values(by='Level')
| Name | Score | Level | |
|---|---|---|---|
| 6 | Jalpa | 85 | 良 |
| 0 | George | 63 | 中 |
| 3 | maggie | 75 | 中 |
| 5 | Xien | 77 | 中 |
| 1 | Andrea | 48 | 差 |
| 2 | micheal | 56 | 差 |
| 4 | Ravi | 32 | 差 |
| 7 | Tyieren | 22 | 差 |
DataFrame的sort_values()方法我们之前已经学习过,通过提供参数by='Level’指定按照Level进行排序,而这里排序的规则就会依照这个有序类别列中类别的顺序进行。
当我们希望对已经设置好顺序的类别型数组重新定义顺序的时候,可以使用cat.reorder_categories()方法。
比如,通过以下操作,将差 < 中 < 良 < 优的排序顺序改为优 < 良 < 中 < 差。
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
df['Level'] = pd.cut(df['Score'], bins=[0, 60, 80, 90, 100], labels=['差', '中', '良', '优'])
df['Level'] = pd.Series(
pd.Categorical(df['Level'], categories=['差', '中', '良', '优'], ordered=True)
)
df['Level']=df['Level'].cat.reorder_categories(['优','良','中','差'],ordered=True)
df.sort_values(by='Level')
| Name | Score | Level | |
|---|---|---|---|
| 6 | Jalpa | 85 | 良 |
| 0 | George | 63 | 中 |
| 3 | maggie | 75 | 中 |
| 5 | Xien | 77 | 中 |
| 1 | Andrea | 48 | 差 |
| 2 | micheal | 56 | 差 |
| 4 | Ravi | 32 | 差 |
| 7 | Tyieren | 22 | 差 |
cat.reorder_categories()的操作结果同样不会作用在调用它的对象上,需要通过一个赋值操作将结果保存下来。
比较
针对类别类型列的比较,跟普通向量的比较运算是类似的。支持>、<、>=、<=、==等操作,可以是向量与向量之间的比较,也可以是向量与标量之间的比较.
比较计算的结果是由布尔数(True、False)组成的数组,表示源数组中对应位置的元素进行比较操作之后所得到的结果。
比如,在成绩数据中,将Level列数据与’中’进行比较操作:
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
df['Level'] = pd.cut(df['Score'], bins=[0, 60, 80, 90, 100], labels=['差', '中', '良', '优'])
#将df['level']指定为有序型类别,类别顺序是【差<中<良<优】
df['Level']= pd.Series(
pd.Categorical(df['Level'],categories=['差', '中', '良', '优'],ordered=True)
)
df['Level']>='中'
0 True
1 False
2 False
3 True
4 False
5 True
6 True
7 False
Name: Level, dtype: bool
df[‘Level’] >= '中’计算的结果就是一个由True和False组成的Series,其中为True的元素,就表示该行在原来的df中,Level列的值是大于或等于’中’的。
这个结果数组的形态就是我们之前学习过的过滤数组,可以通过它过滤出成绩较好(中、良、优)的所有记录:
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
df['Level'] = pd.cut(df['Score'], bins=[0, 60, 80, 90, 100], labels=['差', '中', '良', '优'])
# 将df['Level']指定为有序型类别,类别顺序是[差 < 中 < 良 < 优]。
df['Level'] = pd.Series(
pd.Categorical(df['Level'], categories=['差', '中', '良', '优'], ordered=True)
)
df2 = df[df['Level'] >= '中']
df2
| Name | Score | Level | |
|---|---|---|---|
| 0 | George | 63 | 中 |
| 3 | maggie | 75 | 中 |
| 5 | Xien | 77 | 中 |
| 6 | Jalpa | 85 | 良 |
在两个类别型数据的向量(Series)之间进行比较的时候,向量之间对应的元素会进行对比操作,得到True和False组成的结果数组。
以下是个简单例子,声明了s1跟s2两个类别型变量,它们有同样的类别和排序规则,进行s1 这里需要提醒你的是,参与对比的向量,它们的类别以及排序规则必须是相同的,不然对比操作会出现错误。以下是一个会发生错误的代码,你可以在代码编辑器里尝试一下: 在类型数据中,一般都会使用人类语言的方式表示不同的类别,比如前面提及的优良中差,以及男女等。 而当基于类别型数据进行数据挖掘或者机器学习等工作时,由于很多算法只能识别数字类型的输入,因此,在数据处理阶段,需要将类别型数据进行数值化处理,转换成数字类型,才能给后续的处理流程使用。 对于有序型类别数据,类别之间有大小关系,一个比较直接的做法是,将顺序小的类别映射成小数字,顺序大的类别映射成大的数字。 比如我们本关一直提到的成绩等级,可以有这样的映射:差->0,中->1,良->2,优->3。 可以使用map()方法实现这样的映射操作: 以上代码通过map()方法根据Level列映射出了Level_code列。向map()参数中传入一个字典,将原本的类别值作为字典的key,希望映射到的目标数字作为value,就可以完成数值化操作了。 这个结果列Level_code是可以直接使用到机器学习或数据挖掘的算法之中的。 对于像性别这样的类别,我们再使用比如男->0、女->1这样的方式进行映射,就不太合适了。因为从数值上看,1大于0,这让无序型类别变得有顺序了。 在数据分析中,一般将无序型类别通过虚拟变量,也叫哑变量(dummy variable)的方式进行编码。 调用pandas.get_dummies()方法,将要转成哑变量的数据列放入作为参数,函数的返回值就是编码结果。 上面代码中,我们为成绩数据添加了性别列(Gender),通过pd.get_dummies(df[‘Gender’]),就可以将这列内容转成哑变量编码方式。 在哑变量编码方式中,我们可以看到,原来的一列属性,变成了两列表示,每列的取值只有0、1两种。当某行原来的值是男的时候,在新的哑变量方式时,就在名为男的这列中取值为1,女的这列对应取值为0。 这样的编码转换对于机器学习、数据挖掘处理的算法非常适用。我们现在还没法更直观的体会到这样处理的好处,只需要知晓,它是对于无序型类别数据常用的处理方法就可以。 get_dummies()方法也可以接受一个DataFrame的变量作为参数,比如我们将例子中的df整个传给get_dummies(): 你会发现所有非数值类型的列(Name和Gender)都被做了哑变量转换。 在结果中,使用原列名_原取值的形式定义每个哑变量转换结果的列名。 原来只有两列的属性,经过转换之后变成了10列。这就是所谓的属性爆炸。 属性列数量的增加会让计算复杂度增加,并可能严重影响计算性能,因此在进行哑变量转换的时候,需要根据实际的业务需求,挑选必须要进行处理的属性进行转换。 有时候,当需要做转换的属性确实比较多时,可以将操作分成两步,第一步先进行属性精简(比如将意义相类似的多个属性合并为一个),第二步再进行哑变量转换。 之前总有这样的说法:美国大使馆测量出的污染总是比中国官方的测量要严重,确实是如此的么?基于这份数据,我们尝试做个分析对比。 数据中与我们的分析有关联的几个属性是: 这个分析需求中,我们只需要上面列出的7列数据,根据之前所学知识,你一定想到,我们可以通过df[列名列表]的方式将需要的列筛选出来。 但在真实的项目中,如果在一开始就能确定我们所需要处理的数据只是数据集中的部分列的话,在调用read_csv()方法的时候,可以指定usecols参数,只读取我们感兴趣的列到数据变量中,节省程序对于内存资源的使用。 由于中国本土的测绘点有两个,我们可以计算PM_Jingan和PM_Xuhui两列的均值,形成一个新列PM_China,用于表示中国的测量值。 从前几行的输出中,很容易发现PM_China列中有很多空值,我们接下来做两步操作: 25140 rows × 6 columns 从输出结果中,可以看到,处理掉空值之后,剩下两万多行有效数据。 数据中的日期信息由4列组成,包括了年月日以及具体的时间。 为了方便之后的可视化展示,将year、month、day、hour这些列信息合并到date列中。新列的由原来的年月日三列组成(忽略掉hour),内容为year-month-day。 25140 rows × 3 columns 在这段数据处理中,我们首先使用astype(str)方法将year、month、day这三列的数据的元素类型转换成了字符串。 然后使用str.cat将这三列拼接成year-month-day的结果形式,并赋值到一个新的列date中。这步操作我们使用了字符串数据的向量化操作。 最后将无用的year、month、day、hour这几列数据删除掉。 在处理好日期之后,date列中一个日期会对应多行数据,我们将数据按date列进行分组,并在组内求均值,得到新的数据。 1090 rows × 2 columns 调用DataFrame的groupby()方法,得到的结果中取出PM_China、PM_US Post两列。通过mean()方法对分组后的两列分别进行组内求均值,便得到了上面得结果。 看起来好像已经有了个还算可以的结果,我们直接针对day_stats的数据绘制一下柱形图: 由于数据项繁多,除了坐标轴不清晰之外,图形输出也没法让人得到太直观的结论。 数据分析的工作还需要继续。 回顾我们此次数据分析工作的目标:希望对比中美机构PM2.5统计结果的差异性。 但数据的跨度大,用时间做横坐标做出的柱形图让结果不具备可阅读性。 我们可以转换成另一种展现方式,让结果更可读一些:将PM2.5空气污染分成优、轻度、中度、重度几个等级,以等级作为结果图的横坐标,分别绘制中美机构统计结果中,落在不同天气等级上的次数是多少。 空气等级的定义为: 我们尝试使用pandas的cut()方法,按照上面的要求定义cut()中的bins参数,对PM_China和PM_US Post两列数据进行分箱操作。两列数据分箱之后的结果分别存到新的Polluted State CH和Polluted State US列。 在做分箱操作时,也将每个分级的名字优、轻度、中度、重度做正确的指定。请按这个要求完成以下代码的TODO部分。 1090 rows × 2 columns 1090 rows × 4 columns 你可以多留意一下,老师在定义分箱边界bins的时候,下界使用了-np.inf,上界使用np.inf,它们分别表示负无穷和正无穷。 使用DataFrame的value_counts()方法,对Polluted State CH和Polluted State US两列分别做统计,计算出数据中每种类型的天气分别有多少次。 我们将中国和美国的统计结果分别生成到了变量ch_stats以及us_stats中,接下来,将这两列数据拼接成一个DataFrame,即可绘制对比图形了: 针对上海这个城市的统计结果,可以看出对于重度和中度两种空气质量的结论,中国的统计天数比美国统计的还要多一些,并不像传说那样的“中国的空气质量统计结果总是好于美国的统计”。 好了,本关的主要内容就是这么多。在课后练习中,我们使用类似的方法,再一起统计除了上海之外,北京、广州、成都、沈阳这几个城市的空气质量数据,以期得到更完整的结论。 知识总结 本关我们讲述了pandas在进行类别型数据处理时主要使用的方法。并通过分析上海PM2.5数据指标来评判中美不同机构统计天气指数的差异性。 在pandas中,使用cut()方法可以完成数据分箱操作,将连续型数值转换成类别型。 我们也可以通过dtype、astype()、pandas.Categorical()方法直接构建类别型数据。 pandas为我们提供了基本的类别型数据操作,包括类别信息查看、类别修改、添加新类别、删除类别。 类别型数据可以分为有序型和无序型,当为有序型时,可以对数据进行排序和比较。 在需要将类别型数据用于机器学习或者数据挖掘的算法时,可以使用map()或者哑变量转换的方式分别处理有序型和无序型类别数据。import pandas as pd
s1=pd.Series(pd.Categorical(['a','b','c','a'],categories=['c','b','a'],ordered=True))
print(s1)
s2=pd.Series(pd.Categorical(['a','c','b','a'],categories=['c','b','a'],ordered=True))
print(s2)
s10 a
1 b
2 c
3 a
dtype: category
Categories (3, object): [c < b < a]
0 a
1 c
2 b
3 a
dtype: category
Categories (3, object): [c < b < a]
0 False
1 False
2 True
3 False
dtype: bool
s1 = pd.Series(pd.Categorical(['a', 'b', 'c', 'a'], categories=['c', 'b', 'a'], ordered=True))
s2 = pd.Series(pd.Categorical(['a', 'c', 'b', 'a'], categories=['b', 'c', 'a'], ordered=True))
print(s1---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
类别型数据的数值化
有序型类别数据
import pandas as pd
# 创建数据
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22]})
df['Level'] = pd.cut(df['Score'], bins=[0, 60, 80, 90, 100], labels=['差', '中', '良', '优'])
# 将df['Level']指定为有序型类别,类别顺序是[差 < 中 < 良 < 优]。
df['Level'] = pd.Series(
pd.Categorical(df['Level'], categories=['差', '中', '良', '优'], ordered=True)
)
df['Level_code'] = df['Level'].map({'差': 0, '中': 1, '良': 2, '优':3})
df
Name
Score
Level
Level_code
0
George
63
中
1
1
Andrea
48
差
0
2
micheal
56
差
0
3
maggie
75
中
1
4
Ravi
32
差
0
5
Xien
77
中
1
6
Jalpa
85
良
2
7
Tyieren
22
差
0
无序型类别数据
import pandas as pd
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22],
'Gender':['男','男','男','女','男','女','男','女']})
df
Name
Score
Gender
0
George
63
男
1
Andrea
48
男
2
micheal
56
男
3
maggie
75
女
4
Ravi
32
男
5
Xien
77
女
6
Jalpa
85
男
7
Tyieren
22
女
# 将Gender列做哑变量转换
pd.get_dummies(df['Gender'])
女
男
0
0
1
1
0
1
2
0
1
3
1
0
4
0
1
5
1
0
6
0
1
7
1
0
import pandas as pd
df = pd.DataFrame({'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa','Tyieren'],
'Score':[63,48,56,75,32,77,85,22],
'Gender':['男','男','男','女','男','女','男','女']})
df
Name
Score
Gender
0
George
63
男
1
Andrea
48
男
2
micheal
56
男
3
maggie
75
女
4
Ravi
32
男
5
Xien
77
女
6
Jalpa
85
男
7
Tyieren
22
女
pd.get_dummies(df)
Score
Name_Andrea
Name_George
Name_Jalpa
Name_Ravi
Name_Tyieren
Name_Xien
Name_maggie
Name_micheal
Gender_女
Gender_男
0
63
0
1
0
0
0
0
0
0
0
1
1
48
1
0
0
0
0
0
0
0
0
1
2
56
0
0
0
0
0
0
0
1
0
1
3
75
0
0
0
0
0
0
1
0
1
0
4
32
0
0
0
1
0
0
0
0
0
1
5
77
0
0
0
0
0
1
0
0
1
0
6
85
0
0
1
0
0
0
0
0
0
1
7
22
0
0
0
0
1
0
0
0
1
0
上海PM2.5数据分析
import pandas as pd
df=pd.read_csv('PM_shanghai.csv')
df.head()
No
year
month
day
hour
season
PM_Jingan
PM_US Post
PM_Xuhui
DEWP
HUMI
PRES
TEMP
cbwd
Iws
precipitation
Iprec
0
1
2010
1
1
0
4
NaN
NaN
NaN
-6.0
59.48
1026.1
1.0
cv
1.0
0.0
0.0
1
2
2010
1
1
1
4
NaN
NaN
NaN
-6.0
59.48
1025.1
1.0
SE
2.0
0.0
0.0
2
3
2010
1
1
2
4
NaN
NaN
NaN
-7.0
59.21
1025.1
0.0
SE
4.0
0.0
0.0
3
4
2010
1
1
3
4
NaN
NaN
NaN
-6.0
63.94
1024.0
0.0
SE
5.0
0.0
0.0
4
5
2010
1
1
4
4
NaN
NaN
NaN
-6.0
63.94
1023.0
0.0
SE
8.0
0.0
0.0
提取需要的列数据
import pandas as pd
#定义要读取的列
usecols = ['year','month','day','hour','PM_Jingan','PM_Xuhui','PM_US Post']
#使用usecols指定读取的部分列数据
data_df = pd.read_csv('PM_shanghai.csv',usecols=usecols)
print("共有{}行数据".format(data_df.shape[0]))
print('前10行数据是:')
data_df.head(10)
共有52584行数据
前10行数据是:
year
month
day
hour
PM_Jingan
PM_US Post
PM_Xuhui
0
2010
1
1
0
NaN
NaN
NaN
1
2010
1
1
1
NaN
NaN
NaN
2
2010
1
1
2
NaN
NaN
NaN
3
2010
1
1
3
NaN
NaN
NaN
4
2010
1
1
4
NaN
NaN
NaN
5
2010
1
1
5
NaN
NaN
NaN
6
2010
1
1
6
NaN
NaN
NaN
7
2010
1
1
7
NaN
NaN
NaN
8
2010
1
1
8
NaN
NaN
NaN
9
2010
1
1
9
NaN
NaN
NaN
计算中国测量的PM数据
import pandas as pd
# 定义要读取的列
usecols = ['year', 'month', 'day', 'hour', 'PM_Jingan', 'PM_Xuhui', 'PM_US Post']
data_df = pd.read_csv('PM_shanghai.csv', usecols=usecols)
# TODO,计算新列PM_China,值为PM_Jingan和PM_Xuhui列的均值
data_df['PM_China'] =data_df[['PM_Jingan','PM_Xuhui']].mean(axis=1)
data_df.head()
year
month
day
hour
PM_Jingan
PM_US Post
PM_Xuhui
PM_China
0
2010
1
1
0
NaN
NaN
NaN
NaN
1
2010
1
1
1
NaN
NaN
NaN
NaN
2
2010
1
1
2
NaN
NaN
NaN
NaN
3
2010
1
1
3
NaN
NaN
NaN
NaN
4
2010
1
1
4
NaN
NaN
NaN
NaN
import pandas as pd
# 定义要读取的列
usecols = ['year', 'month', 'day', 'hour', 'PM_Jingan', 'PM_Xuhui', 'PM_US Post']
#读取数据并计算PM_China
data_df = pd.read_csv('PM_shanghai.csv', usecols=usecols)
data_df['PM_China'] = data_df[['PM_Jingan', 'PM_Xuhui']].mean(axis=1)
#去除空值
cln_data_df = data_df[['year','month','day','hour','PM_China','PM_US Post']]
cln_data_df=cln_data_df.dropna()
cln_data_df
year
month
day
hour
PM_China
PM_US Post
26304
2013
1
1
0
68.5
70.0
26305
2013
1
1
1
69.5
76.0
26307
2013
1
1
3
73.5
78.0
26308
2013
1
1
4
76.0
77.0
26309
2013
1
1
5
76.5
78.0
...
...
...
...
...
...
...
52578
2015
12
31
18
91.5
92.0
52579
2015
12
31
19
88.0
82.0
52580
2015
12
31
20
84.5
93.0
52581
2015
12
31
21
90.0
90.0
52582
2015
12
31
22
87.5
86.0
日期处理
import pandas as pd
# 定义要读取的列
usecols = ['year', 'month', 'day', 'hour', 'PM_Jingan', 'PM_Xuhui', 'PM_US Post']
#读取数据并计算PM_China
data_df = pd.read_csv('PM_shanghai.csv', usecols=usecols)
data_df['PM_China'] = data_df[['PM_Jingan', 'PM_Xuhui']].mean(axis=1)
#去除空值
cln_data_df = data_df[['year','month','day','hour','PM_China','PM_US Post']]
cln_data_df=cln_data_df.dropna()
#转换数据类型
cln_data_df[['year','month','day']]=cln_data_df[['year','month','day']].astype('str')
#合并列
cln_data_df['data']=cln_data_df['year'].str.cat([cln_data_df['month'],cln_data_df['day']],sep='-')
#去除无用列
cln_data_df = cln_data_df.drop(['year','month','day','hour'],axis=1)
cln_data_df
PM_China
PM_US Post
data
26304
68.5
70.0
2013-1-1
26305
69.5
76.0
2013-1-1
26307
73.5
78.0
2013-1-1
26308
76.0
77.0
2013-1-1
26309
76.5
78.0
2013-1-1
...
...
...
...
52578
91.5
92.0
2015-12-31
52579
88.0
82.0
2015-12-31
52580
84.5
93.0
2015-12-31
52581
90.0
90.0
2015-12-31
52582
87.5
86.0
2015-12-31
数据分组
#通过分组操作获取每天的PM均值
day_stats=cln_data_df.groupby(['data'])[['PM_China','PM_US Post']].mean()
day_stats
PM_China
PM_US Post
data
2013-1-1
77.772727
79.272727
2013-1-10
50.119048
58.380952
2013-1-11
46.812500
50.562500
2013-1-12
159.761905
163.380952
2013-1-13
50.476190
58.523810
...
...
...
2015-9-5
43.479167
36.500000
2015-9-6
38.208333
28.375000
2015-9-7
19.479167
14.625000
2015-9-8
14.791667
11.958333
2015-9-9
13.791667
10.333333
#通过分组操作获取每天的PM均值
import matplotlib.pyplot as plt
%matplotlib inline
day_stats.plot.bar()
plt.show()

分箱
import pandas as pd
import matplotlib.pyplot as plt
# 定义要读取的列
usecols = ['year', 'month', 'day', 'hour', 'PM_Jingan', 'PM_Xuhui', 'PM_US Post']
data_df = pd.read_csv('PM_shanghai.csv', usecols=usecols)
# 计算新列PM_China,值为PM_Jingan和PM_Xuhui列的均值
data_df['PM_China'] = data_df[['PM_Jingan', 'PM_Xuhui']].mean(axis=1)
cln_data_df = data_df[['year','month','day','hour','PM_China','PM_US Post']]
cln_data_df = cln_data_df.dropna()
# 转换数据类型
cln_data_df[['year', 'month', 'day']] = cln_data_df[['year', 'month', 'day']].astype('str')
# 合并列
cln_data_df['date'] = cln_data_df['year'].str.cat([cln_data_df['month'], cln_data_df['day']], sep='-')
# 去除无用列
cln_data_df = cln_data_df.drop(['year', 'month', 'day', 'hour'], axis=1)
# 通过分组操作获取每天的PM均值
day_stats = cln_data_df.groupby(['date'])[['PM_China', 'PM_US Post']].mean()
day_stats
PM_China
PM_US Post
date
2013-1-1
77.772727
79.272727
2013-1-10
50.119048
58.380952
2013-1-11
46.812500
50.562500
2013-1-12
159.761905
163.380952
2013-1-13
50.476190
58.523810
...
...
...
2015-9-5
43.479167
36.500000
2015-9-6
38.208333
28.375000
2015-9-7
19.479167
14.625000
2015-9-8
14.791667
11.958333
2015-9-9
13.791667
10.333333
import numpy as np
bins = [-np.inf,35,75,150,np.inf]
state_labels = ['优','轻度','中度','重度']
day_stats['Polluted State CH']=pd.cut(day_stats['PM_China'],bins=bins,labels=state_labels)
day_stats['Polluted State US']=pd.cut(day_stats['PM_US Post'],bins=bins,labels=state_labels)
day_stats
PM_China
PM_US Post
Polluted State CH
Polluted State US
date
2013-1-1
77.772727
79.272727
中度
中度
2013-1-10
50.119048
58.380952
轻度
轻度
2013-1-11
46.812500
50.562500
轻度
轻度
2013-1-12
159.761905
163.380952
重度
重度
2013-1-13
50.476190
58.523810
轻度
轻度
...
...
...
...
...
2015-9-5
43.479167
36.500000
轻度
轻度
2015-9-6
38.208333
28.375000
轻度
优
2015-9-7
19.479167
14.625000
优
优
2015-9-8
14.791667
11.958333
优
优
2015-9-9
13.791667
10.333333
优
优
类别统计
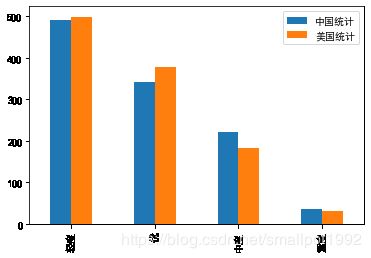
ch_stats=day_stats['Polluted State CH'].value_counts()
ch_stats
轻度 490
优 342
中度 222
重度 36
Name: Polluted State CH, dtype: int64
us_stats=day_stats['Polluted State US'].value_counts()
us_stats
轻度 499
优 379
中度 182
重度 30
Name: Polluted State US, dtype: int64
import matplotlib.pyplot as plt
%matplotlib inline
result_df= pd.DataFrame({'中国统计':ch_stats,
'美国统计':us_stats})
plt.rcParams['font.sans-serif']=['SimHei']
result_df.plot.bar()
plt.show()