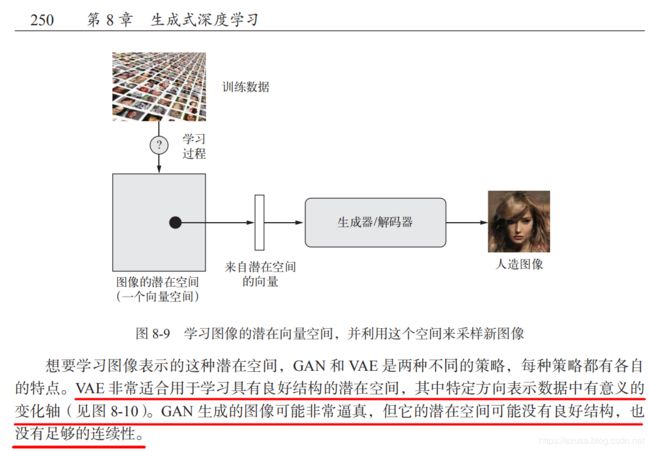
平均值mean 和 方差variance 在变分自编码器(VAE)中的应用
 个人主页
个人主页
1.window下安装 Keras、TensorFlow(先安装CUDA、cuDNN,再安装Keras、TensorFlow)
2.C/C++ 笔记、Python 笔记、JavaWeb + 大数据 笔记
3.Keras 深度学习实战、PyTorch 深度学习、Python 深度学习、动手学 深度学习
4.人工智能AI:Keras PyTorch MXNet 深度学习实战(不定时更新)
5.深度学习、机器学习、人工智能的区别
6.计算机视觉工具GluonCV
7.matplotlib 相关语法详解
8.MXNet 相关函数详解
9.pandas 相关语法详解
10.window下安装MXNet
11.高数 相关知识
12.python 相关语法详解
13.PyTorch 相关函数详解
14.window 安装 PyTorch
15.卷积神经网络
16.卷积神经网络:从头开始构建一个CNN
17.人工智能中 相关的术语概念知识
18.人工智能中 Numpy的 相关函数使用
19.使用 Keras 定义简单神经网络来识别 MNIST 手写数字的网络
20.数据结构与算法(java/python/C实现):时间复杂度、冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、二叉树、队列、链表、栈
21.百度飞浆paddlepaddle下载安装
22.机器翻译 MXNet(使用含注意力机制的编码器—解码器)
23.Keras 相关语法详解
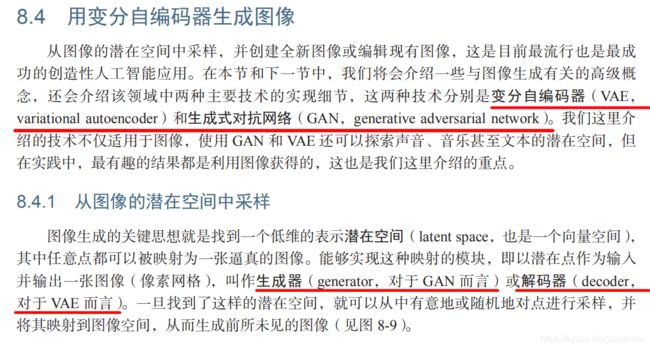




1.构建Model模型的实例对象model
from keras.models import Model
model = Model(input,output)
1.将xx模型实例化出一个model对象,它将一个模型输入input映射为一个模型输出output,
或者说可以理解为把一个模型输入input映射为一个包含多层的整体的模型。
2.模型输入input可以是 keras.Input(shape)、layers.Input(shape)。
3.模型输出output:
可以是一个自定义类的实例对象:class 自定义类名(keras.layers.Layer)的实例对象。
也可以是一个包含多层layers的模型输出:output=layers.xxx(参数)(上一层layers)。
也可以是一个模型实例对象:output=keras.models.Model(input,output)。比如构建GAN模型的例子。
2.model实例对象的多种使用形式
1.output = model(input)
给model实例对象传入真实的模型输入数据,输出对应的目标数据
input为真实的模型输入,output为模型输出
2.model.fit(x=x_train, y=y_train, shuffle=True, epochs=10, batch_size=batch_size, validation_data=(x_test, y_test))
对model实例对象直接进行fit训练,传入用于训练/验证的模型输入和模型输出,可以同时指定shuffle/epochs/batch_size等
3.output = Model实例对象2(Model模型实例对象1(input))
多个Model实例对象进行嵌套连接在一起构建为一个新的网络模型,即Model模型1的输出作为Model模型2的输入。
比如GAN模型中,便把生成器网络模型的实例对象和判别器网络模型的实例对象连接在一起构建为一个新的模型,最终返回判别器网络的模型输出。
3.keras.layers.Layer层:output = layers.Conv2D()/layers.Dense()/layers.Conv2DTranspose()/...
自定义keras.layers.Layer层的形式:
1.class 自定义类名(keras.layers.Layer):
def call(self, inputs):
#可以不使用这个返回输出值,但层必须要有返回值
return x
2.创建自定义Layer层的实例对象:output = 自定义类名(inputs)
4.GAN 生成器网络 和 GAN 判别器网络 的组合
1.GAN 生成器网络
#设置模型输入是一个形状为 (latent_dim,)的随机向量(潜在空间中的一个随机点)
generator_input = keras.Input(shape=(latent_dim,))
x = layers.Dense(128 * 16 * 16)(generator_input)
#构建连续多层layers.Dense/layers.LeakyReLU/layers.Conv2D/layers.Reshape等
......
#构建生成器模型实例对象:把形状为 (latent_dim,)的随机向量(潜在空间中的一个随机点)作为模型输入,
#映射到一个包含多层layers的模型输出网络,最终解码为一张形状为 (32, 32, 3) 的合成图像
generator = keras.models.Model(generator_input, x)
generator.summary()
2.GAN 判别器网络
discriminator_input = layers.Input(shape=(height, width, channels))
x = layers.Conv2D(128, 3)(discriminator_input)
#构建连续多层layers.Dense/layers.LeakyReLU/layers.Conv2D/layers.Flatten/layers.Dropout等
......
#构建判别器模型实例对象:把形状为(32, 32, 3)的图像作为模型输入,映射到一个包含多层layers的模型输出网络,
#最终转换为一个二进制分类决策(即分类为真/假)
discriminator = keras.models.Model(discriminator_input, x)
discriminator.summary()
#clipvalue在优化器中使用梯度裁剪(限制梯度值的范围),decay为了稳定训练过程,使用学习率衰减
discriminator_optimizer = keras.optimizers.RMSprop( lr=0.0008, clipvalue=1.0, decay=1e-8)
discriminator.compile(optimizer=discriminator_optimizer, loss='binary_crossentropy')
3.把生成器网络和判别器网络连接在一起构建一个完整的GAN
#将判别器网络的权重设置为不可训练(仅应用于GAN模型),这样在训练时判别器网络的权重便不会更新,
#否则在训练时可以对判别器的权重进行更新的话,则会导致训练判别器始终预测“真”,但这并不是想要的效果
discriminator.trainable = False
#把形状为 (latent_dim,)的随机向量(潜在空间中的一个随机点)作为模型输入
gan_input = keras.Input(shape=(latent_dim,))
#把生成器网络模型的实例对象 和 判别器网络模型的实例对象 连接在一起构建为一个新的模型,最终返回判别器网络的模型输出
gan_output = discriminator(generator(gan_input))
#构建完整的GAN模型:将形状为 (latent_dim,)的随机向量(潜在空间中的一个随机点)作为模型输入,
#最终模型输出转换为一个分类决策(即分类为真/假),训练时的标签都是“真实图像”,那么将会更新生成器网络的权重,
#使得判别器网络在观察假图像时更有可能预测为“真”,这个模型将让生成器向某个方向移动,从而提高它欺骗判别器的能力
gan = keras.models.Model(gan_input, gan_output)
#clipvalue在优化器中使用梯度裁剪(限制梯度值的范围),decay为了稳定训练过程,使用学习率衰减
gan_optimizer = keras.optimizers.RMSprop(lr=0.0004, clipvalue=1.0, decay=1e-8)
gan.compile(optimizer=gan_optimizer, loss='binary_crossentropy')


1.转置卷积 Conv2DTranspose 可被称为 反卷积、后卷积、分数步⻓卷积(fractionally-strided convolution)。
2.在模型设计中,转置卷积层常⽤于将较小的特征图变换为更⼤的特征图。在全卷积⽹络中,
当输⼊是⾼和宽较小的特征图时,转置卷积层可以⽤来将⾼和宽放⼤到输⼊图像的尺⼨。
3.转置卷积层可以放⼤特征图。在图像处理中,我们有时需要将图像放⼤,即上采样(upsample)。上采样的⽅法有很多,常⽤的有双线性插值。
在全卷积⽹络中,我们将转置卷积层初始化为双线性插值的上采样。

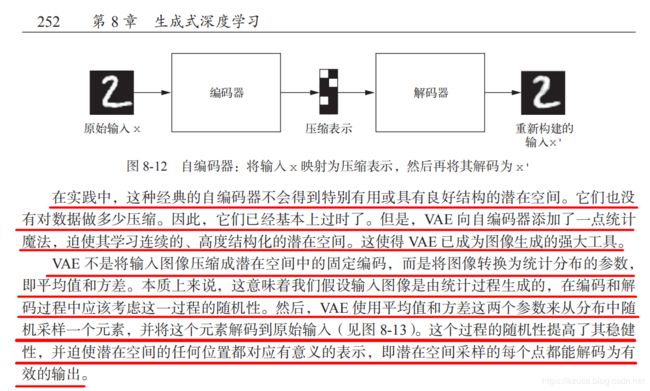
VAE 的参数通过两个损失函数来进行训练:
1.一个是重构损失(reconstruction loss):
xent_loss = keras.metrics.binary_crossentropy(x, z_decoded)
为原始输入和编码-解码后的输出比较,它迫使解码后的样本匹配初始输入。
2.一个是正则化损失(regularization loss):
kl_loss = -5e-4 * K.mean(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
它有助于学习具有良好结构的潜在空间,并可以降低在训练数据上的过拟合
3.最后合并重构损失和正则化损失
K.mean(xent_loss + kl_loss)


1.构建Model模型的实例对象model
from keras.models import Model
model = Model(input,output)
1.将xx模型实例化出一个model对象,它将一个模型输入input映射为一个模型输出output,
或者说可以理解为把一个模型输入input映射为一个包含多层的整体的模型。
2.模型输入input可以是 keras.Input(shape)、layers.Input(shape)。
3.模型输出output:
可以是一个自定义类的实例对象:class 自定义类名(keras.layers.Layer)的实例对象。
也可以是一个包含多层layers的模型输出:output=layers.xxx(参数)(上一层layers)。
也可以是一个模型实例对象:output=keras.models.Model(input,output)。比如构建GAN模型的例子。
2.model实例对象的多种使用形式
1.output = model(input)
给model实例对象传入真实的模型输入数据,输出对应的目标数据
input为真实的模型输入,output为模型输出
2.model.fit(x=x_train, y=y_train, shuffle=True, epochs=10, batch_size=batch_size, validation_data=(x_test, y_test))
对model实例对象直接进行fit训练,传入用于训练/验证的模型输入和模型输出,可以同时指定shuffle/epochs/batch_size等
3.output = Model实例对象2(Model模型实例对象1(input))
多个Model实例对象进行嵌套连接在一起构建为一个新的网络模型,即Model模型1的输出作为Model模型2的输入。
比如GAN模型中,便把生成器网络模型的实例对象和判别器网络模型的实例对象连接在一起构建为一个新的模型,最终返回判别器网络的模型输出。
3.keras.layers.Layer层:output = layers.Conv2D()/layers.Dense()/layers.Conv2DTranspose()/...
自定义keras.layers.Layer层的形式:
1.class 自定义类名(keras.layers.Layer):
def call(self, inputs):
#可以不使用这个返回输出值,但层必须要有返回值
return x
2.创建自定义Layer层的实例对象:output = 自定义类名(inputs)
4.GAN 生成器网络 和 GAN 判别器网络 的组合
1.GAN 生成器网络
#设置模型输入是一个形状为 (latent_dim,)的随机向量(潜在空间中的一个随机点)
generator_input = keras.Input(shape=(latent_dim,))
x = layers.Dense(128 * 16 * 16)(generator_input)
#构建连续多层layers.Dense/layers.LeakyReLU/layers.Conv2D/layers.Reshape等
......
#构建生成器模型实例对象:把形状为 (latent_dim,)的随机向量(潜在空间中的一个随机点)作为模型输入,
#映射到一个包含多层layers的模型输出网络,最终解码为一张形状为 (32, 32, 3) 的合成图像
generator = keras.models.Model(generator_input, x)
generator.summary()
2.GAN 判别器网络
discriminator_input = layers.Input(shape=(height, width, channels))
x = layers.Conv2D(128, 3)(discriminator_input)
#构建连续多层layers.Dense/layers.LeakyReLU/layers.Conv2D/layers.Flatten/layers.Dropout等
......
#构建判别器模型实例对象:把形状为(32, 32, 3)的图像作为模型输入,映射到一个包含多层layers的模型输出网络,
#最终转换为一个二进制分类决策(即分类为真/假)
discriminator = keras.models.Model(discriminator_input, x)
discriminator.summary()
#clipvalue在优化器中使用梯度裁剪(限制梯度值的范围),decay为了稳定训练过程,使用学习率衰减
discriminator_optimizer = keras.optimizers.RMSprop( lr=0.0008, clipvalue=1.0, decay=1e-8)
discriminator.compile(optimizer=discriminator_optimizer, loss='binary_crossentropy')
3.把生成器网络和判别器网络连接在一起构建一个完整的GAN
#将判别器网络的权重设置为不可训练(仅应用于GAN模型),这样在训练时判别器网络的权重便不会更新,
#否则在训练时可以对判别器的权重进行更新的话,则会导致训练判别器始终预测“真”,但这并不是想要的效果
discriminator.trainable = False
#把形状为 (latent_dim,)的随机向量(潜在空间中的一个随机点)作为模型输入
gan_input = keras.Input(shape=(latent_dim,))
#把生成器网络模型的实例对象 和 判别器网络模型的实例对象 连接在一起构建为一个新的模型,最终返回判别器网络的模型输出
gan_output = discriminator(generator(gan_input))
#构建完整的GAN模型:将形状为 (latent_dim,)的随机向量(潜在空间中的一个随机点)作为模型输入,
#最终模型输出转换为一个分类决策(即分类为真/假),训练时的标签都是“真实图像”,那么将会更新生成器网络的权重,
#使得判别器网络在观察假图像时更有可能预测为“真”,这个模型将让生成器向某个方向移动,从而提高它欺骗判别器的能力
gan = keras.models.Model(gan_input, gan_output)
#clipvalue在优化器中使用梯度裁剪(限制梯度值的范围),decay为了稳定训练过程,使用学习率衰减
gan_optimizer = keras.optimizers.RMSprop(lr=0.0004, clipvalue=1.0, decay=1e-8)
gan.compile(optimizer=gan_optimizer, loss='binary_crossentropy')

1.一旦训练好了这样的模型(本例中是在 MNIST 上训练),我们就可以使用 decoder解码网络将任意潜在空间向量转换为图像。
2.此处直接使用 解码器模型Model(decoder_input, x)的实例对象decoder,它可以将 decoder_input转换为解码后的图像。
#1.编码器输入和输出:
# 一个编码器模块将输入样本 input_img 转换为表示潜在空间中的两个向量 z_mean 和 z_log_variance,
# 因此即输入图像最终被编码为这两个向量 z_mean 和 z_log_variance。
# 而 z_mean = layers.Dense(latent_dim)(x) 和 z_log_var = layers.Dense(latent_dim)(x) 两个Dense层输出的向量的形状都均为 (None, 2),
# (None, 2) 即(批量大小/样本数, 2),指的是(batch_size,latent_dim),采样的实际为形状(latent_dim,)的随机向量(潜在空间中的一个随机点)。
#2.解码器输入和输出:
# 假定潜在正态分布能够生成输入图像,并从这个分布中随机采样一个点z,
# z = z_mean + exp(z_log_variance) * epsilon,其中 epsilon 是取值很小的随机张量,
# z、z_mean、z_log_var、epsilon.shape 这四个向量的形状都均是 (None, 2),(None, 2) 即(批量大小/样本数, 2),
# 指的是(batch_size,latent_dim),采样的实际为形状(latent_dim,)的随机向量(潜在空间中的一个随机点)。
# 采样一个潜在点向量z 并对其进行解码,需要两个向量 z_mean 和 z_log_var 二者定义了潜在空间中的一个概率分布。
# 解码器模块就负责将潜在空间的这个潜在点向量z映射回原始输入图像。
#3.编码器和解码器的输入和输出流程:
# 输入图像-->编码器-->向量形状是(None,2)的z_mean和z_log_variance --> z_mean和z_log_variance组装为形状是(None,2)的潜在点向量z --> 解码器 --> 原始输入图像
z = layers.Lambda(sampling)([z_mean, z_log_var])
print("z.shape:",K.int_shape(z)) # (None, 2) 即(批量大小/样本数, 2),指的是(batch_size,latent_dim)
decoder_input = layers.Input(K.int_shape(z)[1:])
print("decoder_input.shape:",K.int_shape(decoder_input)) # (None, 2) 即(批量大小/样本数, 2),指的是(batch_size,latent_dim)
decoder = Model(decoder_input, x)
z_decoded = decoder(z)
print("z_decoded.shape:",K.int_shape(z_decoded)) # (None, 28, 28, 1) 即(批量大小/样本数, 28, 28, 1)
3.因此此处使用解码器模型Model(decoder_input, x)的实例对象decoder 进行predict预测:
#将批量解码为数字图像。z_sample的形状为(16, 2),batch_size为16,z_sample代表(批量大小, 2),指的是(batch_size,latent_dim)
x_decoded = decoder.predict(z_sample, batch_size=batch_size)
#将批量第一个数字的形状从 28×28×1 转变为 28×28
digit = x_decoded[0].reshape(digit_size, digit_size)

>>> np.linspace(0.05, 0.95, n)
array([0.05 , 0.11428571, 0.17857143, 0.24285714, 0.30714286,
0.37142857, 0.43571429, 0.5 , 0.56428571, 0.62857143,
0.69285714, 0.75714286, 0.82142857, 0.88571429, 0.95 ])
>>> np.linspace(0.05, 0.95, n).shape
(15,)
>>> figure.shape
(420, 420)
>>> grid_x.shape
(15,)
>>> grid_y.shape
(15,)
>>> figure
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
# grid_x 和 grid_y 值都相同
>>> grid_x
array([-1.64485363e+00, -1.20404696e+00, -9.20822976e-01, -6.97141435e-01,
-5.03965367e-01, -3.28072108e-01, -1.61844167e-01, -1.39145821e-16,
1.61844167e-01, 3.28072108e-01, 5.03965367e-01, 6.97141435e-01,
9.20822976e-01, 1.20404696e+00, 1.64485363e+00])
>>> grid_y
array([-1.64485363e+00, -1.20404696e+00, -9.20822976e-01, -6.97141435e-01,
-5.03965367e-01, -3.28072108e-01, -1.61844167e-01, -1.39145821e-16,
1.61844167e-01, 3.28072108e-01, 5.03965367e-01, 6.97141435e-01,
9.20822976e-01, 1.20404696e+00, 1.64485363e+00])
#负责生成输出每行图像
for i, yi in enumerate(grid_x):
#负责生成输出每列图像
for j, xi in enumerate(grid_y):
z_sample = np.array([[xi, yi]])
z_sample.shape # (1, 2)
z_sample = np.tile(z_sample, batch_size).reshape(batch_size, 2)
z_sample.shape # (16, 2)
z_sample的值为:
array([[grid_x[i], grid_y[j]],
.......
[grid_x[i], grid_y[j]]])


