fabric私密数据学习笔记
私密数据分为两部分
一个是真正的key,value,它被存在 peer的私密数据库(private state)中。
另一部分为公共数据,它是真实的私密数据key,value 哈希后的值 hash(key),hash(value),它被存在普通的peer数据库中(state),orderer端可以拿到该值。没有被分配私密数据权限的peer,也仅仅可以存储hash后的key和value。
何时使用channel进行数据隔离,何时使用私密数据进行隔离
- 需要组织间进 数据隔离时,使用channel进行数据隔离。
- 当需要组织内进 数据隔离时,使用私密数据进行数据隔离。
- 处于同一channel的多个组织之间进行数据隔离时,也要使用私密数据进行数据隔离。
私有数据在fabric中的交易流程
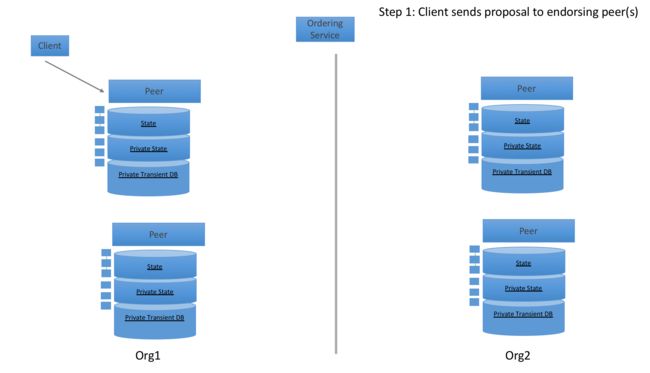
sdk将交易发送给背书节点,该背书节点需要通过policy(此
处的policy为instantiation设定的)验证。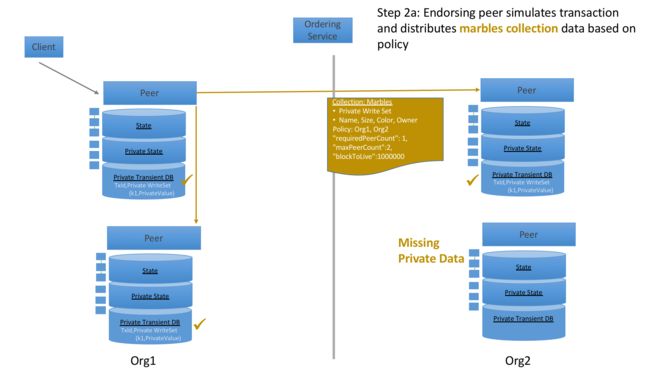
背书节点模拟执行交易 ,并将真实的私密数据 key和value存
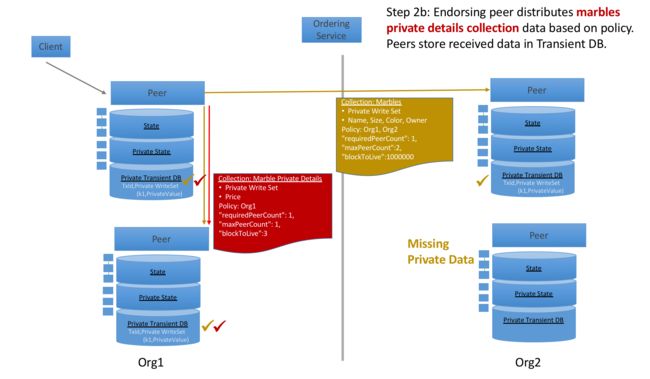
储于瞬时数据库(private transient DB)中。基于collection policy,验证通过的peer节点,通过gossip同步真实的私密数据,并将其存储于瞬时数据库中。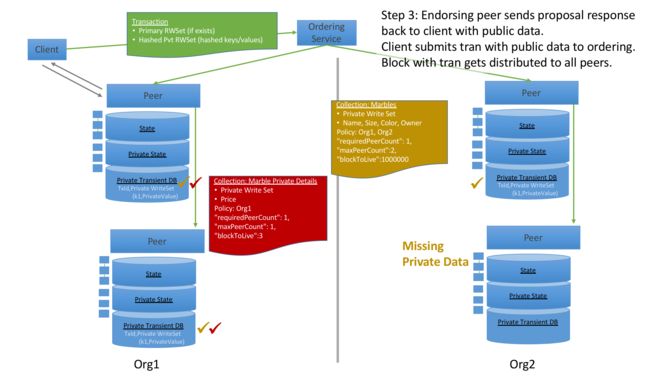
背书节点将模拟执行后的结果返回给SDK,返回的数据中仅有公共数据(hash过的私密数据)。SDK将peer返回的结果打包后发送给orderer,和普通的区块一样,orderer切块后,将其分发给peer,此时所有的peer都拿到了公共数据,所有的peer都可以去验证私有数据,没有通过collection policy的peer,也可以验证,而且还不拥有真实的私密数据,保证了数据的私密性。
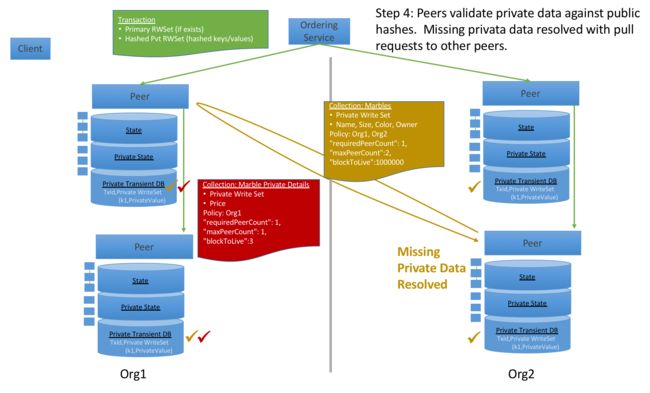
在commit之前,peer首先去判断自己是否通过collection policy的检查,若通过,将去检查自己的瞬时数据库中是否有真实的私密数据,如果没有,将尝试从别的peer处拉取数据。

取到私密数据后,首先去和公共数据的hash去做比对,若一致,此时进行commit操作,将私密数据的HASH写入到公共数据库中。提交该交易和这个区块到账本中,成功提交后,私密数据将会从瞬时数据库拷贝到私密数据库中,并从瞬时数据库中删除。此时整个交易流程结束,数据成功写入到账本内。
如何定义私密数据 collection
一个collection定义包含一个或多个collection,在合约实例化
的时候安装该collection。cli去部署集合时,使用参数 --
collections-config。
peer chaincode instantiate -o orderer.example.com:7050 --tls $CORE_PEER_TLS_ENABLED --cafile $ORDERER_CA -C mychannel -n marblesp -v 1.0 -c '{"Args":["init"]}' -P "OR ('Org0MSP.member','Org1MSP.member')" --collections-config collections.json
collection的集合定义
name: 集合名称。
policy: 语法与签名policy一致,允许哪些组织的peer保存私密数据。私有数据的policy成员必须包含在签名policy的成员内。每个policy都类似于一个过滤器 ,第一 层过滤为签名policy,第二层为私密数据policy。若签名policy未通过验证,交易将执行失败,也就不会产生私密数据。第二种情况是当签名policy通过,但私密数据policy未通过,将没有peer保存真正的私密数据,只会将hash过的数据保存下来,私密数据也将会丢失,这样的 policy定义是没有意义的。
requiredPeerCount: 配置最小分发私有数据peer的数 ,在 peer背书交易和返回给SDK的时间段。当配置为0时,表示不需要分发,但是当maxPeerCount大于0时,还是会分发,分不分发是由这两个配置项共同决定的。当都是0的情况下,私密数据是存在丢失的可能性。该值必须小于等于maxPeerCount。
maxPeerCount:基于私密数据冗余的目的,将数据分发到其他peer的数量 。如果背书节点挂掉,在背书和commit阶段,其他处于collection的peer节点将不能接收到该节点的私密数据, 将从其余已经分发的节点去pull数据。如果这个值设置为0,私密数据在交易背书时间段没有分发,将强制向所有peer去尝试pull私密数据。
blockToLive:私密数据生效时长 ,在私密数据库中保存的时长,将为特定的几个块生效,是时间到达后,将会被清除,再也查不到该数据。 设置为0,将一直被保存,永不清除。
一个有权限保存私有数据的peer,丢失了私密数据,在将来的交易中引用私密数据时,将报错,此处体现 requiredPeerCount和maxPeerCount 的重要性。
collection需要配合chaincode使用,chaincode的shim提供了以下接口:
PutPrivateData(collection,key,value) GetPrivateData(collection,key) GetPrivateDataByRange(collection, startKey, endKey string) GetPrivateDataByPartialCompositeKey(collection, objectType string, keys []string)
Couchdb
GetPrivateDataQueryResult(collection, query string)
使用私密数据的chiancode注意事项:
1、使用couchdb时,sdk去执行range或富查询时,可能只返回结果集的子集,有些peer可能不含有私密数据。sdk可以向多个peer去查询并且比较查询结果,可以确定某些peer是否缺少数据。
2、chaincode在执行range或富查询时,不支持在同一个交易中执行update操作,因为无法判断peer是否有权限拥有私密数据权限,或是否丢失私密数据。如果chaincode在一条交易中包含查询私密数据和更新私密数据两步操作,这个proposal将返回 Error。如果你的有这个需求,请分为两条交易去执行。但是一个chaincode方法中既包含GetPrivateData() 和PutPrivateData()却是可以的,因为所有peer都包含有哈希key的版本号。
3、私密数据collection仅仅定义了组织下的peer能否接收和保存私密数据,意味着仅有某些peer可以查询私密数据,collection不能限制谁调用chaincode。没有限制权限的sdk都可以执行chiancode内部逻辑,最好是在chaincode 内部使用GetCreator() 来控制调用chaincode的权限。
私密数据清除
想要在peer上永久保存私密数据,将blockToLive设置为0即可。我们都知道,当一条包含私密数据的交易在fabric中commit之后,私密数据将会在peer的瞬时数据库中清除,但是若这条交易从不提交,私密数据将会永久保存在瞬时数据库中。 这时就用到一个配置peer.gossip.pvtData.transientstoreMaxBlockRetention,当符合配置
时,将清除私密数据从瞬时数据库中。
私密数据在core.yaml中的gossip配置
pullRetryThreshold: pull私密数据的超时时间,超时后将提交一个没有私
密数据的block。
transientstoreMaxBlockRetention: 当私密数据在瞬时数据库中存储时,它与当时账本中的区块高度有关,该配置定义了当前区块的高度与保证不会清除私密数据之间的最大差异。即每当commit的区块高度达到该配置的倍数时,将触大发清除瞬时数据库中的私密数据。
pushAckTimeout:在背书交易的时候,将私密数据push到其他区块的握手超时时间。
btlPullMargin: 作缓冲区的区块数 量,新增peer时,当peer解析到私密数据的公共信息时,会得到私密数据所在区块的编号,这时会去判断 (账本高度+ btlPullMargin) > (私密数据所在区块高度+btl),如果成立,将不会去获取这个私
密数据,将提交一个没有私密数据的block到自己账本。btlPullMargin默认值是10,若btl小于10,新增peer将不会同步任何私密数据。
转载请注明出处:https://www.cnblogs.com/zooqkl