《全面掌握Linux C语言嵌入式系统移植教程》学习笔记(Liunx速查简明)
全面掌握Linux C语言嵌入式系统移植教程学习笔记(Liunx速查简明)
- 笔记前言:
- P3: shell命令简明
- P4: vi /vim编辑器入门
- P5:vi /vim编辑器扩展
- P8: gcc编译和调试初级
- P9: 数据类型1
- P10: 数据类型2
- P11,P12,P13:常量与变量
- P67:Linux 历史与发展
- P68,P69:deb软件包管理
- P70:Linux的shell
- P149:标准I/O上1(文件与流)
- P150:标准I/O上2(流的打开和关闭)
- P151:标准I/O上3(流的读写)
- P153:流的按对象读写
- P154:流的刷新,定位,是否出错和结束
- P155:流的格式化输出:
- P156,P157:Linux下的文件I/O:
- P73:shell命令
- P79:shell脚本编程
- P84:GDB调试
- P87:共用体与typedef
- P88,P89:内存管理
- P90,P91,P92:makefile(先学韦老师的)
- P158:文件属性,目录操作
- P159:库的基础知识和静态库的制作
- P160:共享库的制作
- P161:进程编程1
- P162:进程编程2
- P163,P164:进程编程3
- 网络的封包与拆包
- 网络基础知识
- 网络编程的预备知识:socket,ip,端口和字节序
笔记前言:
很早的时候就听说过Linux 。我与Linux打招呼应该是高二的时候:买了个树莓派3B。
大一里做ROS机器人,搭web服务器;大二上搭编译服务器,缓存服务器,做自动驾驶小车等也与Linux打了一些交道。
尽管我的Linux虚拟机和实体机也装过几台了,但一直没能系统而全面的学习Linux。正赶上今年冠状病毒疫情,寒假延长,我决定拿出每天固定的时间,与414b核心组成员一起针对嵌入式Linux做一下系统性的学习。
不出意外,学习笔记将会每天更新,大家仅作参考
P3: shell命令简明
./ //当前相对路径
../ //上级相对路径
pwd //当前目录名
gcc [代码文件名] -o [可执行文件名] //编译并生成自命名的可执行文件
./[可执行文件名] //运行程序
cat //连接到文件并打印输出
选项: -s //去掉重复的空行
-b //给非空行编号
nl //相当于cat -b
head -n //显示前n行(默认10)
tail -n //显示后n行
cp //复制文件
选项: -r //复制文件夹
-i //覆盖时交互提示
file1 file2 file3 dest 复制多个文件到dest目录
mv //移动、重命名
-r //移动文件夹
file1 file2 file3 dest 拷贝多个文件到dest目录
touch //创建文件、更新时间戳
rm //删除文件
选项: -r //删除文件夹
-f //强制删除
mkdir //创建文件夹
-p //级联创建文件夹
P4: vi /vim编辑器入门
vim [文件名] //打开文件,进入命令模式
i //进入插入模式,可编辑代码
I //行首转插入(易忘)
a //进入插入模式,光标下右移一个,可编辑代码
A //行尾转插入(易忘)
Esc //退出插入模式,返回命令行模式
dd //剪切当前行
[N]dd //剪切从光标位置开始的N行到缓冲区
:A,B d //剪切从行号A到行号B的行到缓冲区(包括A和B)
yy //复制当前行
[N]yy //复制从光标位置开始的N行到缓冲区
:A,B y //复制从行号A到行号B的行到缓冲区(包括A和B)
p //粘贴
u //撤销(重要)
:w //保存代码
:w filename //另存为文件为filename
:r //读入文件插进来
:q //退出
:q! //强制不保存退出(慎用!)
:x //保存并退出
:wq //保存并退出
P5:vi /vim编辑器扩展
H //光标到文件头
G //光标到文件尾
:N //移动光标到第N行
:set nu //显示行号
:set nonu //关闭行号
:/ //查找
//再按n(小写)查看下一个匹配
//按N(大写)查看上一个匹配

其中:% =1,$ 为全文替换
/g 符合的全部替换 不加仅换第一个
P8: gcc编译和调试初级
(1)Shell清屏:Ctrl+L
(2)Gcc编译命令:gcc 1.c -o hello
注意:-o 后面加的是可执行程序的文件名,不是一个独立的参数
要是写反了像这样
gcc hello -o 1.c
就不对了(会把你辛苦写的c代码变没哦,注意!)
所以我认为要从现在养成习惯,只写这一种写法:
gcc 代码文件 -o 可执行程序的文件名
(3)gcc编译错误是可以展示的,和电脑上编译器一样一样(之前以为错了就告诉你错了,不说为什么)
(4)加-Wall指令:提示语法警告
(5)不指定输出文件名:gcc 1.c 则默认生成a.out (也是可以执行的)
P9: 数据类型1
(2)关于数据类型的bool:bool不是基本类型,直接用报错
加#include
(3)if 非零为真:所以if(-1){do();}会执行do()
P10: 数据类型2
(1)易混的类型字长做个解释:
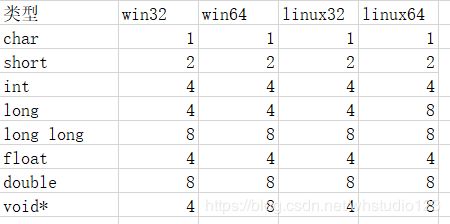
(关于KEIL-MDK中数据类型,可以查看我的文章:KEIL MDK 和 STM32 的数据类型 一篇就够了)
(2)shell:查看ASCII码表:man ASCII
P11,P12,P13:常量与变量
(1)指数常量:
1.176e+10 表示:1.176x10^10
-3.5789e-8 表示:-3.5789x10^-8
通常表示特别大或特别小的数
(2)变量的存储类型:
auto:局部变量
初值随机:

重定义后原变量销毁:
(2)register:寄存器类型,加快运行速度
1.申请不到就使用一般内存,同auto
2.不能用“&”获取register变量的地址
3.某些情况反而会降低运行速度
所以,不必要时也不用加
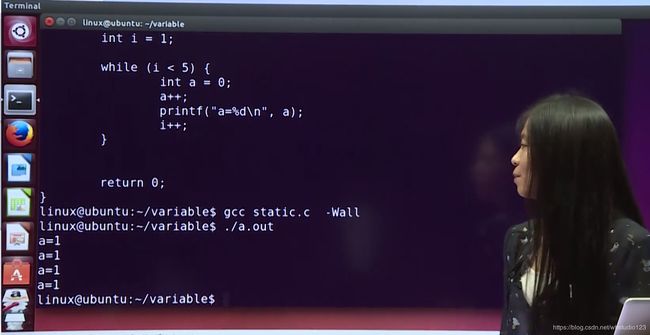
(3)static:静态存储类型
可修饰全局也可修饰局部
1.默认是0;(全局变量默认也是0)
2.内存中以固定位置存放,而不是以堆栈的形式存放
3.只要程序未结束,就不会消失。
4.使用static修饰全局变量后,其他文件即使使用extern也引用不到(将变量的作用范围留在了该文件中)
比较static作用:
不加static:
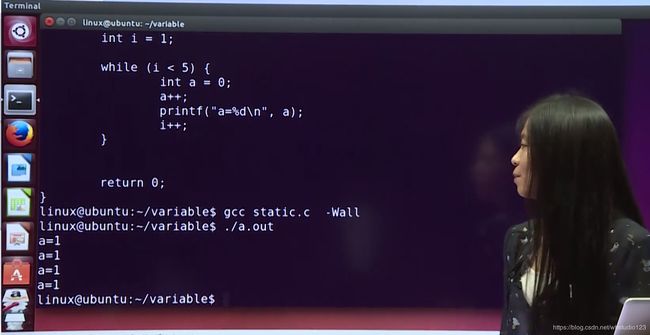
加static:

auto重定义后原变量销毁(每一次都执行初始化和赋值)
而static不销毁(只第一次执行初始化和赋值,其余次数不执行)
(4)extern:
当一个变量在文件的函数体外定义,就是一个全局变量,当外界文件想要引用时使用extern引用

总结:关于变量几点注意:
1.养成习惯,无论什么类型,对变量赋初值。
2.养成变量好的变量定义和初始化的位置,不要玩花活,尽可能明显易懂。
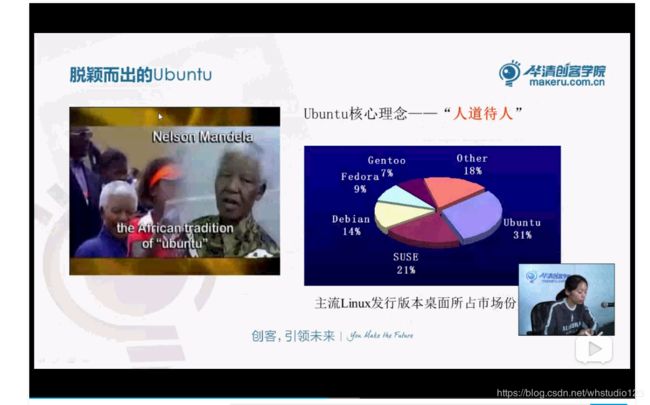
P67:Linux 历史与发展
GPL协议强调Copy Left ,是自由软件的倡导者,并不是免费软件,而是用户应该拿到软件的源代码。
与CopyRight(版权)理念相较量。

P68,P69:deb软件包管理

Ubuntu下常用的两个软件包管理工具:
dpkg:用来直接安装.deb软件包,不去解决依赖问题,适合成型后将各种deb都准备好的情况下安装。
apt :检查和修复依赖关系,自动解决依赖问题,利用Internet主动获取软件包
(1)dpkg:
dpkg -i <package> //安装本地软件包
dpkg -r <package> //移除安装包
dpkg -P <package> //卸载
dpkg -L <package> //列出安装的软件包清单
dpkg -s <package> //显示软件包安装状态
(2)apt:
update //下载更新软件包列表信息
upgrade //升级所有软件包
install //下载安装
remove //卸载
autoremove
source
build-dep
dist-upgrade
dselect-upgrade
clean
重点强调:
1.update与upgrade:

update 是下载更新软件包列表信息,相当于知道一下现在各种软件都在网上什么地址呢,并不更新软件
upgrade升级所有软件包,更新软件到最新版本
2.下载下来的软件包的位置:
/var/cache/apt/archives/
以后想要在其它机器上部署什么软件,但目标机器无条件联网,就可以把这个目录拷贝过去安装。

3.查看软件包之间的依赖:

P70:Linux的shell

Ubuntu的 shell 默认安装的是 dash,而不是 bash。
运行以下命令查看 sh 的详细信息,确认 shell 对应的程序是哪个:
$ls -al /bin/sh
dash 比 bash 更轻,更快。但 bash 却更常用。
如果一些命令、脚本等总不能正常执行,有可能是 dash 的原因。
比如编译 Android 源代码的时候,如果使用 dash,则有可能编译出错,或者编译的系统不能启动。
通过以下方式可以使 shell 切换回 bash:
$sudo dpkg-reconfigure dash
然后选择 no 或者 否 ,并确认。
这样做将重新配置 dash,并使其不作为默认的 shell 工具。
也可以直接修改 /bin/sh 链接文件,将其指定到 /bin/bash:
$sudo ln -fs /bin/bash /bin/sh
还有一种解决方法是,在脚本文件中直接指定使用的 shell,而不是指定 sh:
例如使用 #!/bin/bash 或者 #!/bin/dash 而不是#!/bin/sh。
但这样将丧失脚本的通用性,使其在不具备所指定脚本的系统下不能被执行。

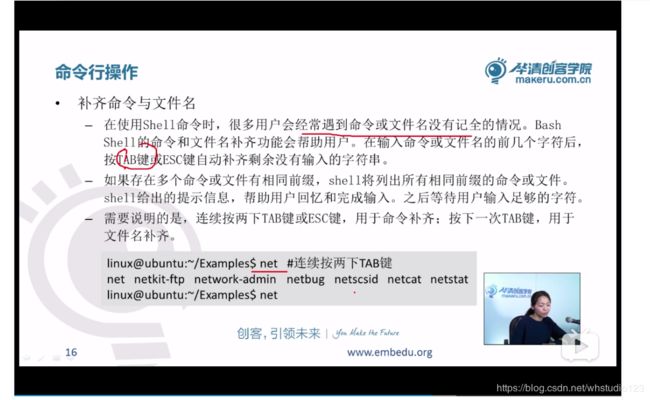
补齐命令与补齐文件名:
历史记录:
还可以修改保存的历史大小:
在bashrc中修改$HISTSIZE
P149:标准I/O上1(文件与流)
(1)Linux文件分类:
常规文件(r)
目录文件(d)
字符设备文件(c):每一个文件代表一个设备
块设备文件(b)
管道文件(p):进程间通信
套接字文件(s):网络通信/本地通信
符号链接文件(l):类似于快捷方式
强调:不同操作系统所支持的文件类型不同!
(2)标准I/O:
说白了一组函数(API)
标准I/O自动开辟缓冲区,通过缓冲机制减少系统调用,实现更高效率。
(3)流:FILE结构体
(4)流的三种缓冲类型:
全缓冲
行缓冲
无缓冲
行缓冲是当遇到”\n”的时候执行I/O操作
注意:终端的标准输入输出就是行缓冲
所以:printf(“hello world”);不对,看不到
printf(“hello world\n”);对,看得到
P150:标准I/O上2(流的打开和关闭)
(1)注意:

w、wb、w+、w+b都是:
如果文件存在,则清空
所以w+、w+b的可读写的读是:
程序写后的内容可读(原有文件的内容已经清空)
(2)打开文件实验代码:
#include(3)fopen()创建 的文件访问权限为0666
(rw-rw-rw-)
但这不是最后的权限
最后的权限=0666&(~umask)
用户可以在程序中设置umask,只对自己程序有效,对其它程序无影响。
当umask=0时,最后的权限不受umask影响
(4)处理错误信息实验代码:

#include(5)流的关闭

1.不使用流的时候应当关闭,养成好习惯
2.流关闭后不能进行任何操作,否则可能有不可预知的后果。
(6)
.Linux打开流的个数有限制,一般为1024
1021+stdin+stdout+stderr=1024
能打开的个数剩下1021个
P151:标准I/O上3(流的读写)
(1)流的读写:
1.读写一个字符:fgetc()/fputc()一次读/写一个字符
效率比较低
2.读写一行:fgets()和fputs()一次读写一行
一般只适用于文本文件,用于二进制文件会有问题
3.读写若干对象:fread()/fwrite()
每个对象具有相同的长度
效率较高
文本/二进制均可,一般使用这个
(2)fgetc实例:
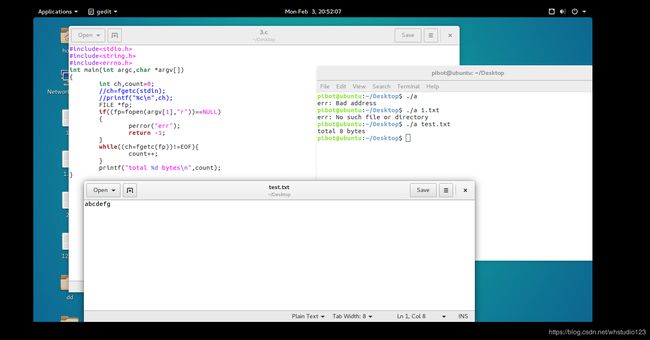
#include(3)fput函数
int fputc(int c ,FILE *fp)
c:想要输出的字符
*fp:流指针
返回值:
成功:输入的值
失败:EOF
(4)实验:
使用fgetc() 和fputc()实现文件的复制
#includeP153:流的按对象读写
size_t fread(void *buf,size_t size,size_t n,FILE *fp);
void *buf:缓冲区首地址
size_t size: 每一个对象占的大小
size_t n:这一次要从流中读取多少个对象
返回值:
成功读的对象个数;出错返回EOF
size_t fwrite(void *buf,size_t size,size_t n,FILE *fp);
void *buf:缓冲区首地址
size_t size: 每一个对象占的大小
size_t n:这一次要从流中写入多少个对象
返回值:
成功写的对象个数;出错返回EOF
既可以读写文本,也可以读写数据。
P154:流的刷新,定位,是否出错和结束
刷新流:
1.缓冲区满时
2.程序关闭时
3.使用fflush时
*int fflush(FILE fp);
成功时返回0,出错返回EOF;
将流缓冲区中的数据写入实际文件
Linux下只能刷新输出缓冲区,不能刷新输入缓冲区
定位流:



判断流是否出错和结束:

P155:流的格式化输出:
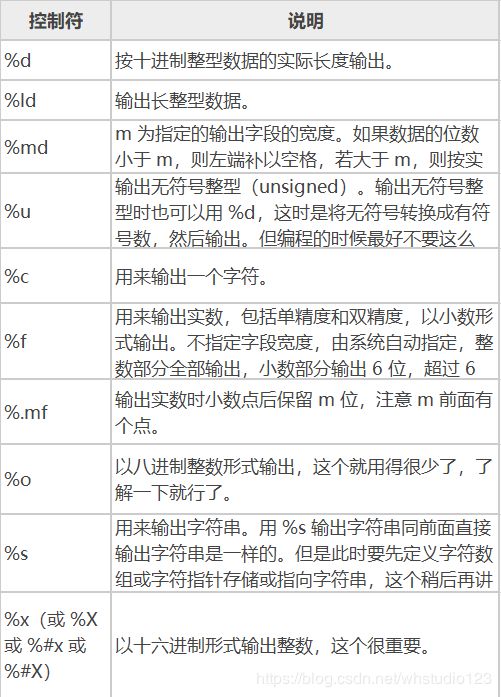
我们常用的就是:
%s 用来输出字符串
%d 按十进制整型数据的实际长度输出
%c 用来输出一个字符
%f 输出一个实数
fprintf实例:
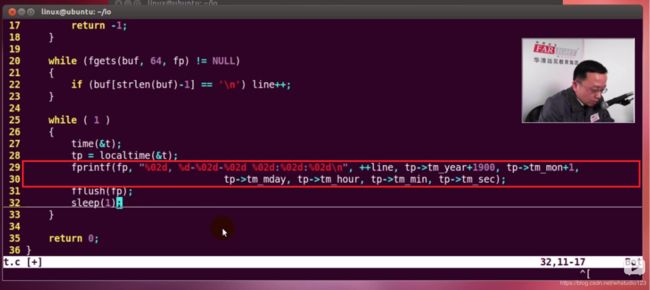
P156,P157:Linux下的文件I/O:
(1)标准I/O和文件I/O的区别:
文件I/O 又称为低级磁盘I/O,遵循POSIX相关标准。任何兼容POSIX标准的操作系统上都支持文件I/O。
标准I/O被称为高级磁盘I/O,遵循ANSI C相关标准。只要开发环境中有标准I/O库,标准I/O就可以使用。
(Linux 中使用的是GLIBC,它是标准C库的超集。不仅包含ANSI C中定义的函数,还包括POSIX标准中定义的函数。因此,Linux 下既可以使用标准I/O,也可以使用文件I/O)。
通过文件I/O读写文件时,每次操作都会执行相关系统调用。这样处理的好处是直接读写实际文件,坏处是频繁的系统调用会增加系统开销,
标准I/O可以看成是在文件I/O的基础上封装了缓冲机制。先读写缓冲区,必要时再访问实际文件,从而减少了系统调用的次数。
标准I/O以流为核心概念
文件I/O以文件描述符为核心概念
(2)函数和引用头文件:
打开文件函数:
#include
#include
#include
int open(const char *pathname, int flags);//打开一个现有的文件
int open(const char *pathname, int flags, mode_t mode);
//如果打开文件不存在,则先创建它
关闭文件函数:
#include
int close(int fd);
创建文件函数:
#include
#include
#include
int creat(const char *pathname, mode_t mode);
上面==int open(const char *pathname, O_WRONLY|O_CREAT|O_TRUNC, mode_t mode);
写文件函数:
#include
ssize_t write(int fd, void *buf, size_t count);
文件偏移定位函数:
#include
#include
off_t lseek(int fds, off_t offset, int whence);
读文件函数:
#include
ssize_t read(int fd, void *buf, size_t count);
Linux的高级文件操作:
文件状态操作函数:
#include
#include
int stat(const char *pathname, struct stat *sbuf);
int fstat(int fd, struct stat *sbuf);
int lstat(const char *pathname,struct stat *sbuf);
时间相关函数:
unsigned longst_atime; //最近一次访问文件时间
unsigned longst_mtime; //最近的修改文件时间
unsigned longst_ctime; //最近一次对文件状态进行修改的时间
#include
#include
int utime(const char *pathname, const struct utimebuf *times);
总结:
也别分这么细,使用文件I/O时,把下面这四个头写过去:
#include
#include
#include
#include
(3)函数详解:
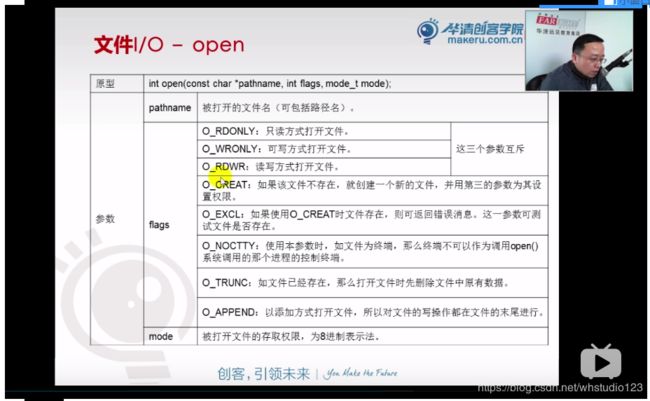






再来一遍参数:
P73:shell命令
P79:shell脚本编程
P84:GDB调试
P87:共用体与typedef
P88,P89:内存管理
P90,P91,P92:makefile(先学韦老师的)
P158:文件属性,目录操作
(1)实验代码:
#include(2)使用man命令查看 函数对应头文件和用法:
man 2 函数
(3)vim直接打开到指定行数:到第30行
vim 1.c +30
P159:库的基础知识和静态库的制作
(1)库:
库有源码,可下载后编译,也可以直接安装二进制包
Windows和linux库文件格式不兼容
Linux程序库类型:静态库/共享库
(2)查看库中函数:nm 库文件名
(3)静态库特点(优缺点):

注意:程序运行时不再需要静态库!!
创建一个静态库的过程:
STEP1:写库,并编译库,生成.o文件:
gcc -c libtestlib.c
STEP2:使用ar工具生成.a文件
ar crs libhello.a libtestlib.o
注意:linux对于库文件名有要求:以lib开始,以.a结束,中间夹的是库名,整体叫库文件名
STEP3:编写程序
STEP4:使用gcc带静态库编译
gcc ppp.c -o libtest -L. -lhello
(-L.的含义是搜索当前目录下的库文件)
(-l加库名 //指定库名,-l与库名之间无空格)
附:
libtestlib.c内容(被编译成库,库文件名libhello.a)
#includeppp.c中内容
#includeP160:共享库的制作
共享库:
库升级方便,无需重新编译

系统更多的倾向使用共享库
说明!:共享库流程比静态库复杂,这里编写了一个脚本,自动生成共享库和链接文件,需要看操作过程请看视频!
脚本代码:
lib_c_source_name=$1
lib_version=$2
if [ -f ${lib_c_source_name}.so ];then
echo ERR!:${lib_c_source_name}.so exist,No changes will be writed!
else
gcc -c -fPIC ${lib_c_source_name}.c -Wall
gcc -shared -o ${lib_c_source_name}.so.${lib_version} ${lib_c_source_name}.o
ln -s ${lib_c_source_name}.so.${lib_version} ${lib_c_source_name}.so
rm ${lib_c_source_name}.o
fi
使用:
./slh.sh libhello 1
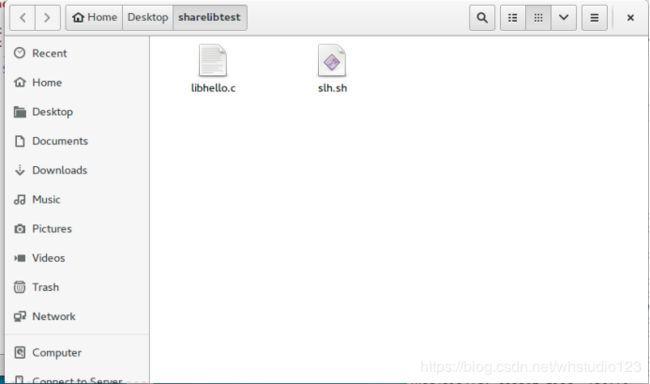
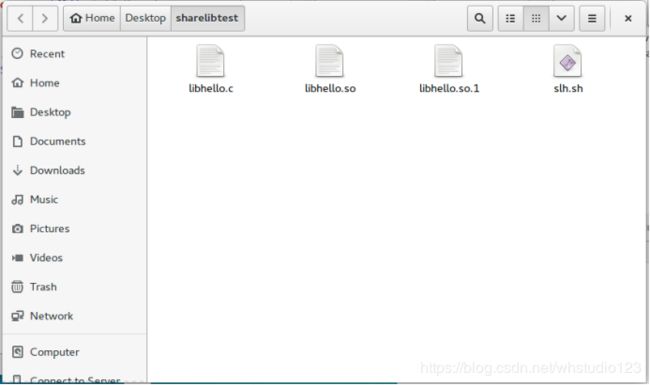
第二个脚本:注册当前目录到系统的库寻找目录中:
脚本代码:
current_dir=$(cd $(dirname $0); pwd)
name=$1
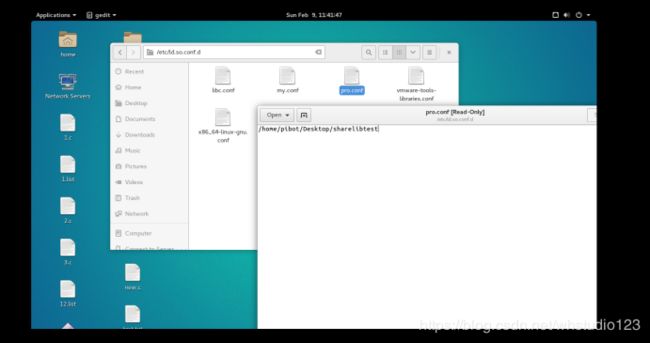
sudo echo "${current_dir}" > /etc/ld.so.conf.d/${name}.conf
使用:
sudo ./reglibdir.sh pro
P161:进程编程1
(1)进程类型:
1.交互进程:
在shell启动,可前台可后台
后台运行例子:./a &
加一个地址符:程序变成后台运行,可以向终端输出,不能捕获终端输入
2.批处理进程:linux下暂不研究
3.守护进程:与终端无关,一直在后台运行
(2)进程状态:
1.运行态:
正在运行
可运行(就绪态)
2.等待态(阻塞态/睡眠态)两种:
可中断
不可中断
3.停止态:进程被中止,收到信号可继续运行。
4.停止态(僵尸态):已终止的进程,但pcb没有释放。
P162:进程编程2
(1)查看进程的shell命令:
1.
ps -ef|grep 程序名
ps aux|grep 程序名
D uninterruptible sleep (usually IO)
R running or runnable (on run queue)
S interruptible sleep (waiting for an event to complete)
T stopped by job control signal
t stopped by debugger during the tracing
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z defunct ("zombie") process, terminated but not reaped by its parent
查看进程的动态信息:
top
类似于windows上的资源管理器
查看进程的详细信息:
/proc
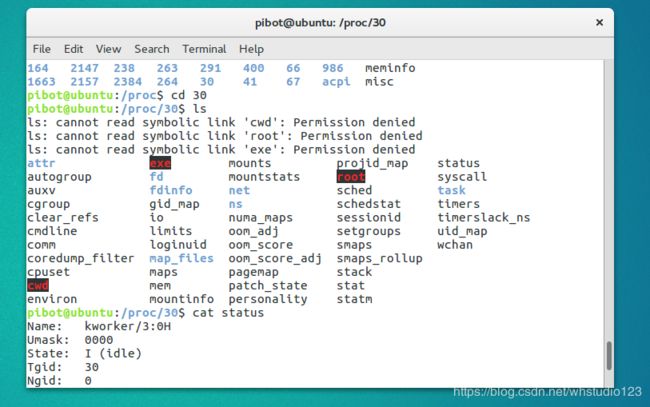
(2)进程相关控制命令:
1.nice
nice值越小,优先级越高,范围为[-20,19] ,只有root账户可以指定负的优先级
默认为0
nice -n 数字 程序
以指定的优先级运行程序
2.renice
renice -n 数字 进程号
改变一个已经运行的进程的优先值
3.jobs
查看后台进程
4.切换:
前台->后台:
后台运行:./a &
加一个地址符:程序变成后台运行,可以向终端输出,不能捕获终端输入
会有一个后台作业号
后台->前台:fg 后台作业号
前台->后台挂起:Ctrl+Z
挂起->后台:bg 后台作业号
P163,P164:进程编程3
(转载ALL 2 WELL笔记)

强调:
(1)
exit()结束进程会刷新缓冲区
_exit()结束进程不会刷新缓冲区
(2)

并且传的参数一定要以NULL做结尾:


(3)
关于sysytem()函数的几点说明:
system()通过调用/bin/sh -c命令执行命令中指定的命令,并在命令完成后返回。在执行命令期间,SIGCHLD将被阻塞,SIGINT和SIGQUIT将被忽略。
阻塞:就是忙完再说
忽略:收到了但是没有任何动作
比如在当前路径下,存在一个名为 a.out 的可执行文件,那么在一个进程main中使用system来执行这个a.out的程序,则可以直接使用
sysRet = system("./a.out");
system是在其实现中调用了fork + exec + waitpid, 执行完毕之后,回到原先的程序中去。继续执行下面的部分。
至于system的返回值
1、如果command是一个空指针,则仅当命令处理程序可用时,system返回非0值。可是使用这一个特性测试当前系统是否支持system函数,UNIX中总是可用的。
2、如果fork失败或者waitpid返回除EINTR之外的出错,返回-1,且设置errno。
3、如果exec失败(即不能执行shell),返回值如同shell实行了exit(127)一样。
4、如果fork,exec,waitpid都执行成功,那返回值是shell的终止状态,可以参见waitpid的说明
使用system而不直接使用fork和exec的优点是:system进行了所需的各种出错的处理以及各种信号的处理。
网络的封包与拆包
网络基础知识
网络的七层模型和四层模型
网络编程的预备知识:socket,ip,端口和字节序
socket
socket是:
1.一个编程的接口,一种特殊的文件描述符
(在Linux系统得到的是一个int 变量,代表着一种网络资源)
2.并不限于TCP/IP协议
3.面向连接和无连接均可
socket的分类:
1.流式套接字:SOCK_STREAM:唯一对应着TCP
2.数据报套接字:SOCK_DGRAM:唯一对应着UDP
3.原始套接字:SOCK_RAW:对应着多种协议:可以对较低层次的协议如IP、ICMP直接访问
IP地址
IP地址:
IPV4:32位的整数
IPV6:128位整数(地球上每一粒沙子分配一个IP地址)
特殊的IP地址:
1.局域网的IP:(以192和10开头)
192.XXX.XXX.XXX
10.XXX.XXX.XXX
2.广播IP:以255结尾
局域网:XXX.XXX.XXX.255
全网:255.255.255.255
3.组播IP:开头224到239
224.XXX.XXX.XXX~239.XXX.XXX.XXX
ip地址转化函数:


注意这个函数的返回值:返回1成功

端口
端口号:系统收到网络包后由哪个任务处理
16位的数字:1~65535
众所周知的端口:1~1023
FTP:21
SSH:22
HTTP:80
HTTPS:469
系统保留端口:1024~5000
可以使用的端口:5001~65535
TCP与UDP端口独立互不影响:TCP5555端口和UDP5555端口可以同时打开,数据包不会串
为什么:内核内做了数据分流,处理路径不同
网络里面的通信由IP地址+端口号确定
字节序
字节序:
不同的CPU访问内存中多字节数据的时候,存在字节序(大小端)的问题
网络统一使用的字节序是大端模式
所以分为网络字节序和本地字节序
Linux提供一些转化函数,有需要可以使用将他们互转