sklearn的随机森林实现泰坦尼克号旅客生存预测
sklearn的随机森林实现泰坦尼克号旅客生存预测
- 介绍
- 数据集介绍
- 算法
- 学习器
- 分类器
- 实现
- 数据下载与导入
- 预处理
- 建立模型
- 评估,预测
- 结果
- 代码
介绍
参考资料:
https://wenku.baidu.com/view/4f617189bb0d4a7302768e9951e79b896902685d.html
https://wenku.baidu.com/view/f83b4b86182e453610661ed9ad51f01dc2815791.html
https://blog.csdn.net/w952470866/article/details/78987265/
决策树、随机森林——泰坦尼克号生死预测示例
数据集介绍


boat(船),body(身体),home(家庭地址)看起来没什么用,删去。
算法
随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
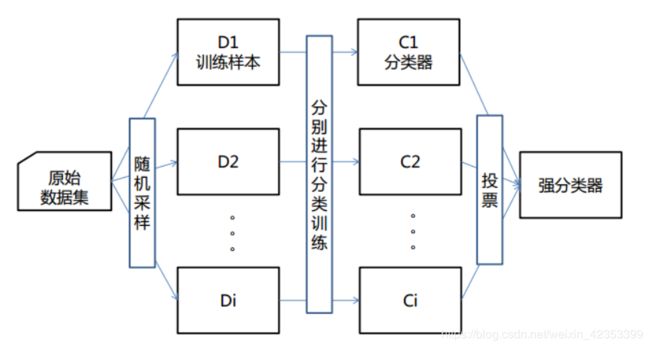
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。在分类问题中,表示基于特征对实例进行分类的过程,可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
信息熵:表示变量的不确定性
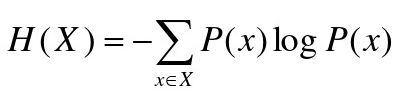


信息增益:(A为一个属性)
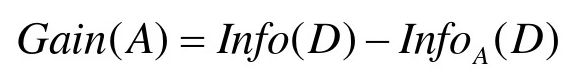
学习器
假设X是训练样本,共有N个训练样本,每个样本有M维特征。
1、从N个样本中抽取n个。
2、从M个特征向量中抽取m个。
3、建立一棵决策树:
(1)、计算每个属性的信息增益
G a i n ( i ) = I n f o ( D ) − I n f o i ( D ) , i ∈ m Gain(i)=Info(D)-Info_i(D),i∈m Gain(i)=Info(D)−Infoi(D),i∈m
(2)、取信息增益最大的那个属性作为决策树的节点,对于该属性的每个值生成分支,并将与该分支有关的数据收集成分支节点的数据表,在表中删除节点属性那一栏。
(3)、若分支数据表属性非空,重复步骤(1)、(2)、(3),否则表示已到达叶属性。
(4)、重复(1)~(3),直到数完全建成。
4、重复1~3,得到H棵决策树。
分类器
对于新样本a,用每一棵决策树对它分类一遍,得到H个分类结果。
根据分类结果所属的最多的类别,判断a所属类别。
实现
数据下载与导入
#获取数据
data_url="http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls"#下载网址
data_file_path="data/titanic3.xls"
if not os.path.isfile(data_file_path):
result=urllib.request.urlretrieve(data_url,data_file_path)
print('downloaded',result)
else:
print(data_file_path,'data file already exists.')
df_data=pd.read_excel(data_file_path)#读excel
selected_cols=['survived','name','pclass','sex','age','sibsp','parch','fare','embarked']#挑出需要的列
selected_df_data=df_data[selected_cols]
预处理
数据有缺失,需要估计填补(目前以平均值填补)。
文字数据需要转化为数字。
所有变量都要归一化处理。
#数据处理
def prepare_data(df_data):
df=df_data.drop(['name'],axis=1)#名字训练时不需要,去掉
age_mean=df['age'].mean()
df['age']=df['age'].fillna(age_mean)#缺失的年龄以平均值填充
fare_mean=df['fare'].mean()
df['fare']=df['fare'].fillna(fare_mean)#缺失的票价以平均值填充
df['sex']=df['sex'].map({'female':0,'male':1}).astype(int)#文字转化为数字表示
df['embarked']=df['embarked'].fillna('S')#缺失值用最多的值取代
df['embarked']=df['embarked'].map({'C':0,'Q':1,'S':2}).astype(int)#文字转化为数字表示
ndarray_data=df.values
features=ndarray_data[:,1:]#没有生存情况
label=ndarray_data[:,0]#生存情况
minmax_scale=preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features=minmax_scale.fit_transform(features)#归一化
return norm_features,label
shuffled_df_data=selected_df_data.sample(frac=1)#打乱顺序
x_data,y_data=prepare_data(shuffled_df_data)
train_size=int(len(x_data)*0.8)#80%的数据训练,20%的数据测试
x_train=x_data[:train_size]#训练数集
y_train=y_data[:train_size]
x_test=x_data[train_size:]#测试数集
y_test=y_data[train_size:]
建立模型
随机森林的随机表示2重随机: 第一重是样本随机,有放回的随机抽样,所有的树,都抽取一样的样本数量;第二重是特征随机,有放回的随机抽样,所有的树,都抽取一样的特征数量。用随机取出来的样本数和特征数生成决策树的分类问题就是投票,回归问题就是求平均。
sklearn.ensemble.RandomForestClassifier(
n_estimators=10(森林里树的数目),
criterion=‘gini’(树分裂的规则:gini系数,entropy熵),
max_depth=None(树的最大深度,如果值为None,那么会扩展节点,直到所有的叶子是纯净的,或者直到所有叶子包含少于min_sample_split的样本。),
min_samples_split=2(分割内部节点所需要的最小样本数量),
min_samples_leaf=1(需要在叶子结点上的最小样本数量),
min_weight_fraction_leaf=0.0(一个叶子节点所需要的权重总和(所有的输入样本)的最小加权分数),
max_features=’auto’(寻找最佳分割时需要考虑的特征数目,如果是auto,那么取n_features的平方根值),
max_leaf_nodes=None(如果为None,那么不限制叶子节点的数量),
min_impurity_decrease=0.0(如果节点的分裂导致的不纯度的下降程度大于或者等于这个节点的值,那么这个节点将会被分裂),
min_impurity_split=None(分裂的最小不纯度),
bootstrap=True(建立决策树时,是否使用有放回抽样),
oob_score=False(是否使用袋外(out-of-bag)样本估计准确度),
n_jobs=1(用于拟合和预测的并行运行的工作(作业)数量。如果值为-1,那么工作数量被设置为核的数量),
random_state=None(随机数种子,如果为None,则随机数生成器是np.random使用的RandomState实例),
verbose=0(控制决策树建立过程的冗余度),
warm_start=False(如果设置为True,在之前的模型基础上预测并添加模型,否则,建立一个全新的森林),
class_weight=None)
srfc = RandomForestClassifier(n_estimators=200, max_depth=5)
srfc.fit(x_train, y_train)
评估,预测
评估:
# 准确度
print("分类得分:",srfc.score(x_test, y_test))
from sklearn.metrics import classification_report
y_pre=srfc.predict(x_test)
print(classification_report(y_test,y_pre))
预测:
Jack_infor=[0,'Jack',3,'male',23,1,0,5.000,'S']
Rose_infor=[1,'Rose',1,'female',20,1,0,100.000,'S']
new_passenger_pd=pd.DataFrame([Jack_infor,Rose_infor],columns=selected_cols)#创建新旅客的表单
all_passenger_pd=selected_df_data.append(new_passenger_pd)#与旧的合成
x,y=prepare_data(all_passenger_pd)
y_pre=srfc.predict(x[-2:,:])
print("Jack与Rose,")
for i in range(len(y_pre)):
print("生存:",y_pre[i])
结果
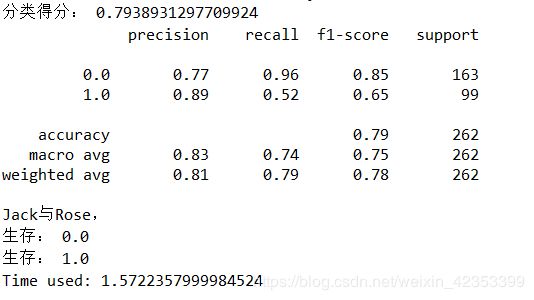

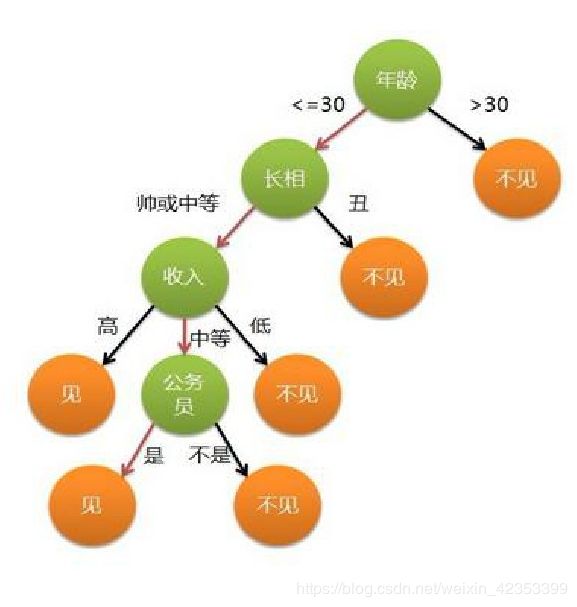
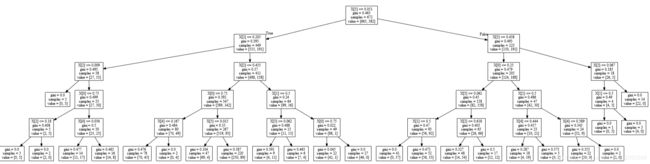
建立了200棵决策树,树的最大深度为五。
其中一棵决策树:


代码
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn import tree
# 作图的库需要安装python-graphviz
import graphviz
import pydotplus
from sklearn import preprocessing
from IPython.display import Image
import os
import time
start = time.clock()
data_url="http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls"
data_file_path="data/titanic3.xls"
if not os.path.isfile(data_file_path):
result=urllib.request.urlretrieve(data_url,data_file_path)
print('downloaded',result)
else:
print(data_file_path,'data file already exists.')
df_data=pd.read_excel(data_file_path)
selected_cols=['survived','name','pclass','sex','age','sibsp','parch','fare','embarked']
selected_df_data=df_data[selected_cols]
def prepare_data(df_data):
df=df_data.drop(['name'],axis=1)
age_mean=df['age'].mean()
df['age']=df['age'].fillna(age_mean)
fare_mean=df['fare'].mean()
df['fare']=df['fare'].fillna(fare_mean)
df['sex']=df['sex'].map({'female':0,'male':1}).astype(int)
df['embarked']=df['embarked'].fillna('S')
df['embarked']=df['embarked'].map({'C':0,'Q':1,'S':2}).astype(int)
ndarray_data=df.values
features=ndarray_data[:,1:]
label=ndarray_data[:,0]
minmax_scale=preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features=minmax_scale.fit_transform(features)
return norm_features,label
shuffled_df_data=selected_df_data.sample(frac=1)
x_data,y_data=prepare_data(shuffled_df_data)
train_size=int(len(x_data)*0.8)
x_train=x_data[:train_size]
y_train=y_data[:train_size]
x_test=x_data[train_size:]
y_test=y_data[train_size:]
'''
dtf = DecisionTreeClassifier(min_samples_split=4) # max_depth=5,criterion="entropy"
dtf.fit(x_train, y_train)
# 准确度
print(dtf.score(x_test, y_test))
dot_tree = export_graphviz(dtf,out_file=None,
feature_names=['age', 'sex', 'pclass','sibsp','parch','fare','embarked'],
class_names=["生", "死"],filled=True, rounded=True,special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_tree)
img = Image(graph.create_png())
graph.write_png("out.png")
'''
srfc = RandomForestClassifier(n_estimators=200, max_depth=5)
srfc.fit(x_train, y_train)
# 准确度
print("分类得分:",srfc.score(x_test, y_test))
from sklearn.metrics import classification_report
y_pre=srfc.predict(x_test)
print(classification_report(y_test,y_pre))
Jack_infor=[0,'Jack',3,'male',23,1,0,5.000,'S']
Rose_infor=[1,'Rose',1,'female',20,1,0,100.000,'S']
new_passenger_pd=pd.DataFrame([Jack_infor,Rose_infor],columns=selected_cols)#创建新旅客的表单
all_passenger_pd=selected_df_data.append(new_passenger_pd)#与旧的合成
x,y=prepare_data(all_passenger_pd)
y_pre=srfc.predict(x[-2:,:])
print("Jack与Rose,")
for i in range(len(y_pre)):
print("生存:",y_pre[i])
elapsed = (time.clock() - start)
print("Time used:",elapsed)
Estimators = srfc.estimators_
for index, model in enumerate(Estimators):
filename = str(index) + '.pdf'
dot_data = tree.export_graphviz(model , out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
graph.write_pdf(filename)